Access Denied You don’t have permission to access “http://zeenews.india.com/technology/watching-ind-vs-nz-t20-world-cup-2026-final-online-5-tips-for-faster-internet-speed-and-buffer-free-match-streaming-3024914.html” on this server. Reference #18.f42ddf17.1772963264.1dd65afc https://errors.edgesuite.net/18.f42ddf17.1772963264.1dd65afc
Deploying AI Agents to Production: Architecture, Infrastructure, and Implementation Roadmap
Deploying AI Agents to Production: Architecture, Infrastructure, and Implementation Roadmap – MachineLearningMastery.com Deploying AI Agents to Production: Architecture, Infrastructure, and Implementation Roadmap – MachineLearningMastery.com
Access Denied
Access Denied You don’t have permission to access “http://zeenews.india.com/technology/world-s-highest-paid-ceos-sundar-pichai-could-earn-692-million-from-alphabet-over-3-years-reportedly-3024552.html” on this server. Reference #18.54fdd417.1772932925.619209a7 https://errors.edgesuite.net/18.54fdd417.1772932925.619209a7
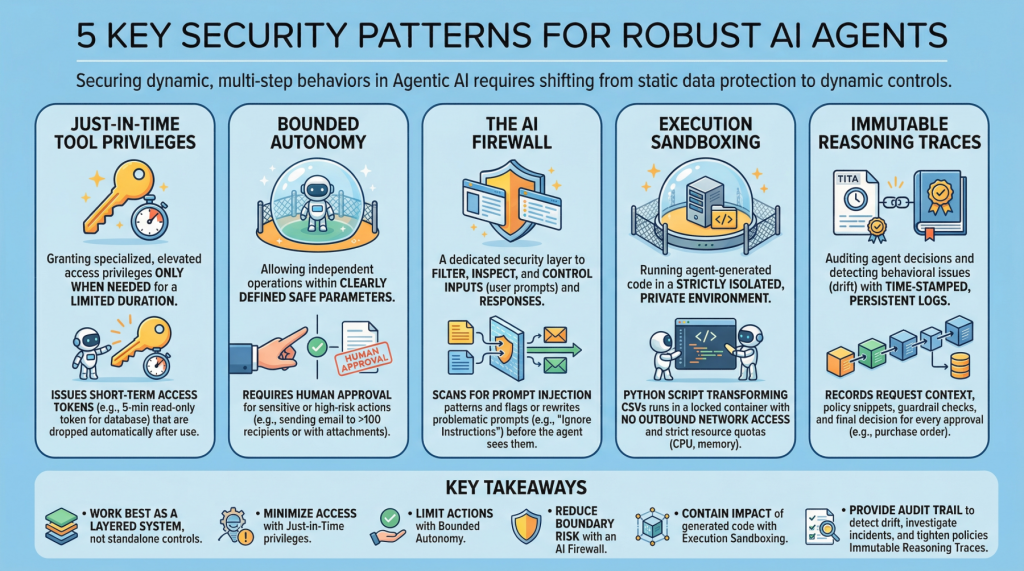
5 Essential Security Patterns for Robust Agentic AI
5 Essential Security Patterns for Robust Agentic AIImage by Editor Introduction Agentic AI, which revolves around autonomous software entities called agents, has reshaped the AI landscape and influenced many of its most visible developments and trends in recent years, including applications built on generative and language models. With any major technology wave like agentic AI comes the need to secure these systems. Doing so requires a shift from static data protection to safeguarding dynamic, multi-step behaviors. This article lists 5 key security patterns for robust AI agents and highlights why they matter. 1. Just-in-Time Tool Privileges Often abbreviated as JIT, this is a security model that grants users or applications specialized or elevated access privileges only when needed, and only for a limited period of time. It stands in contrast to classic, permanent privileges that remain in place unless manually modified or revoked. In the realm of agentic AI, an example would be issuing short term access tokens to limits the “blast radius” if the agent becomes compromised. Example: Before an agent runs a billing reconciliation job, it requests a narrowly scoped, 5-minute read-only token for a single database table and automatically drops the token as soon as the query completes. 2. Bounded Autonomy This security principle allows AI agents to operate independently within a bounded setting, meaning within clearly defined safe parameters, striking a balance between control and efficiency. This is especially important in high-risk scenarios where catastrophic errors from full autonomy can be avoided by requiring human approval for sensitive actions. In practice, this creates a control plane to reduce risk and support compliance requirements. Example: An agent may draft and schedule outbound emails on its own, but any message to more than 100 recipients (or containing attachments) is routed to a human for approval before sending. 3. The AI Firewall This refers to a dedicated security layer that filters, inspects, and controls inputs (user prompts) and subsequent responses to safeguard AI systems. It helps protect against threats such as prompt injection, data exfiltration, and toxic or policy-violating content. Example: Incoming prompts are scanned for prompt-injection patterns (for example, requests to ignore prior instructions or to reveal secrets), and flagged prompts are either blocked or rewritten into a safer form before the agent sees them. 4. Execution Sandboxing Take a strictly isolated, private environment or network perimeter and run any agent-generated code within it: this is known as execution sandboxing. It helps prevent unauthorized access, resource exhaustion, and potential data breaches by containing the impact of untrusted or unpredictable execution. Example: An agent that writes a Python script to transform CSV files runs it inside a locked-down container with no outbound network access, strict CPU/memory quotas, and a read-only mount of the input data. 5. Immutable Reasoning Traces This practice supports auditing autonomous agent decisions and detecting behavioral issues such as drift. It entails building time-stamped, tamper-evident, and persistent logs that capture the agent’s inputs, key intermediate artifacts used for decision-making, and policy checks. This is a crucial step toward transparency and accountability for autonomous systems, particularly in high-stakes application domains like procurement and finance. Example: For every purchase order the agent approves, it records the request context, the retrieved policy snippets, the applied guardrail checks, and the final decision in a write-once log that can be independently verified during audits. Key Takeaways These patterns work best as a layered system rather than standalone controls. Just-in-time tool privileges minimize what an agent can access at any moment, while bounded autonomy limits which actions it can take without oversight. The AI firewall reduces risk at the interaction boundary by filtering and shaping inputs and outputs, and execution sandboxing contains the impact of any code the agent generates or executes. Finally, immutable reasoning traces provide the audit trail that lets you detect drift, investigate incidents, and continuously tighten policies over time. Security Pattern Description Just-in-Time Tool Privileges Grant short-lived, narrowly scoped access only when needed to reduce the blast radius of compromise. Bounded Autonomy Constrain which actions an agent can take independently, routing sensitive steps through approvals and guardrails. The AI Firewall Filter and inspect prompts and responses to block or neutralize threats like prompt injection, data exfiltration, and toxic content. Execution Sandboxing Run agent-generated code in an isolated environment with strict resource and access controls to contain harm. Immutable Reasoning Traces Create time-stamped, tamper-evident logs of inputs, intermediate artifacts, and policy checks for auditability and drift detection. Together, these limitations reduce the chance of a single failure turning into a systemic breach, without eliminating the operational benefits that make agentic AI appealing.
Access Denied
Access Denied You don’t have permission to access “http://zeenews.india.com/technology/nothing-phone-4a-pro-vs-motorola-edge-70-fusion-price-in-india-display-chipset-battery-camera-build-quality-and-full-specs-compared-3024536.html” on this server. Reference #18.eff43717.1772865944.49b6a75f https://errors.edgesuite.net/18.eff43717.1772865944.49b6a75f
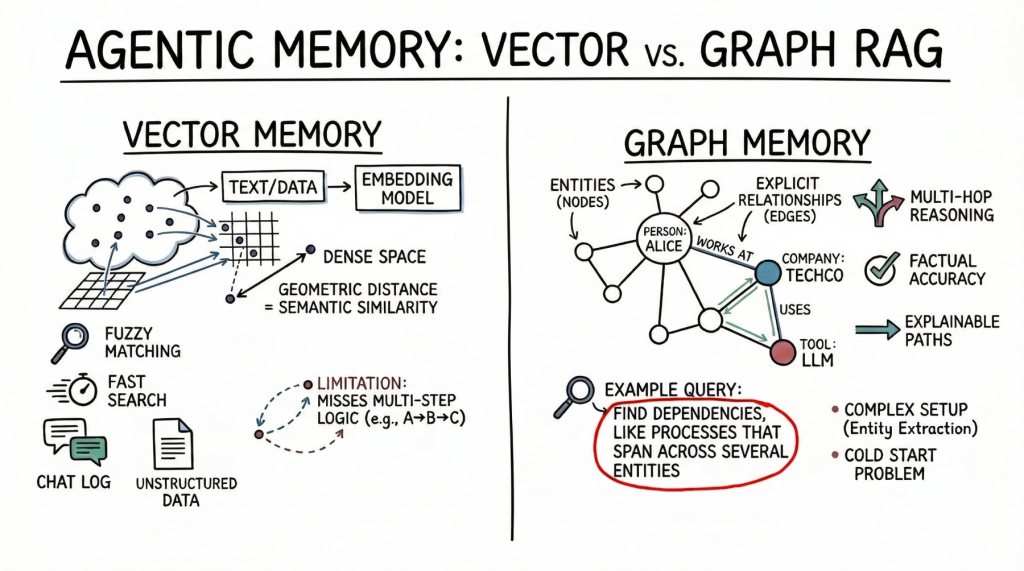
Vector Databases vs. Graph RAG for Agent Memory: When to Use Which
In this article, you will learn how vector databases and graph RAG differ as memory architectures for AI agents, and when each approach is the better fit. Topics we will cover include: How vector databases store and retrieve semantically similar unstructured information. How graph RAG represents entities and relationships for precise, multi-hop retrieval. How to choose between these approaches, or combine them in a hybrid agent-memory architecture. With that in mind, let’s get straight to it. Vector Databases vs. Graph RAG for Agent Memory: When to Use WhichImage by Author Introduction AI agents need long-term memory to be genuinely useful in complex, multi-step workflows. An agent without memory is essentially a stateless function that resets its context with every interaction. As we move toward autonomous systems that manage persistent tasks (such as like coding assistants that track project architecture or research agents that compile ongoing literature reviews) the question of how to store, retrieve, and update context becomes critical. Currently, the industry standard for this task is the vector database, which uses dense embeddings for semantic search. Yet, as the need for more complex reasoning grows, graph RAG, an architecture that combines knowledge graphs with large language models (LLMs), is gaining traction as a structured memory architecture. At a glance, vector databases are ideal for broad similarity matching and unstructured data retrieval, while graph RAG excels when context windows are limited and when multi-hop relationships, factual accuracy, and complex hierarchical structures are required. This distinction highlights vector databases’ focus on flexible matching, compared with graph RAG’s ability to reason through explicit relationships and preserve accuracy under tighter constraints. To clarify their respective roles, this article explores the underlying theory, practical strengths, and limitations of both approaches for agent memory. In doing so, it provides a practical framework to guide the choice of system, or combination of systems, to deploy. Vector Databases: The Foundation of Semantic Agent Memory Vector databases represent memory as dense mathematical vectors, or embeddings, situated in high-dimensional space. An embedding model maps text, images, or other data to arrays of floats, where the geometric distance between two vectors corresponds to their semantic similarity. AI agents primarily use this approach to store unstructured text. A common use case is storing conversational history, allowing the agent to recall what a user previously asked by searching its memory bank for semantically related past interactions. Agents also leverage vector stores to retrieve relevant documents, API documentation, or code snippets based on the implicit meaning of a user’s prompt, which is a far more robust approach than relying on exact keyword matches. Vector databases are strong choices for agent memory. They offer fast search, even across billions of vectors. Developers also find them easier to set up than structured databases. To integrate a vector store, you split the text, generate embeddings, and index the results. These databases also handle fuzzy matching well, accommodating typos and paraphrasing without requiring strict queries. But semantic search has limits for advanced agent memory. Vector databases often cannot follow multi-step logic. For instance, if an agent needs to find the link between entity A and entity C but only has data showing that A connects to B and B connects to C, a simple similarity search may miss important information. These databases also struggle when retrieving large amounts of text or dealing with noisy results. With dense, interconnected facts (from software dependencies to company organizational charts) they can return related but irrelevant information. This can crowd the agent’s context window with less useful data. Graph RAG: Structured Context and Relational Memory Graph RAG addresses the limitations of semantic search by combining knowledge graphs with LLMs. In this paradigm, memory is structured as discrete entities represented as nodes (for example, a person, a company, or a technology), and the explicit relationships between them are represented as edges (for example, “works at” or “uses”). Agents using graph RAG create and update a structured world model. As they gather new information, they extract entities and relationships and add them to the graph. When searching memory, they follow explicit paths to retrieve the exact context. The main strength of graph RAG is its precision. Because retrieval follows explicit relationships rather than semantic closeness alone, the risk of error is lower. If a relationship does not exist in the graph, the agent cannot infer it from the graph alone. Graph RAG excels at complex reasoning and is ideal for answering structured questions. To find the direct reports of a manager who approved a budget, you trace a path through the organization and approval chain — a simple graph traversal, but a difficult task for vector search. Explainability is another major advantage. The retrieval path is a clear, auditable sequence of nodes and edges, not an opaque similarity score. This matters for enterprise applications that require compliance and transparency. On the downside, graph RAG introduces significant implementation complexity. It demands robust entity-extraction pipelines to parse raw text into nodes and edges, which often requires carefully tuned prompts, rules, or specialized models. Developers must also design and maintain an ontology or schema, which can be rigid and difficult to evolve as new domains are encountered. The cold-start problem is also prominent: unlike a vector database, which is useful the moment you embed text, a knowledge graph requires substantial upfront effort to populate before it can answer complex queries. The Comparison Framework: When to Use Which When architecting memory for an AI agent, keep in mind that vector databases excel at handling unstructured, high-dimensional data and are well suited to similarity search, whereas graph RAG is advantageous for representing entities and explicit relationships when those relationships are crucial. The choice should be driven by the data’s inherent structure and the expected query patterns. Vector databases are ideally suited to purely unstructured data — chat logs, general documentation, or sprawling knowledge bases built from raw text. They excel when the query intent is to explore broad themes, such as “Find me concepts similar to X”
Access Denied
Access Denied You don’t have permission to access “http://zeenews.india.com/technology/anthropic-confirms-supply-chain-risk-designation-ceo-apologises-for-criticising-trump-3024320.html” on this server. Reference #18.b52fc917.1772810559.7c3233c https://errors.edgesuite.net/18.b52fc917.1772810559.7c3233c
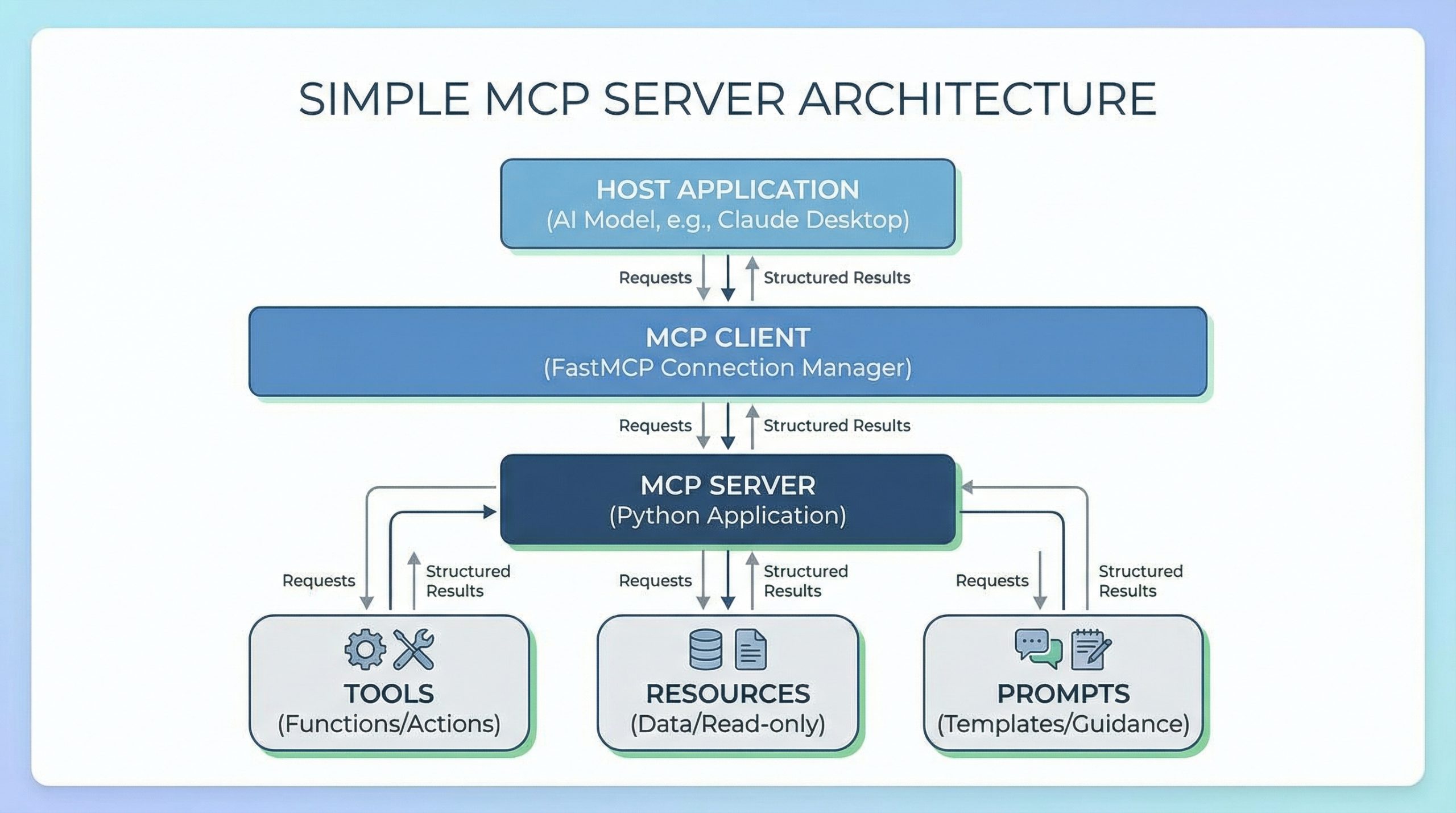
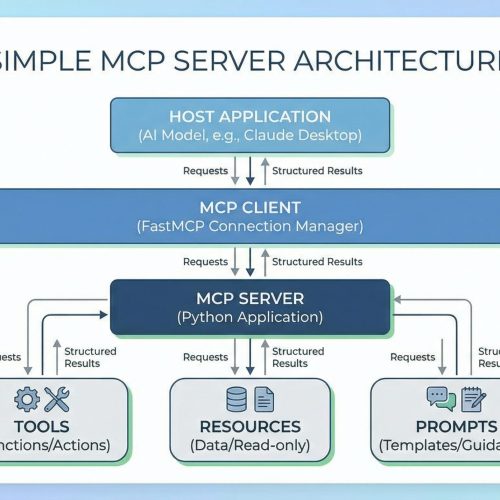
Building a Simple MCP Server in Python
In this article, you will learn what Model Context Protocol (MCP) is and how to build a simple, practical task-tracker MCP server in Python using FastMCP. Topics we will cover include: How MCP works, including hosts, clients, servers, and the three core primitives. How to implement MCP tools, resources, and prompts with FastMCP. How to run and test your MCP server using the FastMCP client. Let’s not waste any more time. Building a Simple MCP Server in PythonImage by Editor Introduction Have you ever tried connecting a language model to your own data or tools? If so, you know it often means writing custom integrations, managing API schemas, and wrestling with authentication. And every new AI application can feel like rebuilding the same connection logic from scratch. Model Context Protocol (MCP) solves this by standardizing how large language models (LLMs) and other AI models interact with external systems. FastMCP is a framework that makes building MCP servers simple. In this article, you’ll learn what MCP is, how it works, and how to build a practical task tracker server using FastMCP. You’ll create tools to manage tasks, resources to view task lists, and prompts to guide AI interactions. You can get the code on GitHub. Understanding the Model Context Protocol As mentioned, Model Context Protocol (MCP) is an open protocol that defines how AI applications communicate with external systems. How MCP Works MCP has three components: Hosts are the AI-powered applications users actually interact with. The host can be Claude Desktop, an IDE with AI features, or a custom app you’ve built. The host contains (or interfaces with) the language model and initiates connections to MCP servers. Clients connect to servers. When a host needs to talk to an MCP server, it creates a client instance to manage that specific connection. One host can run multiple clients simultaneously, each connected to a different server. The client handles all protocol-level communication. Servers are what you build. They expose specific capabilities — database access, file operations, API integrations — and respond to client requests by providing tools, resources, and prompts. So the user interacts with the host, the host uses a client to talk to your server, and the server returns structured results back up the chain. To learn more about MCP, read The Complete Guide to Model Context Protocol. The Three Core Primitives MCP servers expose three types of functionality: Tools are functions that perform actions. They’re like executable commands the LLM can invoke. add_task, send_an_email, and query_a_database are some examples of tools. Resources provide read-only access to data. They allow viewing information without changing it. Examples include lists of tasks, configuration files, and user profiles. Prompts are templates that guide AI interactions. They structure how the model approaches specific tasks. Examples include “Analyze these tasks and suggest priorities” and “Review this code for security issues.” In practice, you’ll combine these primitives. An AI model might use a resource to view tasks, then a tool to update one, guided by a prompt that defines the workflow. Setting Up Your Environment You’ll need Python 3.10 or later. Install FastMCP using pip (or uv if you prefer): Let’s get started! Building a Task Tracker Server We’ll build a server that manages a simple task list. Create a file called task_server.py and add the imports: from fastmcp import FastMCP from datetime import datetime from fastmcp import FastMCP from datetime import datetime These give us the FastMCP framework and datetime handling for tracking when tasks were created. Initializing the Server Now set up the server and a simple in-memory storage: mcp = FastMCP(“TaskTracker”) # Simple in-memory task storage tasks = [] task_id_counter = 1 mcp = FastMCP(“TaskTracker”) # Simple in-memory task storage tasks = [] task_id_counter = 1 Here’s what this does: FastMCP(“TaskTracker”) creates your MCP server with a descriptive name. tasks is a list that stores all tasks. task_id_counter generates unique IDs for each task. In a real application, you’d use a database. For this tutorial, we’ll keep it simple. Creating Tools Tools are functions decorated with @mcp.tool(). Let’s create three useful tools. Tool 1: Adding a New Task First, let’s create a tool that adds tasks to our list: @mcp.tool() def add_task(title: str, description: str = “”) -> dict: “””Add a new task to the task list.””” global task_id_counter task = { “id”: task_id_counter, “title”: title, “description”: description, “status”: “pending”, “created_at”: datetime.now().isoformat() } tasks.append(task) task_id_counter += 1 return task 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 @mcp.tool() def add_task(title: str, description: str = “”) -> dict: “”“Add a new task to the task list.”“” global task_id_counter task = { “id”: task_id_counter, “title”: title, “description”: description, “status”: “pending”, “created_at”: datetime.now().isoformat() } tasks.append(task) task_id_counter += 1 return task This tool does the following: Takes a task title (required) and an optional description. Creates a task dictionary with a unique ID, status, and timestamp. Adds it to our tasks list. Returns the created task. The model can now call add_task(“Write documentation”, “Update API docs”) and get a structured task object back. Tool 2: Completing a Task Next, let’s add a tool to mark tasks as complete: @mcp.tool() def complete_task(task_id: int) -> dict: “””Mark a task as completed.””” for task in tasks: if task[“id”] == task_id: task[“status”] = “completed” task[“completed_at”] = datetime.now().isoformat() return task return {“error”: f”Task {task_id} not found”} @mcp.tool() def complete_task(task_id: int) -> dict: “”“Mark a task as completed.”“” for task in tasks: if task[“id”] == task_id: task[“status”] = “completed” task[“completed_at”] = datetime.now().isoformat() return task return {“error”: f“Task {task_id} not found”} The tool searches the task list for a matching ID, updates its status to “completed”, and stamps it with a completion timestamp. It then returns the updated task or an error message if no match is found. Tool 3: Deleting a Task Finally, add a tool to remove tasks: @mcp.tool() def delete_task(task_id: int) -> dict: “””Delete a task from the list.””” for i, task
Access Denied
Access Denied You don’t have permission to access “http://zeenews.india.com/technology/what-is-anthropic-ai-how-it-helped-u-s-israel-to-kill-iran-s-supreme-leader-ali-khamenei-3023900.html” on this server. Reference #18.eff43717.1772720769.3c503192 https://errors.edgesuite.net/18.eff43717.1772720769.3c503192
Access Denied
Access Denied You don’t have permission to access “http://zeenews.india.com/technology/ai-6g-quantum-computing-to-drive-india-finland-strategic-partnership-pm-modi-3024037.html” on this server. Reference #18.f42ddf17.1772712327.1403c7b9 https://errors.edgesuite.net/18.f42ddf17.1772712327.1403c7b9