
Access Denied You don’t have permission to access “http://zeenews.india.com/technology/iphone-lockdown-mode-apple-says-no-ipad-mac-or-other-devices-can-be-hacked-with-this-feature-how-to-turn-it-on-3031664.html” on this server. Reference #18.c4f43717.1774794479.961490d6 https://errors.edgesuite.net/18.c4f43717.1774794479.961490d6
Access Denied
Access Denied You don’t have permission to access “http://zeenews.india.com/technology/redmi-15a-5g-vs-iqoo-z11x-5g-display-camera-battery-and-price-compared-which-smartphone-is-best-in-rs-20000-segment-3031546.html” on this server. Reference #18.c4f43717.1774774096.92ce3c89 https://errors.edgesuite.net/18.c4f43717.1774774096.92ce3c89
Access Denied
Access Denied You don’t have permission to access “http://zeenews.india.com/technology/redmi-15a-5g-launched-in-india-with-32mp-ai-dual-rear-camera-and-ai-features-check-camera-battery-display-price-and-sale-date-3031243.html” on this server. Reference #18.54fdd417.1774741742.2751dbe7 https://errors.edgesuite.net/18.54fdd417.1774741742.2751dbe7
Access Denied
Access Denied You don’t have permission to access “http://zeenews.india.com/technology/apple-iphone-real-or-fake-check-imei-number-and-7-easy-ways-to-verify-your-device-3031286.html” on this server. Reference #18.eff43717.1774728469.5f8db167 https://errors.edgesuite.net/18.eff43717.1774728469.5f8db167
Access Denied
Access Denied You don’t have permission to access “http://zeenews.india.com/technology/oneplus-nord-6-price-in-india-leaked-ahead-of-april-7-launch-check-expected-camera-display-battery-price-and-other-specs-3031318.html” on this server. Reference #18.c4f43717.1774714789.8c291918 https://errors.edgesuite.net/18.c4f43717.1774714789.8c291918
Access Denied
Access Denied You don’t have permission to access “http://zeenews.india.com/technology/oppo-pad-5-review-2026-2-8k-display-ai-features-massive-battery-and-best-mid-range-tablet-for-students-and-professionals-check-pros-and-cons-3031383.html” on this server. Reference #18.c4f43717.1774706076.88e4c80c https://errors.edgesuite.net/18.c4f43717.1774706076.88e4c80c
Access Denied
Access Denied You don’t have permission to access “http://zeenews.india.com/technology/ipl-2026-how-ball-tracking-lbw-and-ultraedge-work-in-matches-the-tech-behind-every-accurate-decision-3031320.html” on this server. Reference #18.d61cc517.1774685886.1cc4c06e https://errors.edgesuite.net/18.d61cc517.1774685886.1cc4c06e
7 Steps to Mastering Memory in Agentic AI Systems
In this article, you will learn how to design, implement, and evaluate memory systems that make agentic AI applications more reliable, personalized, and effective over time. Topics we will cover include: Why memory should be treated as a systems design problem rather than just a larger-context-model problem. The main memory types used in agentic systems and how they map to practical architecture choices. How to retrieve, manage, and evaluate memory in production without polluting the context window. Let’s not waste any more time. 7 Steps to Mastering Memory in Agentic AI SystemsImage by Editor Introduction Memory is one of the most overlooked parts of agentic system design. Without memory, every agent run starts from zero — with no knowledge of prior sessions, no recollection of user preferences, and no awareness of what was tried and failed an hour ago. For simple single-turn tasks, this is fine, but for agents running and coordinating multi-step workflows, or serving users repeatedly over time, statelessness becomes a hard ceiling on what the system can actually do. Memory lets agents accumulate context across sessions, personalize responses over time, avoid repeating work, and build on prior outcomes rather than starting fresh every time. The challenge is that agent memory isn’t a single thing. Most production agents need short-term context for coherent conversation, long-term storage for learned preferences, and retrieval mechanisms for surfacing relevant memories. This article covers seven practical steps for implementing effective memory in agentic systems. It explains how to understand the memory types your architecture needs, choose the right storage backends, write and retrieve memories correctly, and evaluate your memory layer in production. Step 1: Understanding Why Memory Is a Systems Problem Before touching any code, you need to reframe how you think about memory. The instinct for many developers is to assume that using a bigger model with a larger context window solves the problem. It doesn’t. Researchers and practitioners have documented what happens when you simply expand context: performance degrades under real workloads, retrieval becomes expensive, and costs compound. This phenomenon — sometimes called “context rot” — occurs because an enlarged context window filled indiscriminately with information hurts reasoning quality. The model spends its attention budget on noise rather than signal. Memory is fundamentally a systems architecture problem: deciding what to store, where to store it, when to retrieve it, and, more importantly, what to forget. None of those decisions can be delegated to the model itself without explicit design. IBM’s overview of AI agent memory makes an important point: unlike simple reflex agents, which don’t need memory at all, agents handling complex goal-oriented tasks require memory as a core architectural component, not an afterthought. The practical implication is to design your memory layer the way you’d design any production data system. Think about write paths, read paths, indexes, eviction policies, and consistency guarantees before writing a single line of agent code. Further reading: What Is AI Agent Memory? – IBM Think and What Is Agent Memory? A Guide to Enhancing AI Learning and Recall | MongoDB Step 2: Learning the AI Agent Memory Type Taxonomy Cognitive science gives us a vocabulary for the distinct roles memory plays in intelligent systems. Applied to AI agents, we can roughly identify four types, and each maps to a concrete architectural decision. Short-term or working memory is the context window — everything the model can actively reason over in a single inference call. It includes the system prompt, conversation history, tool outputs, and retrieved documents. Think of it like RAM: fast and immediate, but wiped when the session ends. It’s typically implemented as a rolling buffer or conversation history array, and it’s sufficient for simple single-session tasks but cannot survive across sessions. Episodic memory records specific past events, interactions, and outcomes. When an agent recalls that a user’s deployment failed last Tuesday due to a missing environment variable, that’s episodic memory at work. It’s particularly effective for case-based reasoning — using past events, actions, and outcomes to improve future decisions. Episodic memory is commonly stored as timestamped records in a vector database and retrieved via semantic or hybrid search at query time. Semantic memory holds structured factual knowledge: user preferences, domain facts, entity relationships, and general world knowledge relevant to the agent’s scope. A customer service agent that knows a user prefers concise answers and operates in the legal industry is drawing on semantic memory. This is often implemented as entity profiles updated incrementally over time, combining relational storage for structured fields with vector storage for fuzzy retrieval. Procedural memory encodes how to do things — workflows, decision rules, and learned behavioral patterns. In practice, this shows up as system prompt instructions, few-shot examples, or agent-managed rule sets that evolve through experience. A coding assistant that has learned to always check for dependency conflicts before suggesting library upgrades is expressing procedural memory. These memory types don’t operate in isolation. Capable production agents often need all of these layers working together. Further reading: Beyond Short-term Memory: The 3 Types of Long-term Memory AI Agents Need and Making Sense of Memory in AI Agents by Leonie Monigatti Step 3: Knowing the Difference Between Retrieval-Augmented Generation and Memory One of the most persistent sources of confusion for developers building agentic systems is conflating retrieval-augmented generation (RAG) with agent memory. ⚠️ RAG and agent memory solve related but distinct problems, and using the wrong one for the wrong job leads to agents that are either over-engineered or systematically blind to the right information. RAG is fundamentally a read-only retrieval mechanism. It grounds the model in external knowledge — your company’s documentation, a product catalog, legal policies — by finding relevant chunks at query time and injecting them into context. RAG is stateless: each query starts fresh, and it has no concept of who is asking or what they’ve said before. It’s the right tool for “what does our refund policy say?” and the wrong tool for “what did this specific customer tell us about their account last month?”

5 Practical Techniques to Detect and Mitigate LLM Hallucinations Beyond Prompt Engineering
5 Practical Techniques to Detect and Mitigate LLM Hallucinations Beyond Prompt Engineering – MachineLearningMastery.com 5 Practical Techniques to Detect and Mitigate LLM Hallucinations Beyond Prompt Engineering – MachineLearningMastery.com
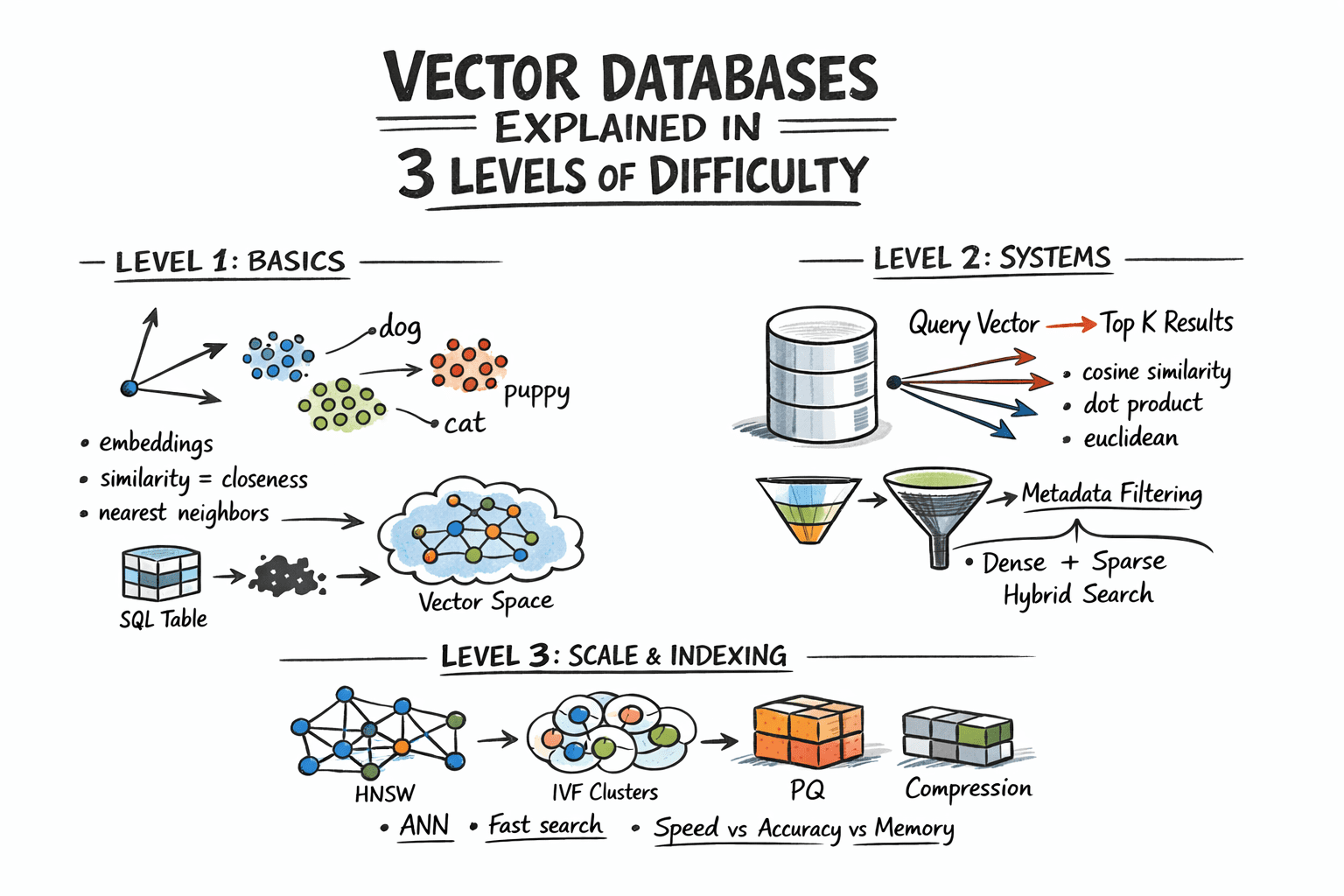
Vector Databases Explained in 3 Levels of Difficulty
In this article, you will learn how vector databases work, from the basic idea of similarity search to the indexing strategies that make large-scale retrieval practical. Topics we will cover include: How embeddings turn unstructured data into vectors that can be searched by similarity. How vector databases support nearest neighbor search, metadata filtering, and hybrid retrieval. How indexing techniques such as HNSW, IVF, and PQ help vector search scale in production. Let’s not waste any more time. Vector Databases Explained in 3 Levels of DifficultyImage by Author Introduction Traditional databases answer a well-defined question: does the record matching these criteria exist? Vector databases answer a different one: which records are most similar to this? This shift matters because a huge class of modern data — documents, images, user behavior, audio — cannot be searched by exact match. So the right query is not “find this,” but “find what is close to this.” Embedding models make this possible by converting raw content into vectors, where geometric proximity corresponds to semantic similarity. The problem, however, is scale. Comparing a query vector against every stored vector means billions of floating-point operations at production data sizes, and that math makes real-time search impractical. Vector databases solve this with approximate nearest neighbor algorithms that skip the vast majority of candidates and still return results nearly identical to an exhaustive search, at a fraction of the cost. This article explains how that works at three levels: the core similarity problem and what vectors enable, how production systems store and query embeddings with filtering and hybrid search, and finally the indexing algorithms and architecture decisions that make it all work at scale. Level 1: Understanding the Similarity Problem Traditional databases store structured data — rows, columns, integers, strings — and retrieve it with exact lookups or range queries. SQL is fast and precise for this. But a lot of real-world data is not structured. Text documents, images, audio, and user behavior logs do not fit neatly into columns, and “exact match” is the wrong query for them. The solution is to represent this data as vectors: fixed-length arrays of floating-point numbers. An embedding model like OpenAI’s text-embedding-3-small, or a vision model for images, converts raw content into a vector that captures its semantic meaning. Similar content produces similar vectors. For example, the word “dog” and the word “puppy” end up geometrically close in vector space. A photo of a cat and a drawing of a cat also end up close. A vector database stores these embeddings and lets you search by similarity: “find me the 10 vectors closest to this query vector.” This is called nearest neighbor search. Level 2: Storing and Querying Vectors Embeddings Before a vector database can do anything, content needs to be converted into vectors. This is done by embedding models — neural networks that map input into a dense vector space, typically with 256 to 4096 dimensions depending on the model. The specific numbers in the vector do not have direct interpretations; what matters is the geometry: close vectors mean similar content. You call an embedding API or run a model yourself, get back an array of floats, and store that array alongside your document metadata. Distance Metrics Similarity is measured as geometric distance between vectors. Three metrics are common: Cosine similarity measures the angle between two vectors, ignoring magnitude. It is often used for text embeddings, where direction matters more than length. Euclidean distance measures straight-line distance in vector space. It is useful when magnitude carries meaning. Dot product is fast and works well when vectors are normalized. Many embedding models are trained to use it. The choice of metric should match how your embedding model was trained. Using the wrong metric degrades result quality. The Nearest Neighbor Problem Finding exact nearest neighbors is trivial in small datasets: compute the distance from the query to every vector, sort the results, and return the top K. This is called brute-force or flat search, and it is 100% accurate. It also scales linearly with dataset size. At 10 million vectors with 1536 dimensions each, a flat search is too slow for real-time queries. The solution is approximate nearest neighbor (ANN) algorithms. These trade a small amount of accuracy for large gains in speed. Production vector databases run ANN algorithms under the hood. The specific algorithms, their parameters, and their tradeoffs are what we will examine in the next level. Metadata Filtering Pure vector search returns the most semantically similar items globally. In practice, you usually want something closer to: “find the most similar documents that belong to this user and were created after this date.” That is hybrid retrieval: vector similarity combined with attribute filters. Implementations vary. Pre-filtering applies the attribute filter first, then runs ANN on the remaining subset. Post-filtering runs ANN first, then filters the results. Pre-filtering is more accurate but more expensive for selective queries. Most production databases use some variant of pre-filtering with smart indexing to keep it fast. Hybrid Search: Dense + Sparse Pure dense vector search can miss keyword-level precision. A query for “GPT-5 release date” might semantically drift toward general AI topics rather than the specific document containing the exact phrase. Hybrid search combines dense ANN with sparse retrieval (BM25 or TF-IDF) to get semantic understanding and keyword precision together. The standard approach is to run dense and sparse search in parallel, then combine scores using reciprocal rank fusion (RRF) — a rank-based merging algorithm that does not require score normalization. Most production systems now support hybrid search natively. Level 3: Indexing for Scale Approximate Nearest Neighbor Algorithms The three most important approximate nearest neighbor algorithms each occupy a different point on the tradeoff surface between speed, memory usage, and recall. Hierarchical navigable small world (HNSW) builds a multi-layer graph where each vector is a node, with edges connecting similar neighbors. Higher layers are sparse and enable fast long-range traversal; lower layers are denser for precise local search. At query time, the algorithm hops through

