
Access Denied You don’t have permission to access “http://zeenews.india.com/technology/iphone-17-series-accounted-for-44-pc-of-apples-india-shipments-in-q2-2026-3062472.html” on this server. Reference #18.c4f43717.1784726804.76c430f8 https://errors.edgesuite.net/18.c4f43717.1784726804.76c430f8
Access Denied
Access Denied You don’t have permission to access “http://zeenews.india.com/technology/oneplus-to-exit-india-by-2027-us-and-europe-operations-to-shut-down-this-week-report-3061293.html” on this server. Reference #18.eff43717.1784196656.25fedeb0 https://errors.edgesuite.net/18.eff43717.1784196656.25fedeb0
Scikit-Ollama for Scikit-LLM/Ollama Integration – MachineLearningMastery.com
In this article, you will learn how scikit-ollama bridges the scikit-learn interface with locally running Ollama models to perform zero-shot text classification; no cloud API required. Topics we will cover include: What scikit-ollama is and how it relates to scikit-llm and the scikit-learn ecosystem. How to load a movie review sentiment dataset and instantiate a zero-shot classifier backed by a local Llama 3 model. How the fit/predict pattern works in the context of zero-shot LLM-driven classification, and what it actually does under the hood. Let’s not waste any more time. Introduction Large language model (LLM) integration into traditional machine learning workflows is not only possible nowadays, but also transforming the way we work with these models, in terms of both cost and security. Relying solely on commercial cloud APIs with quota and traffic bottlenecks — as well as data privacy concerns — is no longer the only go-to approach, and scikit-ollama has a lot to say on this. This library, largely based on scikit-llm, bridges the gap between the friendly scikit-learn syntax used to train and use classical machine learning models, and the power of LLMs — specifically free, locally installed models running on Ollama. This article explores how to set up this integration to build a highly practical zero-shot classifier for sentiment prediction on movie reviews, using a local Llama 3 model running on your machine. Step-by-Step Walkthrough First, since scikit-ollama is only compatible with Python 3.9 or higher, check the Python version currently installed in your local or virtual development environment; mine is a virtual environment set up inside Visual Studio Code: If you have Python 3.8 or lower, make sure you install or switch to a newer Python version before proceeding. Then install scikit-ollama: pip install scikit-ollama pip install scikit–ollama Once installed, we can begin coding. Scikit-LLM provides its own dataset catalog in its datasets module. We will use one of those text-based datasets, specifically one for sentiment classification of movie reviews. This is the code needed to load the data and display an example review alongside its associated sentiment label: from skllm.datasets import get_classification_dataset # Loading a demo sentiment analysis dataset containing movie reviews # The expected labels are: “positive”, “negative”, “neutral” X, y = get_classification_dataset() print(f”Sample text: {X[0]} \nLabel: {y[0]}”) from skllm.datasets import get_classification_dataset # Loading a demo sentiment analysis dataset containing movie reviews # The expected labels are: “positive”, “negative”, “neutral” X, y = get_classification_dataset() print(f“Sample text: {X[0]} \nLabel: {y[0]}”) Output: Sample text: I was absolutely blown away by the performances in ‘Summer’s End’. The acting was top-notch, and the plot had me gripped from start to finish. A truly captivating cinematic experience that I would highly recommend. Label: positive Sample text: I was absolutely blown away by the performances in ‘Summer’s End‘. The acting was top–notch, and the plot had me gripped from start to finish. A truly captivating cinematic experience that I would highly recommend. Label: positive Now for scikit-ollama itself. You will need to have Ollama locally installed on your machine. Follow the instructions in this article to do so, and make sure you install the model you want to use for this guide. To pull a model, run the following command in your terminal: The code below imports scikit-ollama’s ZeroShotOllamaClassifier class to instantiate a compatible sentiment classifier backed by a local Ollama model — llama3:latest. Make sure you have this model installed on your machine before continuing: from skollama.models.ollama.classification.zero_shot import ZeroShotOllamaClassifier # Initializing the classifier with our local Ollama model: llama3:latest clf = ZeroShotOllamaClassifier(model=”llama3:latest”) from skollama.models.ollama.classification.zero_shot import ZeroShotOllamaClassifier # Initializing the classifier with our local Ollama model: llama3:latest clf = ZeroShotOllamaClassifier(model=“llama3:latest”) A very important clarification about what we just did. llama3:latest is a general-purpose LLM, originally built to do much more than classify text: you can chat with it, brainstorm ideas, and more. So why are we using it to instantiate a zero-shot classifier? By doing so, scikit-ollama — along with scikit-llm under the hood — reformulates our intended classification task into a text-generation prompt that is syntactically constrained, so that the local model outputs only what is needed, acting as a classical machine learning model would in terms of output format, while still applying the powerful language-based reasoning it was built for. This is the core of scikit-ollama and scikit-llm’s value: bridging the power of LLMs with the simplicity of the scikit-learn interface for predictive tasks like classification. Time to apply the traditional machine learning two-stage ritual: fit and predict. While fitting a model normally involves updating weights on a labeled dataset, in the context of zero-shot LLM-driven classification there is no actual weight updating. The fit() call is used solely to register the candidate classification labels, guiding the model for in-context learning: # “Fitting” the model boils down to just providing the list of candidate labels clf.fit(None, [“positive”, “negative”, “neutral”]) # “Fitting” the model boils down to just providing the list of candidate labels clf.fit(None, [“positive”, “negative”, “neutral”]) When calling the predict() method and passing a set of text reviews, the local Ollama instance processes each input as a prompt and parses the output to ensure it maps to one of the zero-shot classification labels, all under the hood. The code below generates predictions on the dataset and prints the first three results. Note that on the first run, a short loading delay is expected while the model initializes, accompanied by a progress bar: # Generating and showing predictions on our dataset predictions = clf.predict(X) for text, prediction in zip(X[:3], predictions[:3]): print(f”Text: ‘{text}’”) print(f”Predicted Sentiment: {prediction}\n”) # Generating and showing predictions on our dataset predictions = clf.predict(X) for text, prediction in zip(X[:3], predictions[:3]): print(f“Text: ‘{text}’”) print(f“Predicted Sentiment: {prediction}\n”) Output: Text: ‘I was absolutely blown away by the performances in ‘Summer’s End’. The acting was top-notch, and the plot had me gripped from start to finish. A truly captivating cinematic experience that I would highly recommend.’ Predicted Sentiment: positive Text: ‘The special effects in ‘Star Battles: Nebula Conflict’
Access Denied
Access Denied You don’t have permission to access “http://zeenews.india.com/technology/how-are-companies-using-ai-in-hiring-performance-reviews-and-layoffs-3061110.html” on this server. Reference #18.c4f43717.1784117531.3302c54e https://errors.edgesuite.net/18.c4f43717.1784117531.3302c54e
Access Denied
Access Denied You don’t have permission to access “http://zeenews.india.com/technology/samsung-sk-hynix-micron-ramp-up-capacity-as-demand-for-ai-infrastructure-outpaces-supply-3060821.html” on this server. Reference #18.eff43717.1783952698.17818094 https://errors.edgesuite.net/18.eff43717.1783952698.17818094
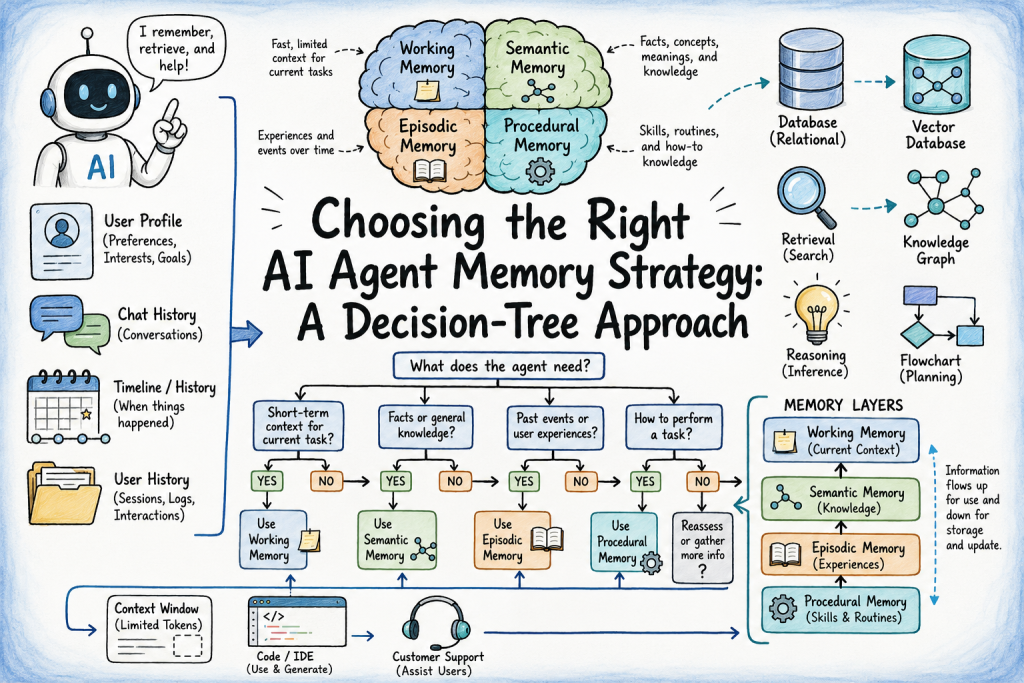
Choosing the Right AI Agent Memory Strategy: A Decision-Tree Approach
In this article, you will learn how to choose the right memory strategy for an AI agent by working through a simple decision tree, one category of information at a time. Topics we will cover include: The four types of agent memory — working, semantic, episodic, and procedural — and what each one assumes about the information it holds. A five-question decision tree that classifies what a given category of information actually needs, and how those answers combine into a full memory architecture. The common pitfalls that show up once agent memory is implemented, and how to fix them. Let’s get started. Introduction Memory is one of the defining capabilities of an AI agent, yet it’s often designed as an afterthought. Some agents forget information users expect them to remember, while others are given complex memory infrastructure they never really need. Both often stem from the same unanswered design question: how long should different kinds of information live, and how should they be retrieved? Agent memory strategy deserves the same deliberate design as orchestration. Unlike orchestration patterns, however, agent memory is rarely a single architectural choice. The current conversation, a user’s stated preferences, past interaction history, and learned routines are different categories of information, and each tends to need a different kind of memory. Choosing a memory system for an agent matters less than deciding where each category of information should live. This article covers: The core memory concepts that separate working, semantic, episodic, and procedural memory A five-question decision tree for classifying what a given category of information needs How those classifications combine into the layered memory setups agents actually ship with The pitfalls that show up once memory gets implemented and used We start with why this classification matters in the first place. Why Is Choosing an AI Agent Memory Strategy Important? Before working through the decision tree, it’s worth being clear about what each memory layer assumes about the information assigned to it. Working memory rests on the idea that everything relevant right now lives inside the active conversation and a finite token budget, and that trimming or summarizing older turns won’t quietly drop something the agent still needs. Semantic memory assumes that certain information is sufficiently stable and reusable that storing a canonical representation is more valuable than repeatedly inferring, re-asking, or reprocessing it. This includes persistent user facts such as name, role, and preferred language; domain knowledge such as business rules and product specifications; and generalized knowledge distilled from repeated interactions. Episodic memory is built on the expectation that the history of what happened carries value on its own, not just the current state: a record of past decisions, complaints, or transactions that should inform the next interaction. Procedural memory presumes that solving the same shape of task repeatedly should make the agent faster or more reliable on the next attempt, not just leave behind a transcript of past attempts. These four layers answer different questions about information, which is why most production agents rely on more than one. A customer support agent, for example, might keep the current ticket in working memory, a customer’s subscription tier in semantic memory, past complaints in episodic memory, and a learned refund-handling routine in procedural memory. Each layer serves a distinct purpose. Problems arise when information is stored in the wrong layer. Using a vector store for stable facts that belong in a structured profile makes retrieval slower and less reliable, while searching an entire interaction history can surface stale or contradictory information that a structured record would have overwritten. For effective context engineering, memory is just one source of context competing for a limited context window, so information should only be retrieved if it meaningfully improves the agent’s response. The Decision Tree for Choosing the Right AI Agent Memory Strategy The tree has five branching questions, each one narrowing down what a specific category of information needs based on a concrete property of it. Run the tree once per category, not once for the whole agent. A support agent’s “current ticket,” “account details,” and “complaint history” are three separate categories, and each one can land in a different place on the tree. Question 1: Does This Information Need to Persist Beyond the Current Turn? This question separates information that genuinely needs memory from information that just looks like it does. Self-contained, no carry-forward needed: the wording of a one-off classification request, the intermediate output of a tool call used only to answer the current question Carries forward, memory required: which issue a support agent already resolved this conversation, the state of a coding project an agent is picking back up from yesterday If the information is self-contained → no memory layer is needed; the context window for that turn is enough. If it needs to carry forward → move to Question 2. Question 2: Does It Need to Survive Beyond a Single Session? This question separates working memory from anything that needs to be durable. Within-session only: what’s already been asked, which tools have already been called, what’s already resolved → a conversation buffer is enough, kept in bounds by trimming or summarization. Session-based memory management in the OpenAI Agents SDK handles this directly. Beyond the session: a returning customer’s preferences, an ongoing project’s state, a multi-day task → working memory alone won’t do it, since the information has to exist independently of any single conversation. If only within-session continuity matters → working memory is the answer for this category. If it needs to outlive the session → move to Question 3. ⚠️ A common design mistake is mismatching information to its lifetime, either treating session-scoped state as permanent or building persistent memory infrastructure for information that only needs to exist during a conversation. Question 3: Is This a Stable Fact or an Evolving Event? This question is often skipped, with everything that needs to persist getting thrown into the same store regardless of shape. Stable facts (semantic memory): a name, a subscription tier, a preferred
Access Denied
Access Denied You don’t have permission to access “http://zeenews.india.com/technology/whatsapp-just-got-smarter-meta-launches-ai-business-agent-in-india-here-s-how-it-works-3059886.html” on this server. Reference #18.eff43717.1783487355.36f9171e https://errors.edgesuite.net/18.eff43717.1783487355.36f9171e
Building Effective AI Agents Without Over-Engineering
In this article, you will learn how to decide whether a given piece of agent functionality should be built as a tool or as a subagent, and how to avoid overengineering your agent architecture in the process. Topics we will cover include: What tools and subagents are, and the key differences between them. When a tool is the better choice, and when a subagent is worth the added complexity. How to apply a simple three-question decision framework, and what adding subagents actually costs. With that framing in place, let’s look at how each piece fits together. Introduction Every AI agent you build reaches the same decision point eventually. You have a task that needs to be done — call an API, search a database, run a calculation — and you need to decide: should this be a tool the agent calls directly, or should it be a separate agent that handles the work independently? Get this wrong in one direction and you end up with a bloated agent that tries to do too much in a single context window. Get it wrong in the other direction and you’ve added coordination overhead, extra LLM calls, and debugging complexity to a problem that a simple function would have solved. This article explains what tools and subagents are, where each fits, and how to make the choice every time. What Tools Are A tool is a capability an agent uses to interact with external systems and perform actions beyond the model’s built-in knowledge. In practice, tools are usually functions, API calls, database queries, searches, file operations, or other executable code exposed to the model through a defined interface. A typical tool interaction looks like this: The model receives a task and determines that external information or an action is needed. The model generates a structured tool call with the required arguments. Your application executes the tool and returns a result. The result is added back into the conversation, allowing the model to continue reasoning and decide what to do next. The important distinction is that tools do not perform reasoning themselves. They execute predefined operations and return data. The model handles the planning, interpretation, and decision-making around those operations. Tools are the primary way agents interact with the outside world. They can query a database, call an API, search the web, read files, run calculations, or trigger workflows. Because tools execute code rather than running another LLM, they are typically fast, deterministic, and inexpensive compared to spawning a subagent. What Subagents Are A subagent is a separate LLM call — typically a distinct agent instance with its own system prompt, its own context window, and often its own set of tools — that receives a task, works through it independently, and returns a result to the orchestrating agent. From the orchestrator’s perspective, calling a subagent looks identical to calling a tool: send a task, get a result. The difference is what happens in between. A subagent runs its own multi-step reasoning loop, potentially makes its own tool calls, and manages its own state. The orchestrator has no visibility into that process; it only gets the summary at the end. Tools vs Subagents Tools vs Subagents: The Key Differences Tools execute code. Subagents execute reasoning. Aspect Tools Subagents What runs Your code Another LLM Context window Shared with the orchestrator Separate, isolated Reasoning None; deterministic execution Full multi-step reasoning loop Error handling Structured returns, retry in same loop Subagent handles internally or surfaces to orchestrator Cost Execution cost only Additional LLM call(s) Latency Low; one function call Higher; full inference cycle Visibility Full; result in orchestrator’s context Partial; orchestrator sees summary only When it breaks Bad schema, API failure, wrong arguments Hallucination in subagent, lost context, coordination failure The context window distinction matters more than it first appears. When an agent calls a tool, the result lands back in the same context the agent is actively reasoning in — prior reasoning, tool result, and everything else together. When an orchestrator spawns a subagent, that subagent starts fresh with only what the orchestrator passed it. When to Use a Tool Use a tool when the operation is well-defined, has deterministic behavior, and does not require multi-step reasoning to complete. Call an external API. Tasks like fetching a user record, posting to Slack, or querying a database are pure execution tasks. The model decides to call them; your code runs them. Transform or validate data. Running a regex, formatting a date, calculating a hash, or converting units. Deterministic operations belong in functions, not in LLM calls. Read or write files. Opening a file, writing output, checking if something exists. File system operations are predictable and fast when implemented as direct tool calls. Run a search. Semantic search over a vector database, a SQL query against a database, a web search. The search itself runs deterministically and returns results. The model interprets those results, but the search runs as a tool. The practical test: if you can write the behavior as a Python function with typed inputs and outputs, and it doesn’t need to reason through multiple steps, it should be a tool. When to Use a Subagent Use a subagent when the task requires multi-step reasoning, when the intermediate work would create noise in the orchestrator’s context, or when tasks can run in parallel. The task has non-obvious intermediate steps. “Research the competitive landscape for X” involves deciding what to search, reading results, deciding what to search next, synthesizing across sources, and producing a structured summary. Each step depends on the previous one. That’s a reasoning process, and it belongs in its own context. The work can be parallelized. Processing k documents independently runs faster across k concurrent subagents than sequentially in one context. Microsoft’s AutoGen framework is built partly around this pattern, coordinating specialized agents that work in parallel on independent subtasks. The subtask needs its own tool set. A code-writing subagent needs a code executor and file system tools. A research subagent needs
Access Denied
Access Denied You don’t have permission to access “http://zeenews.india.com/technology/xiaomi-17t-leica-tuned-cameras-6700mah-battery-but-does-it-justify-the-price-all-you-need-to-know-3059724.html” on this server. Reference #18.c4f43717.1783418447.52b48a72 https://errors.edgesuite.net/18.c4f43717.1783418447.52b48a72
Access Denied
Access Denied You don’t have permission to access “http://zeenews.india.com/technology/samsung-to-hike-foldable-phone-price-amid-ai-chip-shortage-3059727.html” on this server. Reference #18.c4f43717.1783413486.5220bb6d https://errors.edgesuite.net/18.c4f43717.1783413486.5220bb6d

