
Access Denied You don’t have permission to access “http://zeenews.india.com/technology/us-new-ai-policy-push-signals-shift-for-india-3029094.html” on this server. Reference #18.eff43717.1774106642.33bde079 https://errors.edgesuite.net/18.eff43717.1774106642.33bde079
Access Denied
Access Denied You don’t have permission to access “http://zeenews.india.com/technology/how-to-charge-your-phone-using-laptop-without-charger-is-it-safe-for-battery-speed-and-performance-3028985.html” on this server. Reference #18.5cfdd417.1774090103.11c403d7 https://errors.edgesuite.net/18.5cfdd417.1774090103.11c403d7
Access Denied
Access Denied You don’t have permission to access “http://zeenews.india.com/technology/no-more-language-barriers-whatsapp-to-offer-auto-translate-message-feature-in-21-languages-for-iphone-users-3028960.html” on this server. Reference #18.c4f43717.1774085312.48652ad4 https://errors.edgesuite.net/18.c4f43717.1774085312.48652ad4
Access Denied
Access Denied You don’t have permission to access “http://zeenews.india.com/technology/samsung-galaxy-s25-ultra-gets-massive-price-cut-in-india-after-galaxy-s26-series-launch-check-specs-and-other-features-3028926.html” on this server. Reference #18.eff43717.1774080123.3154d31a https://errors.edgesuite.net/18.eff43717.1774080123.3154d31a
Access Denied
Access Denied You don’t have permission to access “http://zeenews.india.com/technology/elon-musk-held-liable-for-misleading-twitter-shareholders-in-2022-takeover-bid-3028929.html” on this server. Reference #18.eff43717.1774076142.3107d7fd https://errors.edgesuite.net/18.eff43717.1774076142.3107d7fd
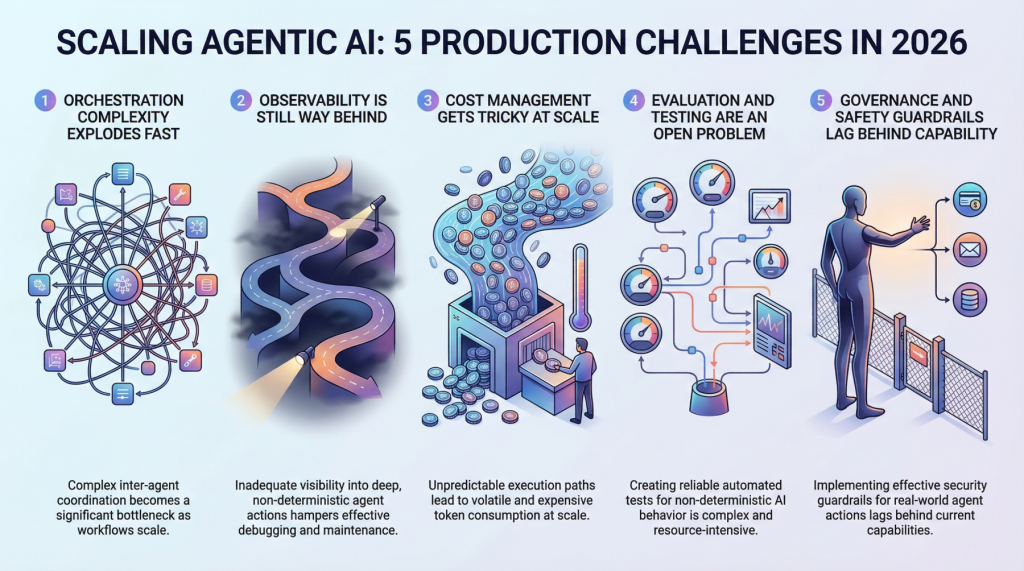
5 Production Scaling Challenges for Agentic AI in 2026
In this article, you will learn about five major challenges teams face when scaling agentic AI systems from prototype to production in 2026. Topics we will cover include: Why orchestration complexity grows rapidly in multi-agent systems. How observability, evaluation, and cost control remain difficult in production environments. Why governance and safety guardrails are becoming essential as agentic systems take real-world actions. Let’s not waste any more time. 5 Production Scaling Challenges for Agentic AI in 2026Image by Editor Introduction Everyone’s building agentic AI systems right now, for better or for worse. The demos look incredible, the prototypes feel magical, and the pitch decks practically write themselves. But here’s what nobody’s tweeting about: getting these things to actually work at scale, in production, with real users and real stakes, is a completely different game. The gap between a slick demo and a reliable production system has always existed in machine learning, but agentic AI stretches it wider than anything we’ve seen before. These systems make decisions, take actions, and chain together complex workflows autonomously. That’s powerful, and it’s also terrifying when things go sideways at scale. So let’s talk about the five biggest headaches teams are running into as they try to scale agentic AI in 2026. 1. Orchestration Complexity Explodes Fast When you’ve got a single agent handling a narrow task, orchestration feels manageable. You define a workflow, set some guardrails, and things mostly behave. But production systems rarely stay that simple. The moment you introduce multi-agent architectures in which agents delegate to other agents, retry failed steps, or dynamically choose which tools to call, you’re dealing with orchestration complexity that grows almost exponentially. Teams are finding that the coordination overhead between agents becomes the bottleneck, not the individual model calls. You’ve got agents waiting on other agents, race conditions popping up in async pipelines, and cascading failures that are genuinely hard to reproduce in staging environments. Traditional workflow engines weren’t designed for this level of dynamic decision-making, and most teams end up building custom orchestration layers that quickly become the hardest part of the entire stack to maintain. The real kicker is that these systems behave differently under load. An orchestration pattern that works beautifully at 100 requests per minute can completely fall apart at 10,000. Debugging that gap requires a kind of systems thinking that most machine learning teams are still developing. 2. Observability Is Still Way Behind You can’t fix what you can’t see, and right now, most teams can’t see nearly enough of what their agentic systems are doing in production. Traditional machine learning monitoring tracks things like latency, throughput, and model accuracy. Those metrics still matter, but they barely scratch the surface of agentic workflows. When an agent takes a 12-step journey to answer a user query, you need to understand every decision point along the way. Why did it choose Tool A over Tool B? Why did it retry step 4 three times? Why did the final output completely miss the mark, despite every intermediate step looking fine? The tracing infrastructure for this kind of deep observability is still immature. Most teams cobble together some combination of LangSmith, custom logging, and a lot of hope. What makes it harder is that agentic behavior is non-deterministic by nature. The same input can produce wildly different execution paths, which means you can’t just snapshot a failure and replay it reliably. Building robust observability for systems that are inherently unpredictable remains one of the biggest unsolved problems in the space. 3. Cost Management Gets Tricky at Scale Here’s something that catches a lot of teams off guard: agentic systems are expensive to run. Each agent action typically involves one or more LLM calls, and when agents are chaining together dozens of steps per request, the token costs add up shockingly fast. A workflow that costs $0.15 per execution sounds fine until you’re processing 500,000 requests a day. Smart teams are getting creative with cost optimization. They’re routing simpler sub-tasks to smaller, cheaper models while reserving the heavy hitters for complex reasoning steps. They’re caching intermediate results aggressively and building kill switches that terminate runaway agent loops before they burn through budget. But there’s a constant tension between cost efficiency and output quality, and finding the right balance requires ongoing experimentation. The billing unpredictability is what really stresses out engineering leads. Unlike traditional APIs, where you can estimate costs pretty accurately, agentic systems have variable execution paths that make cost forecasting genuinely difficult. One edge case can trigger a chain of retries that costs 50 times more than the normal path. 4. Evaluation and Testing Are an Open Problem How do you test a system that can take a different path every time it runs? That’s the question keeping machine learning engineers up at night. Traditional software testing assumes deterministic behavior, and traditional machine learning evaluation assumes a fixed input-output mapping. Agentic AI breaks both assumptions simultaneously. Teams are experimenting with a range of approaches. Some are building LLM-as-a-judge pipelines in which a separate model evaluates the agent’s outputs. Others are creating scenario-based test suites that check for behavioral properties rather than exact outputs. A few are investing in simulation environments where agents can be stress-tested against thousands of synthetic scenarios before hitting production. But none of these approaches feels truly mature yet. The evaluation tooling is fragmented, benchmarks are inconsistent, and there’s no industry consensus on what “good” even looks like for a complex agentic workflow. Most teams end up relying heavily on human review, which obviously doesn’t scale. 5. Governance and Safety Guardrails Lag Behind Capability Agentic AI systems can take real actions in the real world. They can send emails, modify databases, execute transactions, and interact with external services. The safety implications of that autonomy are significant, and governance frameworks haven’t kept pace with how quickly these capabilities are being deployed. The challenge is implementing guardrails that are robust enough to prevent harmful actions without being so restrictive that they kill the usefulness of
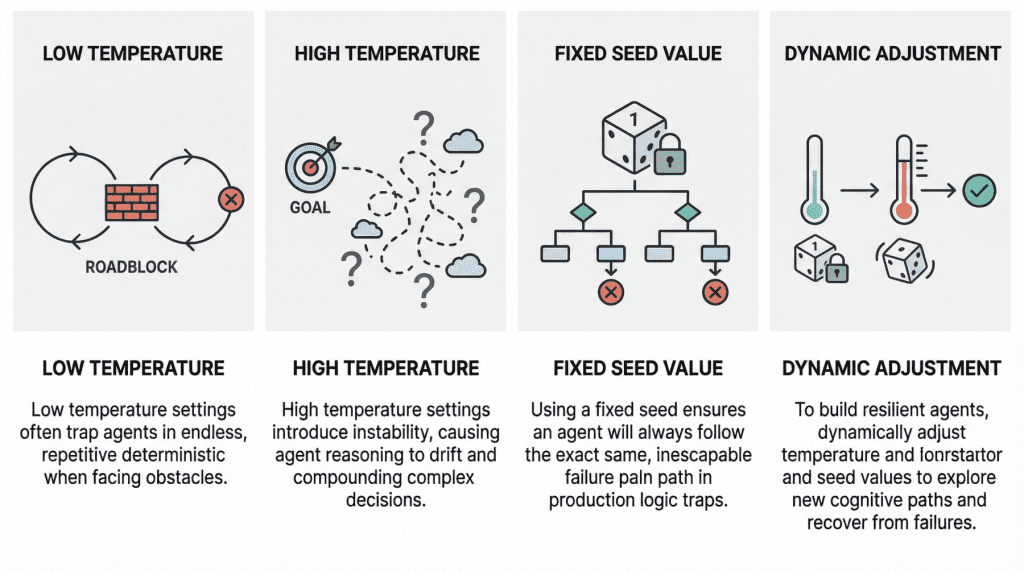
Why Agents Fail: The Role of Seed Values and Temperature in Agentic Loops
In this article, you will learn how temperature and seed values influence failure modes in agentic loops, and how to tune them for greater resilience. Topics we will cover include: How low and high temperature settings can produce distinct failure patterns in agentic loops. Why fixed seed values can undermine robustness in production environments. How to use temperature and seed adjustments to build more resilient and cost-effective agent workflows. Let’s not waste any more time. Why Agents Fail: The Role of Seed Values and Temperature in Agentic LoopsImage by Editor Introduction In the modern AI landscape, an agent loop is a cyclic, repeatable, and continuous process whereby an entity called an AI agent — with a certain degree of autonomy — works toward a goal. In practice, agent loops now wrap a large language model (LLM) inside them so that, instead of reacting only to single-user prompt interactions, they implement a variation of the Observe-Reason-Act cycle defined for classic software agents decades ago. Agents are, of course, not infallible, and they may sometimes fail, in some cases due to poor prompting or a lack of access to the external tools they need to reach a goal. However, two invisible steering mechanisms can also influence failure: temperature and seed value. This article analyzes both from the perspective of failure in agent loops. Let’s take a closer look at how these settings may relate to failure in agentic loops through a gentle discussion backed by recent research and production diagnoses. Temperature: “Reasoning Drift” Vs. “Deterministic Loop” Temperature is an inherent parameter of LLMs, and it controls randomness in their internal behavior when selecting the words, or tokens, that make up the model’s response. The higher its value (closer to 1, assuming a range between 0 and 1), the less deterministic and more unpredictable the model’s outputs become, and vice versa. In agentic loops, because LLMs sit at the core, understanding temperature is crucial to understanding unique, well-documented failure modes that may arise, particularly when the temperature is extremely low or high. A low-temperature (near 0) agent often yields the so-called deterministic loop failure. In other words, the agent’s behavior becomes too rigid. Suppose the agent comes across a “roadblock” on its path, such as a third-party API consistently returning an error. With a low temperature and exceedingly deterministic behavior, it lacks the kind of cognitive randomness or exploration needed to pivot. Recent studies have scientifically analyzed this phenomenon. The practical consequences typically observed range from agents finalizing missions prematurely to failing to coordinate when their initial plans encounter friction, thus ending up in loops of the same attempts over and over without any progress. At the opposite end of the spectrum, we have high-temperature (0.8 or above) agentic loops. As with standalone LLMs, high temperature introduces a much broader range of possibilities when sampling each element of the response. In a multi-step loop, however, this highly probabilistic behavior may compound in a dangerous way, turning into a trait known as reasoning drift. In essence, this behavior boils down to instability in decision-making. Introducing high-temperature randomness into complex agent workflows may cause agent-based models to lose their way — that is, lose their original selection criteria for making decisions. This may include symptoms such as hallucinations (fabricated reasoning chains) or even forgetting the user’s initial goal. Seed Value: Reproducibility Seed values are the mechanisms that initialize the pseudo-random generator used to build the model’s outputs. Put more simply, the seed value is like the starting position of a die that is rolled to kickstart the model’s word-selection mechanism governing response generation. Regarding this setting, the main problem that usually causes failure in agent loops is using a fixed seed in production. A fixed seed is reasonable in a testing environment, for example, for the sake of reproducibility in tests and experiments, but allowing it to make its way into production introduces a significant vulnerability. An agent may inadvertently enter a logic trap when it operates with a fixed seed. In such a situation, the system may automatically trigger a recovery attempt, but even then, the fixed seed is almost synonymous with guaranteeing that the agent will take the same reasoning path doomed to failure over and over again. In practical terms, imagine an agent tasked with debugging a failed deployment by inspecting logs, proposing a fix, and then retrying the operation. If the loop runs with a fixed seed, the stochastic choices made by the model during each reasoning step may remain effectively “locked” into the same pattern every time recovery is triggered. As a result, the agent may keep selecting the same flawed interpretation of the logs, calling the same tool in the same order, or generating the same ineffective fix despite repeated retries. What looks like persistence at the system level is, in reality, repetition at the cognitive level. This is why resilient agent architectures often treat the seed as a controllable recovery lever: when the system detects that the agent is stuck, changing the seed can help force exploration of a different reasoning trajectory, increasing the chances of escaping a local failure mode rather than reproducing it indefinitely. A summary of the role of seed values and temperature in agentic loopsImage by Editor Best Practices For Resilient And Cost-Effective Loops Having learned about the impact that temperature and seed value may have in agent loops, one might wonder how to make these loops more resilient to failure by carefully setting these two parameters. Basically, breaking out of failure in agentic loops often entails changing the seed value or temperature as part of retry efforts to seek a different cognitive path. Resilient agents usually implement approaches that dynamically adjust these parameters in edge cases, for instance by temporarily raising the temperature or randomizing the seed if an analysis of the agent’s state suggests it is stuck. The bad news is that this can become very expensive to test when commercial APIs are used, which is why open-weight models, local models,
Access Denied
Access Denied You don’t have permission to access “http://zeenews.india.com/technology/big-action-on-online-betting-as-govt-bans-300-more-illegal-gambling-apps-3028738.html” on this server. Reference #18.95a2dfad.1774013147.2daf2ac0 https://errors.edgesuite.net/18.95a2dfad.1774013147.2daf2ac0
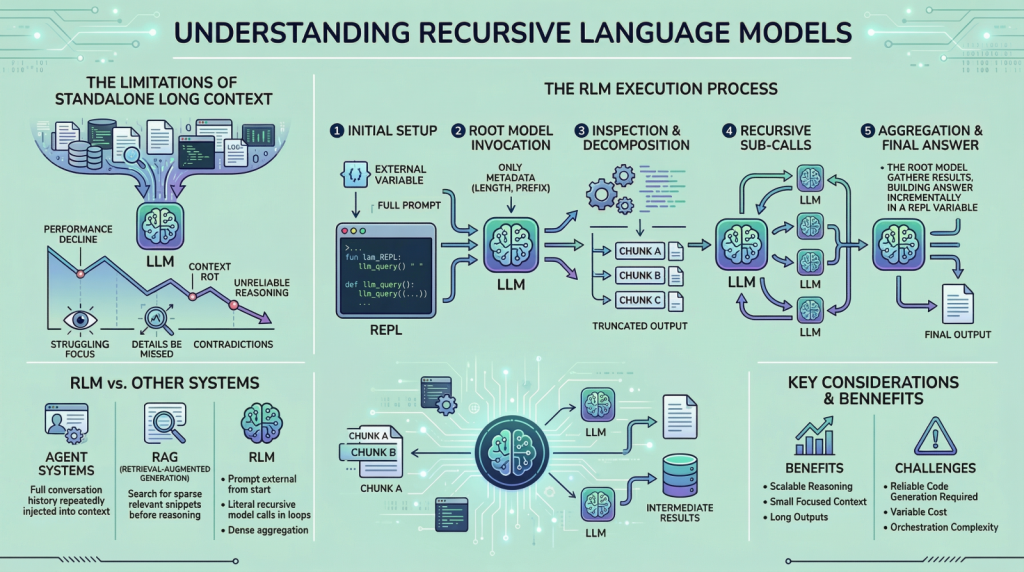
Everything You Need to Know About Recursive Language Models
In this article, you will learn what recursive language models are, why they matter for long-input reasoning, and how they differ from standard long-context prompting, retrieval, and agentic systems. Topics we will cover include: Why long context alone does not solve reasoning over very large inputs How recursive language models use an external runtime and recursive sub-calls to process information The main tradeoffs, limitations, and practical use cases of this approach Let’s get right to it. Everything You Need to Know About Recursive Language ModelsImage by Editor Introduction If you are here, you have probably heard about recent work on recursive language models. The idea has been trending across LinkedIn and X, and it led me to study the topic more deeply and share what I learned with you. I think we can all agree that large language models (LLMs) have improved rapidly over the past few years, especially in their ability to handle large inputs. This progress has led many people to assume that long context is largely a solved problem, but it is not. If you have tried giving models very long inputs close to, or equal to, their context window, you might have noticed that they become less reliable. They often miss details present in the provided information, contradict earlier statements, or produce shallow answers instead of doing careful reasoning. This issue is often referred to as “context rot”, which is quite an interesting name. Recursive language models (RLMs) are a response to this problem. Instead of pushing more and more text into a single forward pass of a language model, RLMs change how the model interacts with long inputs in the first place. In this article, we will look at what they are, how they work, and the kinds of problems they are designed to solve. Why Long Context Is Not Enough You can skip this section if you already understand the motivation from the introduction. But if you are curious, or if the idea did not fully click the first time, let me break it down further. The way these LLMs work is fairly simple. Everything we want the model to consider is given to it as a single prompt, and based on that information, the model generates the output token by token. This works well when the prompt is short. However, when it becomes very long, performance starts to degrade. This is not necessarily due to memory limits. Even if the model can see the complete prompt, it often fails to use it effectively. Here are some reasons that may contribute to this behavior: These LLMs are mainly transformer-based models with an attention mechanism. As the prompt grows longer, attention becomes more diffuse. The model struggles to focus sharply on what matters when it has to attend to tens or hundreds of thousands of tokens. Another reason is the presence of heterogeneous information mixed together, such as logs, documents, code, chat history, and intermediate outputs. Lastly, many tasks are not just about retrieving or finding a relevant snippet in a huge body of content. They often involve aggregating information across the entire input. Because of the problems discussed above, people proposed ideas such as summarization and retrieval. These approaches do help in some cases, but they are not universal solutions. Summaries are lossy by design, and retrieval assumes that relevance can be identified reliably before reasoning begins. Many real-world tasks violate these assumptions. This is why RLMs suggest a different approach. Instead of forcing the model to absorb the entire prompt at once, they let the model actively explore and process the prompt. Now that we have the basic background, let us look more closely at how this works. How a Recursive Language Model Works in Practice In an RLM setup, the prompt is treated as part of the external environment. This means the model does not read the entire input directly. Instead, the input sits outside the model, often as a variable, and the model is given only metadata about the prompt along with instructions on how to access it. When the model needs information, it issues commands to examine specific parts of the prompt. This simple design keeps the model’s internal context small and focused, even when the underlying input is extremely large. To understand RLMs more concretely, let us walk through a typical execution step by step. Step 1: Initializing a Persistent REPL Environment At the beginning of an RLM run, the system initializes a runtime environment, typically a Python REPL. This environment contains: A variable holding the full user prompt, which may be arbitrarily large A function (for example, llm_query(…) or sub_RLM(…)) that allows the system to invoke additional language model calls on selected pieces of text From the user’s perspective, the interface remains simple, with a textual input and an output, but internally the REPL acts as scaffolding that enables scalable reasoning. Step 2: Invoking the Root Model with Prompt Metadata Only The root language model is then invoked, but it does not receive the full prompt. Instead, it is given: Constant-size metadata about the prompt, such as its length or a short prefix Instructions describing the task Access instructions for interacting with the prompt via the REPL environment By withholding the full prompt, the system forces the model to interact with the input intentionally, rather than passively absorbing it into the context window. From this point onward, the model interacts with the prompt indirectly. Step 3: Inspecting and Decomposing the Prompt via Code Execution The model might begin by inspecting the structure of the input. For example, it can print the first few lines, search for headings, or split the text into chunks based on delimiters. These operations are performed by generating code, which is then executed in the environment. The outputs of these operations are truncated before being shown to the model, ensuring that the context window is not overwhelmed. Step 4: Issuing Recursive Sub-Calls on Selected Slices Once the model understands the structure of the

7 Readability Features for Your Next Machine Learning Model
In this article, you will learn how to extract seven useful readability and text-complexity features from raw text using the Textstat Python library. Topics we will cover include: How Textstat can quantify readability and text complexity for downstream machine learning tasks. How to compute seven commonly used readability metrics in Python. How to interpret these metrics when using them as features for classification or regression models. Let’s not waste any more time. 7 Readability Features for Your Next Machine Learning ModelImage by Editor Introduction Unlike fully structured tabular data, preparing text data for machine learning models typically entails tasks like tokenization, embeddings, or sentiment analysis. While these are undoubtedly useful features, the structural complexity of text — or its readability, for that matter — can also constitute an incredibly informative feature for predictive tasks such as classification or regression. Textstat, as its name suggests, is a lightweight and intuitive Python library that can help you obtain statistics from raw text. Through readability scores, it provides input features for models that can help distinguish between a casual social media post, a children’s fairy tale, or a philosophy manuscript, to name a few. This article introduces seven insightful examples of text analysis that can be easily conducted using the Textstat library. Before we get started, make sure you have Textstat installed: While the analyses described here can be scaled up to a large text corpus, we will illustrate them with a toy dataset consisting of a small number of labeled texts. Bear in mind, however, that for downstream machine learning model training and inference, you will need a sufficiently large dataset for training purposes. import pandas as pd import textstat # Create a toy dataset with three markedly different texts data = { ‘Category’: [‘Simple’, ‘Standard’, ‘Complex’], ‘Text’: [ “The cat sat on the mat. It was a sunny day. The dog played outside.”, “Machine learning algorithms build a model based on sample data, known as training data, to make predictions.”, “The thermodynamic properties of the system dictate the spontaneous progression of the chemical reaction, contingent upon the activation energy threshold.” ] } df = pd.DataFrame(data) print(“Environment set up and dataset ready!”) import pandas as pd import textstat # Create a toy dataset with three markedly different texts data = { ‘Category’: [‘Simple’, ‘Standard’, ‘Complex’], ‘Text’: [ “The cat sat on the mat. It was a sunny day. The dog played outside.”, “Machine learning algorithms build a model based on sample data, known as training data, to make predictions.”, “The thermodynamic properties of the system dictate the spontaneous progression of the chemical reaction, contingent upon the activation energy threshold.” ] } df = pd.DataFrame(data) print(“Environment set up and dataset ready!”) 1. Applying the Flesch Reading Ease Formula The first text analysis metric we will explore is the Flesch Reading Ease formula, one of the earliest and most widely used metrics for quantifying text readability. It evaluates a text based on the average sentence length and the average number of syllables per word. While it is conceptually meant to take values in the 0 – 100 range — with 0 meaning unreadable and 100 meaning very easy to read — its formula is not strictly bounded, as shown in the examples below: df[‘Flesch_Ease’] = df[‘Text’].apply(textstat.flesch_reading_ease) print(“Flesch Reading Ease Scores:”) print(df[[‘Category’, ‘Flesch_Ease’]]) df[‘Flesch_Ease’] = df[‘Text’].apply(textstat.flesch_reading_ease) print(“Flesch Reading Ease Scores:”) print(df[[‘Category’, ‘Flesch_Ease’]]) Output: Flesch Reading Ease Scores: Category Flesch_Ease 0 Simple 105.880000 1 Standard 45.262353 2 Complex -8.045000 Flesch Reading Ease Scores: Category Flesch_Ease 0 Simple 105.880000 1 Standard 45.262353 2 Complex –8.045000 This is what the actual formula looks like: $$ 206.835 – 1.015 \left( \frac{\text{total words}}{\text{total sentences}} \right) – 84.6 \left( \frac{\text{total syllables}}{\text{total words}} \right) $$ Unbounded formulas like Flesch Reading Ease can hinder the proper training of a machine learning model, which is something to take into consideration during later feature engineering tasks. 2. Computing Flesch-Kincaid Grade Levels Unlike the Reading Ease score, which provides a single readability value, the Flesch-Kincaid Grade Level assesses text complexity using a scale similar to US school grade levels. In this case, higher values indicate greater complexity. Be warned, though: this metric also behaves similarly to the Flesch Reading Ease score, such that extremely simple or complex texts can yield scores below zero or arbitrarily high values, respectively. df[‘Flesch_Grade’] = df[‘Text’].apply(textstat.flesch_kincaid_grade) print(“Flesch-Kincaid Grade Levels:”) print(df[[‘Category’, ‘Flesch_Grade’]]) df[‘Flesch_Grade’] = df[‘Text’].apply(textstat.flesch_kincaid_grade) print(“Flesch-Kincaid Grade Levels:”) print(df[[‘Category’, ‘Flesch_Grade’]]) Output: Flesch-Kincaid Grade Levels: Category Flesch_Grade 0 Simple -0.266667 1 Standard 11.169412 2 Complex 19.350000 Flesch–Kincaid Grade Levels: Category Flesch_Grade 0 Simple –0.266667 1 Standard 11.169412 2 Complex 19.350000 3. Computing the SMOG Index Another measure with origins in assessing text complexity is the SMOG Index, which estimates the years of formal education required to comprehend a text. This formula is somewhat more bounded than others, as it has a strict mathematical floor slightly above 3. The simplest of our three example texts falls at the absolute minimum for this measure in terms of complexity. It takes into account factors such as the number of polysyllabic words, that is, words with three or more syllables. df[‘SMOG_Index’] = df[‘Text’].apply(textstat.smog_index) print(“SMOG Index Scores:”) print(df[[‘Category’, ‘SMOG_Index’]]) df[‘SMOG_Index’] = df[‘Text’].apply(textstat.smog_index) print(“SMOG Index Scores:”) print(df[[‘Category’, ‘SMOG_Index’]]) Output: SMOG Index Scores: Category SMOG_Index 0 Simple 3.129100 1 Standard 11.208143 2 Complex 20.267339 SMOG Index Scores: Category SMOG_Index 0 Simple 3.129100 1 Standard 11.208143 2 Complex 20.267339 4. Calculating the Gunning Fog Index Like the SMOG Index, the Gunning Fog Index also has a strict floor, in this case equal to zero. The reason is straightforward: it quantifies the percentage of complex words along with average sentence length. It is a popular metric for analyzing business texts and ensuring that technical or domain-specific content is accessible to a wider audience. df[‘Gunning_Fog’] = df[‘Text’].apply(textstat.gunning_fog) print(“Gunning Fog Index:”) print(df[[‘Category’, ‘Gunning_Fog’]]) df[‘Gunning_Fog’] = df[‘Text’].apply(textstat.gunning_fog) print(“Gunning Fog Index:”) print(df[[‘Category’, ‘Gunning_Fog’]]) Output: Gunning Fog Index: Category Gunning_Fog 0 Simple 2.000000 1 Standard 11.505882 2 Complex 26.000000 Gunning Fog Index: Category Gunning_Fog 0 Simple 2.000000 1 Standard 11.505882 2 Complex 26.000000 5. Calculating the Automated

