

Why and When to Use Sentence Embeddings Over Word EmbeddingsImage by Editor | ChatGPT Introduction Choosing the right text representation is a critical first step in any natural language processing (NLP) project. While both word and sentence embeddings transform text into numerical vectors, they operate at different scopes and are suited for different tasks. The key distinction is whether your goal is semantic or syntactic analysis. Sentence embeddings are the better choice when you need to understand the overall, compositional meaning of a piece of text. In contrast, word embeddings are superior for token-level tasks that require analyzing individual words and their linguistic features. Research shows that for tasks like semantic similarity, sentence embeddings can outperform aggregated word embeddings by a significant margin. This article will explore the architectural differences, performance benchmarks, and specific use cases for both sentence and word embeddings to help you decide which is right for your next project. Word Embeddings: Focusing on the Token Level Word embeddings represent individual words as dense vectors in a high-dimensional space. In this space, the distance and direction between vectors correspond to the semantic relationships between the words themselves. There are two main types of word embeddings: Static embeddings: Traditional models like Word2Vec and GloVe assign a single, fixed vector to each word, regardless of its context. Contextual embeddings: Modern models like BERT generate dynamic vectors for words based on the surrounding text in a sentence. The primary limitation of word embeddings arises when you need to represent an entire sentence. Simple aggregation methods, such as averaging the vectors of all words in a sentence, can dilute the overall meaning. For example, averaging the vectors for a sentence like “The orchestra performance was excellent, but the wind section struggled somewhat at times” would likely result in a neutral representation, losing the distinct positive and negative sentiments. Sentence Embeddings: Capturing Holistic Meaning Sentence embeddings are designed to encode an entire sentence or text passage into a single, dense vector that captures its complete semantic meaning. Transformer-based architectures, such as Sentence-BERT (SBERT), use specialized training techniques like siamese networks. This ensures that sentences with similar meanings are located close to each other in the vector space. Other powerful models include the Universal Sentence Encoder (USE), which creates 512-dimensional vectors optimized for semantic similarity. These models eliminate the need to write custom aggregation logic, simplifying the workflow for sentence-level tasks. Embeddings Implementations Let’s look at some implementations of embeddings, starting with contextual word embeddings. Make sure you have the torch and transformers libraries installed, which you can do with this line: pip install torch transformers. We will use the bert-base-uncased model. import torch from transformers import AutoTokenizer, AutoModel device=”cuda” if torch.cuda.is_available() else ‘cpu’ bert_model_name=”bert-base-uncased” tok = AutoTokenizer.from_pretrained(bert_model_name) bert = AutoModel.from_pretrained(bert_model_name).to(device).eval() def get_bert_token_vectors(text: str): “”” Returns: tokens: list[str] without [CLS]/[SEP] vecs: torch.Tensor [T, hidden] contextual vectors “”” enc = tok(text, return_tensors=”pt”, add_special_tokens=True) with torch.no_grad(): out = bert(**{k: v.to(device) for k, v in enc.items()}) last_hidden = out.last_hidden_state.squeeze(0) ids = enc[‘input_ids’].squeeze(0) toks = tok.convert_ids_to_tokens(ids) keep = [i for i, t in enumerate(toks) if t not in (‘[CLS]’, ‘[SEP]’)] toks = [toks[i] for i in keep] vecs = last_hidden[keep] return toks, vecs # Example usage toks, vecs = get_bert_token_vectors( “The orchestra performance was excellent, but the wind section struggled somewhat at times.” ) print(“Word embeddings created.”) print(f”Tokens:\n{toks}”) print(f”Vectors:\n{vecs}”) 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 import torch from transformers import AutoTokenizer, AutoModel device = ‘cuda’ if torch.cuda.is_available() else ‘cpu’ bert_model_name = ‘bert-base-uncased’ tok = AutoTokenizer.from_pretrained(bert_model_name) bert = AutoModel.from_pretrained(bert_model_name).to(device).eval() def get_bert_token_vectors(text: str): “”“ Returns: tokens: list[str] without [CLS]/[SEP] vecs: torch.Tensor [T, hidden] contextual vectors ““” enc = tok(text, return_tensors=‘pt’, add_special_tokens=True) with torch.no_grad(): out = bert(**{k: v.to(device) for k, v in enc.items()}) last_hidden = out.last_hidden_state.squeeze(0) ids = enc[‘input_ids’].squeeze(0) toks = tok.convert_ids_to_tokens(ids) keep = [i for i, t in enumerate(toks) if t not in (‘[CLS]’, ‘[SEP]’)] toks = [toks[i] for i in keep] vecs = last_hidden[keep] return toks, vecs # Example usage toks, vecs = get_bert_token_vectors( “The orchestra performance was excellent, but the wind section struggled somewhat at times.” ) print(“Word embeddings created.”) print(f“Tokens:\n{toks}”) print(f“Vectors:\n{vecs}”) If all goes well, here’s your output: Word embeddings created. Tokens: [‘the’, ‘orchestra’, ‘performance’, ‘was’, ‘excellent’, ‘,’, ‘but’, ‘the’, ‘wind’, ‘section’, ‘struggled’, ‘somewhat’, ‘at’, ‘times’, ‘.’] Vectors: tensor([[-0.6060, -0.5800, -1.4568, …, -0.0840, 0.6643, 0.0956], [-0.1886, 0.1606, -0.5778, …, -0.5084, 0.0512, 0.8313], [-0.2355, -0.2043, -0.6308, …, -0.0757, -0.0426, -0.2797], …, [-1.3497, -0.3643, -0.0450, …, 0.2607, -0.2120, 0.5365], [-1.3596, -0.0966, -0.2539, …, 0.0997, 0.2397, 0.1411], [ 0.6540, 0.1123, -0.3358, …, 0.3188, -0.5841, -0.2140]]) Word embeddings created. Tokens: [‘the’, ‘orchestra’, ‘performance’, ‘was’, ‘excellent’, ‘,’, ‘but’, ‘the’, ‘wind’, ‘section’, ‘struggled’, ‘somewhat’, ‘at’, ‘times’, ‘.’] Vectors: tensor([[–0.6060, –0.5800, –1.4568, …, –0.0840, 0.6643, 0.0956], [–0.1886, 0.1606, –0.5778, …, –0.5084, 0.0512, 0.8313], [–0.2355, –0.2043, –0.6308, …, –0.0757, –0.0426, –0.2797], …, [–1.3497, –0.3643, –0.0450, …, 0.2607, –0.2120, 0.5365], [–1.3596, –0.0966, –0.2539, …, 0.0997, 0.2397, 0.1411], [ 0.6540, 0.1123, –0.3358, …, 0.3188, –0.5841, –0.2140]]) Remember: Contextual models like BERT produce different vectors for the same word depending on surrounding text, which is superior for token-level tasks (NER/POS) that care mostly about local context. Now let’s look at sentence embeddings, using the all-MiniLM-L6-v2 model. Make sure you install the sentence-transformers library with this command: pip install -U sentence-transformers from sentence_transformers import SentenceTransformer #, util device=”cuda” if torch.cuda.is_available() else ‘cpu’ sbert_model_name=”sentence-transformers/all-MiniLM-L6-v2″ sbert = SentenceTransformer(sbert_model_name) def encode_sentences(sentences, normalize: bool=True): “”” Returns: embeddings: np.ndarray [N, 384] (MiniLM-L6-v2), optionally L2-normalized “”” return sbert.encode(sentences, normalize_embeddings=normalize) # Example usage sent_vecs = encode_sentences( [ “The orchestra performance was excellent.”, “The woodwinds were uneven at times.”, “What is the capital of France?”, ] ) print(“Sentence embeddings created.”) print(f”Vectors:\n{sent_vecs}”) 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 from sentence_transformers import SentenceTransformer #, util device = ‘cuda’ if torch.cuda.is_available() else ‘cpu’ sbert_model_name = ‘sentence-transformers/all-MiniLM-L6-v2’ sbert = SentenceTransformer(sbert_model_name) def encode_sentences(sentences, normalize: bool=True): “”“ Returns: embeddings: np.ndarray [N, 384] (MiniLM-L6-v2), optionally L2-normalized

Indias IT Sector Expected To Reach $400 Billion By 2030 Amidst AI-Related Disruptions
New Delhi: India’s information technology (IT) sector is projected to reach $400 billion by 2030, led by firms delivering domain-specific automation that outperforms traditional service models on speed, quality, and cost, a report said on Tuesday. The country’s strong talent pool, global client trust, and cost efficiency will enable it to leverage the increased global demand for AI-driven solutions, a report by venture firm Bessemer Venture Partners indicated. AI is automating tasks previously performed by humans and disrupting the billable-hour model that supports traditional Indian IT services, which makes deep strategic pivots crucial to stay competitive, the report noted. The venture firm mentioned that agile, AI-native challengers are adapting more quickly to such changes than incumbent companies. Three types of fast-moving AI-first challengers that will disrupt existing models are AI-enabled services, services built for AI, and pure software-led platforms, the report said. The venture firm forecast that India’s IT services industry will grow with margins intact despite challenges from AI-related disruptions. It noted that three years after the launch of ChatGPT, India’s IT revenues continue to climb, and margins remain surprisingly resilient because uptake of general-purpose large language models is concentrated in only two sectors- technology and media or advertising. Add Zee News as a Preferred Source Incumbent IT firms continue to play a crucial role in solving complex business problems that are nuanced rather than providing one-size-fits-all SaaS deployments. The strong balance sheets of these companies further strengthen client confidence, Bessemer Venture Partners said. Fortune 500 companies still trust that IT services vendors can manage multi-year projects, absorb macro shocks, and deliver consistent execution, the report said. The market capitalisation of India’s top ten IT firms has more than doubled from $166 billion to $354 billion in the past decade, driven by annual revenue growth exceeding 7 per cent.

7 Feature Engineering Tricks for Text Data
7 Feature Engineering Tricks for Text DataImage by Editor Introduction An increasing number of AI and machine learning-based systems feed on text data — language models are a notable example today. However, it is essential to note that machines do not truly understand language but rather numbers. Put another way: some feature engineering steps are typically needed to turn raw text data into useful numeric data features that these systems can digest and perform inference upon. This article presents seven easy-to-implement tricks for performing feature engineering on text data. Depending on the complexity and requirements of the specific model to feed your data to, you may require a more or less ambitious set of these tricks. Numbers 1 to 5 are typically used for classical machine learning dealing with text, including decision-tree-based models, for instance. Numbers 6 and 7 are indispensable for deep learning models like recurrent neural networks and transformers, although number 2 (stemming and lemmatization) might still be necessary to enhance these models’ performance. 1. Removing Stopwords Stopword removal helps reduce dimensionality: something indispensable for certain models that may suffer the so-called curse of dimensionality. Common words that may predominantly add noise to your data, like articles, prepositions, and auxiliary verbs, are removed, thereby keeping only those that convey most of the semantics in the source text. Here’s how to do it in just a few lines of code (you may simply replace words with a list of text chunked into words of your own). We’ll use NLTK for the English stopword list: import nltk nltk.download(‘stopwords’) from nltk.corpus import stopwords words = [“this”,”is”,”a”,”crane”, “with”, “black”, “feathers”, “on”, “its”, “head”] stop_set = set(stopwords.words(‘english’)) filtered = [w for w in words if w.lower() not in stop_set] print(filtered) import nltk nltk.download(‘stopwords’) from nltk.corpus import stopwords words = [“this”,“is”,“a”,“crane”, “with”, “black”, “feathers”, “on”, “its”, “head”] stop_set = set(stopwords.words(‘english’)) filtered = [w for w in words if w.lower() not in stop_set] print(filtered) 2. Stemming and Lemmatization Reducing words to their root form can help merge variants (e.g., different tenses of a verb) into a unified feature. In deep learning models based on text embeddings, morphological aspects are usually captured, hence this step is rarely needed. However, when available data is very limited, it can still be useful because it alleviates sparsity and pushes the model to focus on core word meanings rather than assimilating redundant representations. from nltk.stem import PorterStemmer stemmer = PorterStemmer() print(stemmer.stem(“running”)) from nltk.stem import PorterStemmer stemmer = PorterStemmer() print(stemmer.stem(“running”)) 3. Count-based Vectors: Bag of Words One of the simplest approaches to turn text into numerical features in classical machine learning is the Bag of Words approach. It simply encodes word frequency into vectors. The result is a two-dimensional array of word counts describing simple baseline features: something advantageous for capturing the overall presence and relevance of words across documents, but limited because it fails to capture important aspects for understanding language like word order, context, or semantic relationships. Still, it might end up being a simple yet effective approach for not-too-complex text classification models, for instance. Using scikit-learn: from sklearn.feature_extraction.text import CountVectorizer cv = CountVectorizer() print(cv.fit_transform([“dog bites man”, “man bites dog”, “crane astonishes man”]).toarray()) from sklearn.feature_extraction.text import CountVectorizer cv = CountVectorizer() print(cv.fit_transform([“dog bites man”, “man bites dog”, “crane astonishes man”]).toarray()) 4. TF-IDF Feature Extraction Term Frequency — Inverse Document Frequency (TF-IDF) has long been one of natural language processing’s cornerstone approaches. It goes a step beyond Bag of Words and accounts for the frequency of words and their overall relevance not only at the single text (document) level, but at the dataset level. For example, in a text dataset containing 200 pieces of text or documents, words that appear frequently in a specific, narrow subset of texts but overall appear in few texts out of the existing 200 are deemed highly relevant: this is the idea behind inverse frequency. As a result, unique and important words are given higher weight. By applying it to the following small dataset containing three texts, each word in each text is assigned a TF-IDF importance weight between 0 and 1: from sklearn.feature_extraction.text import TfidfVectorizer tfidf = TfidfVectorizer() print(tfidf.fit_transform([“dog bites man”, “man bites dog”, “crane astonishes man”]).toarray()) from sklearn.feature_extraction.text import TfidfVectorizer tfidf = TfidfVectorizer() print(tfidf.fit_transform([“dog bites man”, “man bites dog”, “crane astonishes man”]).toarray()) 5. Sentence-based N-Grams Sentence-based n-grams help capture the interaction between words, for instance, “new” and “york.” Using the CountVectorizer class from scikit-learn, we can capture phrase-level semantics by setting the ngram_range parameter to incorporate sequences of multiple words. For instance, setting it to (1,2) creates features that are associated with both single words (unigrams) and combinations of two consecutive words (bigrams). from sklearn.feature_extraction.text import CountVectorizer cv = CountVectorizer(ngram_range=(1,2)) print(cv.fit_transform([“new york is big”, “tokyo is even bigger”]).toarray()) from sklearn.feature_extraction.text import CountVectorizer cv = CountVectorizer(ngram_range=(1,2)) print(cv.fit_transform([“new york is big”, “tokyo is even bigger”]).toarray()) 6. Cleaning and Tokenization Although there exist plenty of specialized tokenization algorithms out there in Python libraries like Transformers, the basic approach they are based on consists of removing punctuation, casing, and other symbols that downstream models may not understand. A simple cleaning and tokenization pipeline could consist of splitting text into words, lower-casing, and removing punctuation signs or other special characters. The result is a list of clean, normalized word units or tokens. The re library for handling regular expressions can be used to build a simple tokenizer like this: import re text = “Hello, World!!!” tokens = re.findall(r’\b\w+\b’, text.lower()) print(tokens) import re text = “Hello, World!!!” tokens = re.findall(r‘\b\w+\b’, text.lower()) print(tokens) 7. Dense Features: Word Embeddings Finally, one of the highlights and most powerful approaches to turn text into machine-readable information nowadays: word embeddings. They are great at capturing semantics, such as words with similar meaning, like ‘shogun’ and ‘samurai’, or ‘aikido’ and ‘jiujitsu’, which are encoded as numerically similar vectors (embeddings). In essence, words are mapped into a vector space using pre-defined approaches like Word2Vec or spaCy: import spacy # Use a spaCy model with vectors (e.g., “en_core_web_md”) nlp = spacy.load(“en_core_web_md”) vec = nlp(“dog”).vector print(vec[:5])

AI Data Centers To Drive 160% Surge In Power Demand By 2030: Goldman Sachs | Technology News
New Delhi: Energy-intensive artificial intelligence (AI) data centers are expected to drive a sharp rise in power consumption, with data center power usage projected to increase by 160 per cent by 2030, according to a report by Goldman Sachs. The report noted that after nearly a decade of flat power demand growth, the emergence of AI-driven data centers is set to transform the global energy landscape. It stated, “data center power usage is expected to increase +160 per cent by 2030, driven by energy-intensive AI data centers.” The report highlighted that power generation is only one part of the issue, as transmission remains a significant bottleneck in bringing new power plants online. Citing the example of the United States, the report stated that most data centers are powered by natural gas due to its abundant supply. Add Zee News as a Preferred Source However, challenges in permitting, transmission, and critical supply chains–such as those related to gas turbines, have led to long timelines of around 5-7 years for getting new natural gas plants operational and connected to the grid. The report also estimated that about 60 per cent of the data center demand growth will need to be met with new capacity. This new capacity is likely to be powered by 30 per cent natural gas combined cycle gas turbine (CCGT), 30 per cent natural gas peakers, 27.5 per cent solar, and 12.5 per cent wind. The report further stated that while natural gas remains a key source of power, renewables are expected to play a growing role as they offer faster and more efficient ways to secure incremental power supply amid the long development timelines for gas-based plants. Hyperscale companies are adopting a mixed approach by combining different power sources to meet short-term energy needs. At the same time, they are investing in long-term solutions such as nuclear energy, though cautiously. Tech giants have been willing to invest in power infrastructure but have avoided direct development risk or asset ownership. Instead, they are turning to strategies such as forward-start power purchase agreements (PPAs) to accelerate progress. The report cited Alphabet’s recent agreement with Elementl Power to pre-position three sites for advanced nuclear energy as an example of this growing trend among major technology companies to secure sustainable and reliable energy for future AI operations.

3 Ways to Speed Up Model Training Without More GPUs
In this article, you will learn three proven ways to speed up model training by optimizing precision, memory, and data flow — without adding any new GPUs. Topics we will cover include: How mixed precision and memory techniques boost throughput safely Using gradient accumulation to train with larger “virtual” batches Sharding and offloading with ZeRO to fit bigger models on existing hardware Let’s not waste any more time. 3 Ways to Speed Up Model Training Without More GPUsImage by Editor Introduction Training large models can be painfully slow, and the first instinct is often to ask for more GPUs. But extra hardware isn’t always an option. There are issues that stand in the way, such as budgets and cloud limits. The good news is that there are ways to make training significantly faster without adding a single GPU. Speeding up training isn’t only about raw compute power; it’s about using what you already have more efficiently. A significant amount of time is wasted on memory swaps, idle GPUs, and unoptimized data pipelines. By improving how your code and hardware communicate, you can cut hours or even days from training runs. Method 1: Mixed Precision and Memory Optimizations One of the easiest ways to speed up training without new GPUs is to use mixed precision. Modern GPUs are designed to handle half-precision (FP16) or bfloat16 math much faster than standard 32-bit floats. By storing and computing in smaller data types, you reduce memory use and bandwidth, allowing more data to fit on the GPU at once, which means that the operations complete faster. The core idea is simple: Use lower precision (FP16 or BF16) for most operations Keep critical parts (like loss scaling and a few accumulations) in full precision (FP32) to maintain stability When done correctly, mixed precision often delivers 1.5 – 2 times faster training with little to no drop in accuracy. It’s supported natively in PyTorch, TensorFlow, and JAX, and most NVIDIA, AMD, and Apple GPUs now have hardware acceleration for it. Here’s a PyTorch example that enables automatic mixed precision: # Mixed Precision Example (PyTorch) import torch from torch import nn, optim from torch.cuda.amp import GradScaler, autocast model = nn.Linear(512, 10).cuda() optimizer = optim.Adam(model.parameters(), lr=1e-3) scaler = GradScaler() for inputs, targets in dataloader: optimizer.zero_grad() with autocast(): # operations run in lower precision outputs = model(inputs.cuda()) loss = nn.functional.cross_entropy(outputs, targets.cuda()) scaler.scale(loss).backward() # scaled to prevent underflow scaler.step(optimizer) scaler.update() 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 # Mixed Precision Example (PyTorch) import torch from torch import nn, optim from torch.cuda.amp import GradScaler, autocast model = nn.Linear(512, 10).cuda() optimizer = optim.Adam(model.parameters(), lr=1e–3) scaler = GradScaler() for inputs, targets in dataloader: optimizer.zero_grad() with autocast(): # operations run in lower precision outputs = model(inputs.cuda()) loss = nn.functional.cross_entropy(outputs, targets.cuda()) scaler.scale(loss).backward() # scaled to prevent underflow scaler.step(optimizer) scaler.update() Why this works: autocast() automatically chooses FP16 or FP32 per operation GradScaler() prevents underflow by dynamically adjusting the loss scale The GPU executes faster because it moves and computes fewer bytes per operation You can also activate it globally with PyTorch’s Automatic Mixed Precision (AMP) or Apex library for legacy setups. For newer devices (A100, H100, RTX 40 series), bfloat16 (BF16) is often more stable than FP16.Memory optimizations go hand-in-hand with mixed precision. Two common tricks are: Gradient checkpointing: save only key activations and recompute others during backpropagation, trading compute for memory Activation offloading: temporarily move rarely used tensors to CPU memory These can be enabled in PyTorch with: from torch.utils.checkpoint import checkpoint from torch.utils.checkpoint import checkpoint or configured automatically using DeepSpeed, Hugging Face Accelerate, or bitsandbytes. When to use it: If your model fits tightly on GPU memory, or your batch size is small You’re using a recent GPU (RTX 20-series or newer) You can tolerate minor numeric variation during training It is typically expected to gain 30–100% faster training and up to 50% less memory use, depending on model size and hardware. Method 2: Gradient Accumulation and Effective Batch Size Tricks Sometimes the biggest barrier to faster training isn’t compute, it’s GPU memory. You might want to train with large batches to improve gradient stability, but your GPU runs out of memory long before you reach that size. Gradient accumulation solves this neatly. Instead of processing one massive batch at once, you split it into smaller micro-batches. You run forward and backward passes for each micro-batch, accumulate the gradients, and only update the model weights after several iterations. This lets you simulate large-batch training using the same hardware. Here’s what that looks like in PyTorch: # Gradient Accumulation Example (PyTorch) import torch from torch import nn from torch.cuda.amp import GradScaler, autocast # Assumes `model`, `optimizer`, and `dataloader` are defined elsewhere criterion = nn.CrossEntropyLoss() scaler = GradScaler() accum_steps = 4 # accumulate gradients over 4 mini-batches for i, (inputs, targets) in enumerate(dataloader): with autocast(): # works nicely with mixed precision outputs = model(inputs.cuda()) loss = criterion(outputs, targets.cuda()) / accum_steps # normalize scaler.scale(loss).backward() if (i + 1) % accum_steps == 0: scaler.step(optimizer) scaler.update() optimizer.zero_grad(set_to_none=True) 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 # Gradient Accumulation Example (PyTorch) import torch from torch import nn from torch.cuda.amp import GradScaler, autocast # Assumes `model`, `optimizer`, and `dataloader` are defined elsewhere criterion = nn.CrossEntropyLoss() scaler = GradScaler() accum_steps = 4 # accumulate gradients over 4 mini-batches for i, (inputs, targets) in enumerate(dataloader): with autocast(): # works nicely with mixed precision outputs = model(inputs.cuda()) loss = criterion(outputs, targets.cuda()) / accum_steps # normalize scaler.scale(loss).backward() if (i + 1) % accum_steps == 0: scaler.step(optimizer) scaler.update() optimizer.zero_grad(set_to_none=True) How it works: The loss is divided by the number of accumulation steps to maintain balanced gradients Gradients are stored in memory between steps, rather than being cleared After accum_steps mini-batches, the optimizer performs a single update This simple change allows you to use a virtual batch size up to four or eight times larger, improving stability and potentially
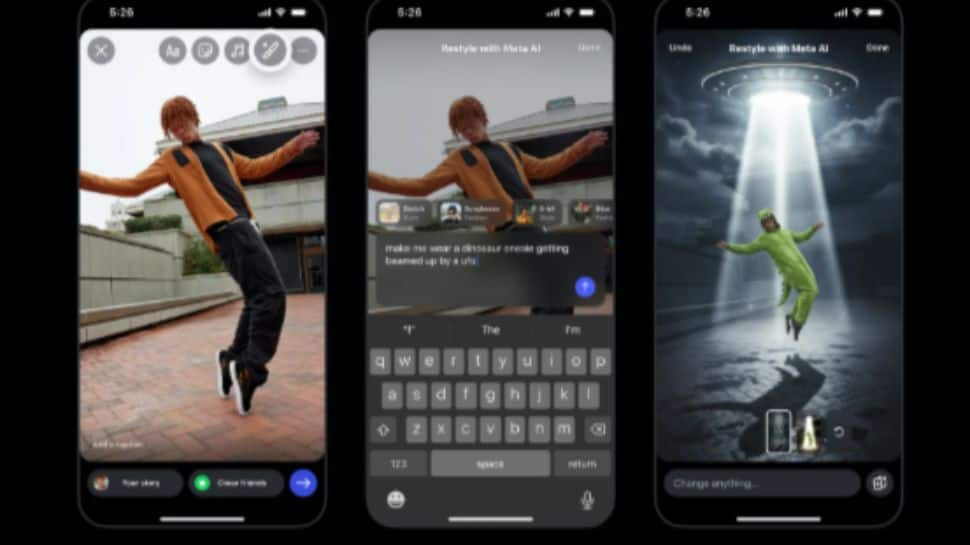
Instagram New Restyle Feature: Users Can Edit Photos And Video Using Meta AI Prompts; How To Use It | Technology News
Instagram New Restyle Feature: Instagram is reportedly rolling out a new feature that allows users to edit images and videos in Stories using Meta AI prompts. The much-anticipated update lets users add, remove, or modify elements in an image or video through simple text prompts — similar to Google’s Nano Banana image model. This feature closely resembles Google Photos’ new “Help Me Edit” tool, which also enables image editing via natural language commands. Adding further, users will be able to choose from a range of preset styles to make quick adjustments to their content. According to reports, the Meta-owned platform also plans to introduce the option to add custom text to the Restyle feature. The new Restyle feature on Instagram will be completely free to use, allowing users to restyle photos and videos directly within the app without any paid add-ons or subscriptions. Previously, Instagram’s AI-powered editing tools were limited to the integrated Meta AI chatbot, but by bringing these capabilities to Stories, Meta is making AI editing more accessible and user-friendly than ever before. Add Zee News as a Preferred Source How To Use Instagram Restyle For Photos And Videos? Step 1: Open Instagram and tap the + button at the top-left of the screen. Step 2: Choose the image from your camera roll you want to add to your Story, then tap the Restyle button (paintbrush icon). Step 3: Use natural-language prompts to add, remove, or change objects — or ask Meta AI to replace the background. Step 4: When finished editing, tap Done and proceed to post your Story. Step 5: For videos, follow the same steps — but instead of full object edits, choose from the available presets to restyle the clip. (Also Read: Samsung Galaxy S26 Ultra Likely To Debut In India With Qi2 Wireless Charging Support; Check Expected Display, Battery, Design, Camera, Price, Launch Date And Other Features) Instagram Guide To Write Better Prompts Meta has also shared a guide to help users craft better prompts. The company suggests considering factors such as subject, lighting and mood, composition, style, and location to achieve the desired results when editing photos and videos. However, Meta hasn’t announced a global rollout timeline for the tool, its availability will likely depend on the regions where Meta AI is currently active.

MinMax vs Standard vs Robust Scaler: Which One Wins for Skewed Data?
In this article, you will learn how MinMaxScaler, StandardScaler, and RobustScaler transform skewed, outlier-heavy data, and how to pick the right one for your modeling pipeline. Topics we will cover include: How each scaler works and where it breaks on skewed or outlier-rich data A realistic synthetic dataset to stress-test the scalers A practical, code-ready heuristic for choosing a scaler Let’s not waste any more time. MinMax vs Standard vs Robust Scaler: Which One Wins for Skewed Data?Image by Editor Introduction You’ve loaded your dataset and the distribution plots look rough. Heavy right tail, some obvious outliers, and that familiar sinking feeling that your model performance is sure to be suboptimal. Been there? Choosing the right scaler for skewed data isn’t just about following best practices. It’s about understanding what each method actually does to your data and when those transformations help versus hurt your model’s ability to learn meaningful patterns. In this article, we’ll test MinMaxScaler, StandardScaler, and RobustScaler on realistic data, see exactly what happens under the hood, and give you a practical decision framework for your next project. Let’s begin! 🔗 Link to the code on GitHub Understanding How Common Data Scalers Work Let’s start by understanding how the different scalers work, their advantages and disadvantages. MinMax Scaler MinMax Scaler squashes everything into a fixed range, usually [0,1], using your data’s minimum and maximum values. scaled_value = (value – min) / (max – min) MinMaxScaler has the following advantages: Bounded output range [0,1] Preserves original data relationships Fast and simple to understand The problem: Extreme outliers make the denominator massive, compressing most of your actual data into a tiny fraction of the available range. Standard Scaler Standard Scaler centers data around zero with unit variance by subtracting the mean and dividing by standard deviation. scaled_value = (value – mean) / standard_deviation StandardScaler has the following advantages: Works great with normally distributed data Centers data around zero Well-understood by most teams The problem: Both mean and standard deviation are heavily influenced by outliers, skewing the scaling for normal data points. Robust Scaler Robust Scaler uses the median and interquartile range (IQR) instead of the mean and standard deviation, which are susceptible to outliers. scaled_value = (value – median) / IQR IQR = Q3 – Q1 where: Q1 = First quartile (25th percentile) – the value below which 25% of data falls Q3 = Third quartile (75th percentile) – the value below which 75% of data falls RobustScaler has the following advantages: Resistant to outliers Uses percentiles (25th and 75th) that ignore extreme values Preserves data distribution shape The problem: It has an unbounded output range, which can be less intuitive to interpret. Creating Sample Data Let’s create a dataset that actually reflects what you’ll encounter in production. We’ll combine three common data patterns: normal user behavior, naturally skewed distributions (like revenue or page views), and those extreme outliers that always seem to sneak into real datasets. We’ll use NumPy, Pandas, Matplotlib, and SciPy. import numpy as np import pandas as pd import matplotlib.pyplot as plt from sklearn.preprocessing import MinMaxScaler, StandardScaler, RobustScaler from scipy import stats np.random.seed(42) # Simulate typical user behavior patterns normal_data = np.random.normal(50, 15, 800) # Add natural skew (common in revenue, pageviews, etc.) skewed_data = np.random.exponential(2, 800) * 10 + 20 # Include inevitable extreme outliers outliers = [200, 180, 190, 210, 195] # Combine into one messy dataset data = np.concatenate([normal_data, skewed_data, outliers]) df = pd.DataFrame({‘original’: data}) # Apply all three scalers scalers = { ‘MinMax’: MinMaxScaler(), ‘Standard’: StandardScaler(), ‘Robust’: RobustScaler() } for name, scaler in scalers.items(): df[name] = scaler.fit_transform(df[[‘original’]]).flatten() # Check what we’re working with print(“Original Data Stats:”) print(f”Mean: {df[‘original’].mean():.2f}”) print(f”Median: {df[‘original’].median():.2f}”) print(f”Std Dev: {df[‘original’].std():.2f}”) print(f”Skewness: {stats.skew(df[‘original’]):.2f}”) print(f”Range: {df[‘original’].min():.1f} to {df[‘original’].max():.1f}”) 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 import numpy as np import pandas as pd import matplotlib.pyplot as plt from sklearn.preprocessing import MinMaxScaler, StandardScaler, RobustScaler from scipy import stats np.random.seed(42) # Simulate typical user behavior patterns normal_data = np.random.normal(50, 15, 800) # Add natural skew (common in revenue, pageviews, etc.) skewed_data = np.random.exponential(2, 800) * 10 + 20 # Include inevitable extreme outliers outliers = [200, 180, 190, 210, 195] # Combine into one messy dataset data = np.concatenate([normal_data, skewed_data, outliers]) df = pd.DataFrame({‘original’: data}) # Apply all three scalers scalers = { ‘MinMax’: MinMaxScaler(), ‘Standard’: StandardScaler(), ‘Robust’: RobustScaler() } for name, scaler in scalers.items(): df[name] = scaler.fit_transform(df[[‘original’]]).flatten() # Check what we’re working with print(“Original Data Stats:”) print(f“Mean: {df[‘original’].mean():.2f}”) print(f“Median: {df[‘original’].median():.2f}”) print(f“Std Dev: {df[‘original’].std():.2f}”) print(f“Skewness: {stats.skew(df[‘original’]):.2f}”) print(f“Range: {df[‘original’].min():.1f} to {df[‘original’].max():.1f}”) Here’s the info for the sample dataset: Original Data Stats: Mean: 45.65 Median: 42.81 Std Dev: 20.52 Skewness: 2.07 Range: 1.4 to 210.0 Original Data Stats: Mean: 45.65 Median: 42.81 Std Dev: 20.52 Skewness: 2.07 Range: 1.4 to 210.0 What Actually Happens During Data Scaling Let’s take a look at the numbers to understand exactly what each scaler is doing to our data. The statistics will reveal why some scalers fail with skewed data while others handle it quite well. Effect of MinMax Scaler on Sample Data First, let’s examine how MinMaxScaler’s reliance on min/max values creates problems when outliers are present. print(“=== MinMaxScaler Analysis ===”) min_val = df[‘original’].min() max_val = df[‘original’].max() print(f”Scaling range: {min_val:.1f} to {max_val:.1f}”) # Show the compression effect percentiles = [50, 75, 90, 95, 99] for p in percentiles: pct_val = df[‘MinMax’].quantile(p/100) print(f”{p}% of data falls below: {pct_val:.3f}”) data_below_half = (df[‘MinMax’] < 0.5).sum() / len(df) * 100 print(f”\nResult: {data_below_half:.1f}% of data compressed below 0.5″) print(“=== MinMaxScaler Analysis ===”) min_val = df[‘original’].min() max_val = df[‘original’].max() print(f“Scaling range: {min_val:.1f} to {max_val:.1f}”) # Show the compression effect percentiles = [50, 75, 90, 95, 99] for p in percentiles: pct_val = df[‘MinMax’].quantile(p/100) print(f“{p}% of data falls below: {pct_val:.3f}”) data_below_half =

Meta Lays Off 600 Employees Amid AI Labs Reorganisation, Focuses On Next-Gen Models | Technology News
Meta Layoffs 2025: Meta, the parent company of Facebook and Instagram, has announced to cut off around 600 positions in its Superintelligence Labs, the company said on Wednesday. The move is part of a reorganisation aimed at making the artificial intelligence (AI) unit more flexible and efficient, reported by Reuters. The job cuts will affect several parts of Meta’s AI division, including the Facebook Artificial Intelligence Research (FAIR) unit, as well as teams working on product-related AI and AI infrastructure. However, the newly formed TBD Lab, which includes a small team of researchers and engineers developing Meta’s next-generation AI foundation models, will not be affected. Chief AI Officer Alexandr Wang said that reducing team sizes will help streamline decision-making and give each remaining team member greater responsibility, scope, and impact. Meta is also encouraging employees affected by the cuts to apply for other positions within the company. Add Zee News as a Preferred Source Restructuring Follows Llama 4 Reception The reorganisation has come months after Meta consolidated its AI efforts under the Superintelligence Labs in June. This restructuring followed the departure of some senior staff and a lukewarm reception for its open-source Llama 4 AI model. CEO Mark Zuckerberg had previously led an aggressive hiring drive to strengthen the company’s AI capabilities. (Also Read: ChatGPT Kicked Off WhatsApp: Meta Bans AI Bots – Will Your Chats Survive After Jan 15?) Superintelligence Labs now includes Meta’s foundation, product, and FAIR teams, alongside the TBD Lab, which is focused on creating the next generation of AI models. Meta’s AI journey began in 2013 when it launched the FAIR unit and hired Yann LeCun as chief AI scientist. Since then, the company has built a global research network focused on deep learning. Reorganisation Comes Amid Big Financing Deal The announcement also comes shortly after Meta secured a $27 billion financing deal with Blue Owl Capital, the company’s largest-ever private capital agreement. The deal will fund Meta’s biggest data center project, with analysts noting it allows the company to pursue its AI ambitions while shifting much of the upfront cost and risk to external investors.

7 Pandas Tricks to Handle Large Datasets
7 Pandas Tricks to Handle Large DatasetsImage by Editor Introduction Large dataset handling in Python is not exempt from challenges like memory constraints and slow processing workflows. Thankfully, the versatile and surprisingly capable Pandas library provides specific tools and techniques for dealing with large — and often complex and challenging in nature — datasets, including tabular, text, or time-series data. This article illustrates 7 tricks offered by this library to efficiently and effectively manage such large datasets. 1. Chunked Dataset Loading By using the chunksize argument in Pandas’ read_csv() function to read datasets contained in CSV files, we can load and process large datasets in smaller, more manageable chunks of a specified size. This helps prevent issues like memory overflows. import pandas as pd def process(chunk): “””Placeholder function that you may replace with your actual code for cleaning and processing each data chunk.””” print(f”Processing chunk of shape: {chunk.shape}”) chunk_iter = pd.read_csv(“https://raw.githubusercontent.com/frictionlessdata/datasets/main/files/csv/10mb.csv”, chunksize=100000) for chunk in chunk_iter: process(chunk) import pandas as pd def process(chunk): “”“Placeholder function that you may replace with your actual code for cleaning and processing each data chunk.”“” print(f“Processing chunk of shape: {chunk.shape}”) chunk_iter = pd.read_csv(“https://raw.githubusercontent.com/frictionlessdata/datasets/main/files/csv/10mb.csv”, chunksize=100000) for chunk in chunk_iter: process(chunk) 2. Downcasting Data Types for Memory Efficiency Optimization Tiny changes can make a big difference when they are applied to a large number of data elements. This is the case when converting data types to a lower-bit representation using functions like astype(). Simple yet very effective, as shown below. For this example, let’s load the dataset into a Pandas dataframe (without chunking, for the sake of simplicity in explanations): url = “https://raw.githubusercontent.com/frictionlessdata/datasets/main/files/csv/10mb.csv” df = pd.read_csv(url) df.info() url = “https://raw.githubusercontent.com/frictionlessdata/datasets/main/files/csv/10mb.csv” df = pd.read_csv(url) df.info() # Initial memory usage print(“Before optimization:”, df.memory_usage(deep=True).sum() / 1e6, “MB”) # Downcasting the type of numeric columns for col in df.select_dtypes(include=[“int”]).columns: df[col] = pd.to_numeric(df[col], downcast=”integer”) for col in df.select_dtypes(include=[“float”]).columns: df[col] = pd.to_numeric(df[col], downcast=”float”) # Converting object/string columns with few unique values to categorical for col in df.select_dtypes(include=[“object”]).columns: if df[col].nunique() / len(df) < 0.5: df[col] = df[col].astype(“category”) print(“After optimization:”, df.memory_usage(deep=True).sum() / 1e6, “MB”) # Initial memory usage print(“Before optimization:”, df.memory_usage(deep=True).sum() / 1e6, “MB”) # Downcasting the type of numeric columns for col in df.select_dtypes(include=[“int”]).columns: df[col] = pd.to_numeric(df[col], downcast=“integer”) for col in df.select_dtypes(include=[“float”]).columns: df[col] = pd.to_numeric(df[col], downcast=“float”) # Converting object/string columns with few unique values to categorical for col in df.select_dtypes(include=[“object”]).columns: if df[col].nunique() / len(df) < 0.5: df[col] = df[col].astype(“category”) print(“After optimization:”, df.memory_usage(deep=True).sum() / 1e6, “MB”) Try it yourself and notice the substantial difference in efficiency. 3. Using Categorical Data for Frequently Occurring Strings Handling attributes containing repeated strings in a limited fashion is made more efficient by mapping them into categorical data types, namely by encoding strings into integer identifiers. This is how it can be done, for example, to map the names of the 12 zodiac signs into categorical types using the publicly available horoscope dataset: import pandas as pd url=”https://raw.githubusercontent.com/plotly/datasets/refs/heads/master/horoscope_data.csv” df = pd.read_csv(url) # Convert ‘sign’ column to ‘category’ dtype df[‘sign’] = df[‘sign’].astype(‘category’) print(df[‘sign’]) import pandas as pd url = ‘https://raw.githubusercontent.com/plotly/datasets/refs/heads/master/horoscope_data.csv’ df = pd.read_csv(url) # Convert ‘sign’ column to ‘category’ dtype df[‘sign’] = df[‘sign’].astype(‘category’) print(df[‘sign’]) 4. Saving Data in Efficient Format: Parquet Parquet is a binary columnar dataset format that contributes to much faster file reading and writing than plain CSV. Therefore, it might be a preferred option worth considering for very large files. Repeated strings like the zodiac signs in the horoscope dataset introduced earlier are also internally compressed to further simplify memory usage. Note that writing/reading Parquet in Pandas requires an optional engine such as pyarrow or fastparquet to be installed. # Saving dataset as Parquet df.to_parquet(“horoscope.parquet”, index=False) # Reloading Parquet file efficiently df_parquet = pd.read_parquet(“horoscope.parquet”) print(“Parquet shape:”, df_parquet.shape) print(df_parquet.head()) # Saving dataset as Parquet df.to_parquet(“horoscope.parquet”, index=False) # Reloading Parquet file efficiently df_parquet = pd.read_parquet(“horoscope.parquet”) print(“Parquet shape:”, df_parquet.shape) print(df_parquet.head()) 5. GroupBy Aggregation Large dataset analysis usually involves obtaining statistics for summarizing categorical columns. Having previously converted repeated strings to categorical columns (trick 3) has follow-up benefits in processes like grouping data by category, as illustrated below, where we aggregate horoscope instances per zodiac sign: numeric_cols = df.select_dtypes(include=[‘float’, ‘int’]).columns.tolist() # Perform groupby aggregation safely if numeric_cols: agg_result = df.groupby(‘sign’)[numeric_cols].mean() print(agg_result.head(12)) else: print(“No numeric columns available for aggregation.”) numeric_cols = df.select_dtypes(include=[‘float’, ‘int’]).columns.tolist() # Perform groupby aggregation safely if numeric_cols: agg_result = df.groupby(‘sign’)[numeric_cols].mean() print(agg_result.head(12)) else: print(“No numeric columns available for aggregation.”) Note that the aggregation used, an arithmetic mean, affects purely numerical features in the dataset: in this case, the lucky number in each horoscope. It may not make too much sense to average these lucky numbers, but the example is just for the sake of playing with the dataset and illustrating what can be done with large datasets more efficiently. 6. query() and eval() for Efficient Filtering and Computation We will add a new, synthetic numerical feature to our horoscope dataset to illustrate how the use of the aforementioned functions can make filtering and other computations faster at scale. The query() function is used to filter rows that accomplish a condition, and the eval() function applies computations, typically among multiple numeric features. Both functions are designed to handle large datasets efficiently: df[‘lucky_number_squared’] = df[‘lucky_number’] ** 2 print(df.head()) numeric_cols = df.select_dtypes(include=[‘float’, ‘int’]).columns.tolist() if len(numeric_cols) >= 2: col1, col2 = numeric_cols[:2] df_filtered = df.query(f”{col1} > 0 and {col2} > 0″) df_filtered = df_filtered.assign(Computed=df_filtered.eval(f”{col1} + {col2}”)) print(df_filtered[[‘sign’, col1, col2, ‘Computed’]].head()) else: print(“Not enough numeric columns for demo.”) df[‘lucky_number_squared’] = df[‘lucky_number’] ** 2 print(df.head()) numeric_cols = df.select_dtypes(include=[‘float’, ‘int’]).columns.tolist() if len(numeric_cols) >= 2: col1, col2 = numeric_cols[:2] df_filtered = df.query(f“{col1} > 0 and {col2} > 0”) df_filtered = df_filtered.assign(Computed=df_filtered.eval(f“{col1} + {col2}”)) print(df_filtered[[‘sign’, col1, col2, ‘Computed’]].head()) else: print(“Not enough numeric columns for demo.”) 7. Vectorized String Operations for Efficient Column Transformations Performing vectorized operations on strings in pandas datasets is a seamless and almost transparent process that is more efficient than manual alternatives like loops. This

Best Phones Under ₹10,000 With 5000mAh Battery: 5 Power-Packed Picks For You | Technology News
Looking for a powerful smartphone that fits your budget? In 2025, several brands are offering feature-packed 5G phones under ₹10,000 — combining big batteries, vibrant displays, and solid performance. If you want a phone that lasts long, runs smoothly, and looks premium, here are the Top 5 Smartphones Under ₹10,000 With 5000mAh Battery you can consider! 1. Xiaomi Redmi 13C 5G Add Zee News as a Preferred Source Price: ₹9,999/- The Xiaomi Redmi 13C 5G is one of the best options for budget users seeking 5G connectivity with reliable performance. Featuring a 6.74-inch 90Hz IPS LCD display protected by Gorilla Glass 3, it ensures durability and smooth visuals. Powered by the MediaTek Dimensity 6100+ (6nm) chipset, the phone runs on Android 13 with MIUI 14 for a clean experience. It comes with multiple RAM variants up to 8GB and storage up to 256GB (UFS 2.2), ensuring fast app performance. The 50MP main camera delivers sharp photos, and its 5000mAh battery with 18W charging lasts easily through the day. Colors: Starry Black, Twilight Blue, Startrail Green Highlight: Reliable 5G performance and strong battery backup. Image Credit: Xiaomi 2. Itel Color Pro 5G Price: ₹8,999/- Itel’s Color Pro 5G is one of the most affordable 5G smartphones in India. It’s powered by the MediaTek Dimensity 6080 (6nm) processor and runs on Android 13 (Itel OS 13). The device sports a 6.56-inch 90Hz IPS LCD display, making scrolling and gaming smoother. It includes 128GB storage and 6GB RAM, ensuring decent multitasking. The 50MP rear camera and 8MP front camera perform well in daylight conditions. With a 5000mAh battery and 18W fast charging, you can enjoy long hours of usage. Colors: River Blue, Lavender Fantasy Highlight: The most budget-friendly 5G phone with balanced specs. Image Credit: itel India 3. Samsung Galaxy M06 5G Price: ₹9,499/- The Samsung Galaxy M06 5G brings Samsung’s reliability and user-friendly One UI to the under ₹10K segment. It’s powered by an octa-core processor (2.4GHz + 2GHz) and offers a 6.7-inch HD+ PLS LCD display. With 6GB RAM and 128GB storage (expandable up to 1.5TB), it’s ideal for multitasking and storing media. The phone includes a 50MP + 2MP rear camera setup and 8MP front camera for selfies. Its 5000mAh battery supports all-day use, and Samsung’s optimization ensures efficient power management. Highlight: Trusted brand with long battery life and premium software experience. Image Credit: Samsung 4. Infinix Hot 50 5G Price: ₹9,999/- The Infinix Hot 50 5G offers excellent value with its 6.7-inch IPS LCD 90Hz display and MediaTek Dimensity 6300 chipset. Running on Android 14 with XOS 14, it delivers the latest software experience. The device features 8GB RAM and 128GB storage (expandable up to 1TB), along with a 48MP main camera and 8MP selfie camera. The 5000mAh battery with 18W fast charging provides excellent endurance, while the IP54 rating ensures dust and water resistance. Highlight: Latest Android version with durable, sleek design. Image Credit: Infinix 5. Vivo Y28 5G Price: Around ₹9,999/- The Vivo Y28 5G combines elegant looks with powerful performance. It features a 6.56-inch 90Hz IPS LCD display and runs on Android 13 (Funtouch OS 13). Powered by the MediaTek Dimensity 6020 (7nm) chipset, it offers smooth multitasking. The phone boasts a 50MP dual rear camera, 8MP selfie camera, and a 5000mAh battery with 15W charging. With up to 8GB RAM and 128GB storage, it’s a great all-rounder for this price segment. Colors: Crystal Purple, Glitter Aqua Highlight: Stylish design with balanced performance and great battery life. Image Credit: Vivo With so many options available under ₹10,000, choosing a smartphone with a 5000mAh battery and 5G support has never been easier. Whether you prioritise performance, display quality, or brand reliability, these top 5 picks for 2025 offer excellent value for money. Pick the one that suits your needs and enjoy long-lasting battery life, smooth multitasking, and vibrant visuals without stretching your budget. Upgrade smartly and make the most of your mobile experience this year!


