

In this article, you will learn five practical strategies for managing context windows in long-running AI agent applications, along with the key tradeoffs each approach introduces. Topics we will cover include: Why context windows become a critical bottleneck in agent-based AI systems designed for sustained, autonomous operation. Five distinct context management strategies: sliding windows, recursive summarization, structured state management, ephemeral context via RAG, and dynamic context routing. The inherent tradeoffs of each strategy, from memory loss and information compression to retrieval blind spots and maintenance complexity. Introduction Long-running agents are those capable of exhibiting sustained autonomous execution over time. In these agent-based applications — fueled by interactions with users or other systems in which information snowballs rapidly — the context window is a critical bottleneck. Agents and large language models, or LLMs in their abbreviated form, are two sides of the same coin in modern AI systems, so to speak. Accordingly, shifting from “LLMs as prompt-response engines” to “(agent-endowed) LLMs as long-running background processes” turns context windows into a major AI engineering bottleneck. For all these reasons, managing context windows in the long run requires specific strategies like sliding windows, tiered memory, and dynamic summarization. This article presents five different operational strategies for this, together with their inevitable tradeoffs. 1. Sliding Windows Think of an AI agent capable of remembering only its last ten minutes of work. Sliding window approaches simply manage memory limits: they drop the oldest messages, making room for the newest ones, with only core instructions being “locked” at the top of the context. Here is an example of what a sliding window implementation may look like (the code is not intended to be executable on its own; it is shown for illustrative purposes only): def manage_sliding_window(system_prompt, message_history, max_turns=10): “””Keep the permanent system instructions, and drop the oldest chat turns when history gets too long. “”” if len(message_history) > max_turns: # Trim history to keep only the ‘X’ most recent messages message_history = message_history[-max_turns:] # Always prepend the system prompt so the agent remembers its identity return [system_prompt] + message_history def manage_sliding_window(system_prompt, message_history, max_turns=10): “”“Keep the permanent system instructions, and drop the oldest chat turns when history gets too long. ““” if len(message_history) > max_turns: # Trim history to keep only the ‘X’ most recent messages message_history = message_history[–max_turns:] # Always prepend the system prompt so the agent remembers its identity return [system_prompt] + message_history While extremely cheap and fast due to no extra AI processing being required, this strategy has a caveat: “digital amnesia”. In other words, if the agent comes across a problem it already tackled an hour before, it will have completely forgotten how to handle it, which may trap it in never-ending loops. 2. Recursive Summarization Think of this as an image compression protocol like JPEG, but applied to the realm of context windows. Instead of removing the distant past as sliding windows would do, recursive summarization consists of periodically compressing old messages into a summary. This can help keep the overall agent’s “mission and plot” alive throughout long hours of operation, but of course, like in a blurry JPEG file, there is loss of information pertaining to fine details, which leaves the agent with a long-term yet vague memory of past events. 3. Structured State Management In this strategy, the running chat transcripts are left behind entirely. To replace them, the agent keeps a manageable JSON object that tracks goals, facts, and errors — serving as a structured sort of “scratchpad”. At every turn or step, the raw conversation is discarded, and the AI agent is passed only the core instructions, an updated JSON object, and the current, new input. This is undoubtedly a very token-efficient strategy. However, it heavily depends on the developer’s implemented criteria for what exactly should be tracked. If unexpected yet crucial variables fall outside the predefined schema boundaries, the agent will inevitably ignore them. This is a simplified example of what the implementation of this strategy could look like: def run_scratchpad_turn(system_prompt, scratchpad_state, new_input): “””Wipes conversational history entirely. The agent only navigates using their core instructions, current state, and new task. “”” # Combining the rigid state with the new input into a single prompt prompt = f”{system_prompt}\nMEMORIZED STATE: {scratchpad_state}\nNEW INPUT: {new_input}” # The AI processes the prompt, returning its next action plus an updated state ai_output = call_llm(prompt, response_format=”json”) return ai_output[“chosen_action”], ai_output[“updated_scratchpad”] def run_scratchpad_turn(system_prompt, scratchpad_state, new_input): “”“Wipes conversational history entirely. The agent only navigates using their core instructions, current state, and new task. ““” # Combining the rigid state with the new input into a single prompt prompt = f“{system_prompt}\nMEMORIZED STATE: {scratchpad_state}\nNEW INPUT: {new_input}” # The AI processes the prompt, returning its next action plus an updated state ai_output = call_llm(prompt, response_format=“json”) return ai_output[“chosen_action”], ai_output[“updated_scratchpad”] 4. Ephemeral Context via RAG The RAG-based strategy offloads everything in the cumulative context to an external database (a vector database in RAG systems, as explained here). This is an alternative to forcing an agent to keep its history in active memory, so that a silent search fetches back only the most relevant past events into the current prompt, based on relevance. This could theoretically let the agent run indefinitely without context overload issues. There is a downside, however: a retrieval blind spot, particularly if the agent needs to reconnect two apparently unrelated past events. Relying on the retriever and its underlying search policy for this may result in missing relevant context that would otherwise connect important “mental pieces”. 5. Dynamic Context Routing This strategy is designed to balance capability and cost. It makes two distinct AI models work together. The main agent runs high-frequency, repetitive tasks relying on a faster, cheaper model that manages smaller context windows. Meanwhile, when exceptional events occur — such as failing a task three times in a row — the full raw history is forwarded to a large-context, powerful model, which analyzes the big picture and delivers a cleaner instruction set back to the cheaper model. This is a
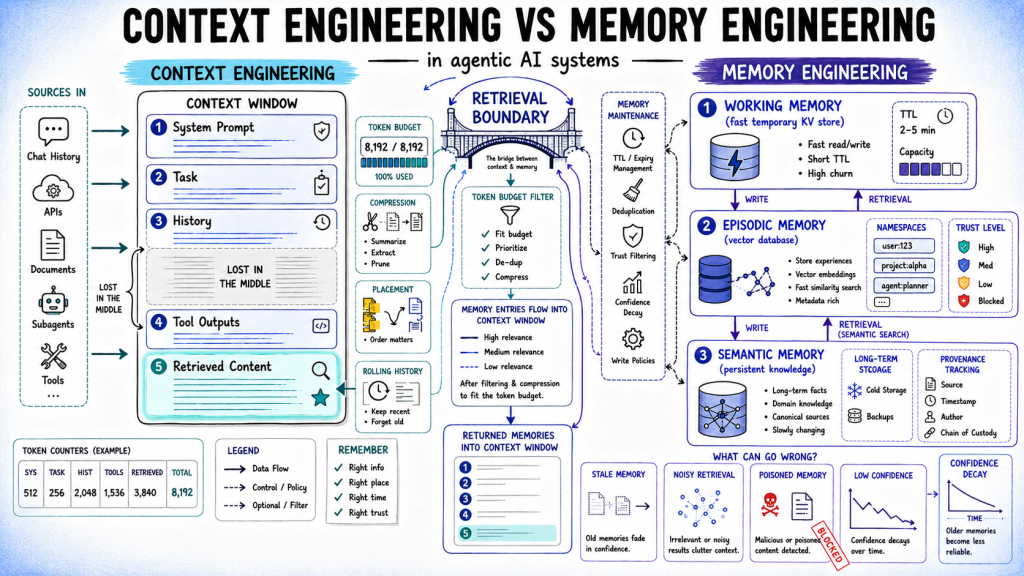
Context vs. Memory Engineering in Agentic AI Systems
In this article, you will learn how context engineering and memory engineering solve different problems in agentic AI systems, and how the two disciplines meet at the point where retrieved memory enters the context window. Topics we will cover include: What context engineering involves, including selective inclusion, structural placement, and compression, and why it matters for reasoning quality within a single inference call. What memory engineering involves, including write policy design, storage layer selection, retrieval strategy, and maintenance, and how these shape long-term reliability. How memory and context engineering meet at the retrieval boundary, and the two most common failure modes that occur when this boundary is not managed well. With that framing in place, here’s how each discipline works. Introduction As AI agents move into longer workflows and multi-session use cases, a familiar pattern emerges. Constraints get dropped mid-task, retrieved information resurfaces when it shouldn’t, and context from an earlier step bleeds into the current one. The failures are hard to pinpoint because no single component is obviously at fault. Most of the time, the problem lies in two areas that get built together, conflated, or skipped: context engineering and memory engineering. They are related but distinct, fail in different ways, and require different systems to get right. This article covers the core decisions behind each discipline and where they interact: What context engineering involves and the specific decisions that determine whether an agent reasons well within a single call What memory engineering involves and how write policy, storage, retrieval, and maintenance each affect long-term reliability How the two disciplines share a boundary at retrieval time and what it takes to manage that boundary well Understanding both, separately and together, is what determines whether an agent holds up across real workloads. An Overview of Context and Memory Engineering Context engineering covers the design of a single inference call: what to include, what to compress, where to place things, and what to discard. Everything in scope is ephemeral; when the call ends, the window clears. Memory engineering focuses on what survives beyond a single interaction with a model. It encompasses the systems and policies responsible for writing, storing, retrieving, updating, and governing information so that future interactions can make use of it. When an agent recalls information from a previous session, coordinates with another agent, or applies a user preference learned days or weeks earlier, it is relying on memory engineering rather than context engineering. While context engineering determines what information is available to the model during a specific request, memory engineering determines what information persists across requests and how that information is maintained, retrieved, and trusted over time. Here’s an overview: Aspect Context Engineering Memory Engineering Scope One inference call Across calls, sessions, agents Where data lives Inside the model’s active window External stores: vector DB, K/V, relational Primary problem What to include and how to arrange it What to persist, retrieve, and trust Fails when Window fills, placement is wrong, noise overwhelms signal Retrieval misses, staleness, poisoning, no write policy Engineering surface Prompt structure, compression, token budgeting Storage schema, retrieval strategy, write and update policies Lifespan of data Duration of one LLM call Depends on the memory type Context Engineering: Assembling the Optimal Context Window For an agent running a multi-step workflow, every inference call assembles a context window from multiple sources: system prompt, task description, conversation history, tool outputs, retrieved documents, subagent summaries. Context engineering is the set of decisions that determine what each component contributes, in what form, and in what position. Selective Inclusion Not everything available should enter the context. A database query returning hundreds of rows, a web search returning five complete articles, a code executor logging verbose output — all of these bloat the window and reduce reasoning quality before the token limit is reached. The decision about what gets included verbatim, what gets compressed to key facts, and what gets dropped is a design choice, not a default. Structural Placement Where information sits in the window affects how reliably the model uses it. Models attend more strongly to content at the beginning and end of long contexts, with material in the middle receiving significantly less weight. This is known as the “lost in the middle” effect. Hard constraints and task-critical instructions belong at the top of the window. Retrieved information that is most relevant to the current task should be placed near the end of the context window. The current user query or task should typically follow the retrieved information, positioning both the relevant context and the immediate objective as close as possible to the generation point. This arrangement increases the likelihood that the model will effectively use the retrieved information when producing its response. Context Engineering Overview Compression on Arrival Tool outputs should be compressed after a call returns, not after the window fills. A raw API response carrying 3,000 tokens, of which the agent needs only 150, should be summarized before it enters context for the next step. Waiting until the window is full and then scrambling to truncate is reactive management of a problem that compression at the source prevents. Conversation History Management Conversation history grows faster than any other context component. For long-running agents, carrying the full history into every call makes every subsequent inference more expensive and less reliable. A compression strategy — rolling window, hierarchical summarization, or structured state extraction — should be applied at defined intervals, not when the window overflows. Memory Engineering: Designing Persistent AI Memory Systems Once an inference call completes, memory engineering determines what deserves to persist and under what conditions it gets used again. This covers four distinct concerns: what to write, where to store it, how to retrieve it, and how to keep it accurate over time. Write Policy Design Write policy design is one of the most overlooked aspects of memory engineering, yet it has a disproportionate impact on memory quality over time. While retrieval systems often receive the most attention, retrieval quality is ultimately constrained by what
The Complete Guide to Tool Selection in AI Agents
In this article, you will learn why agent accuracy degrades as a tool catalog grows, and six practical techniques for keeping tool selection accurate and efficient at scale. Topics we will cover include: Why adding more tools to an agent causes tool hallucination and accuracy loss, not just slower responses. How gating, retrieval, routing, and planning each narrow down what the model sees before it has to choose a tool. How to build fallback logic and a benchmark harness so you can measure whether any of these fixes actually worked. None of this requires a bigger model, just a smarter view of what the model sees before it acts. Introduction You build an agent with five tools. It works flawlessly in the demo. Three months later, it has 40 file operations, CRM access, Slack, a calendar, and three different search APIs you bolted on for different teams. The same agent that nailed every demo now calls the wrong tool, hallucinates parameters borrowed from a different tool’s schema, or stalls mid-task waiting on a call that should never have been made. Nothing about the model changed. The tool list did. This is not an edge case you’ll eventually run into. It’s the default trajectory of every agent that ships and then grows. Research analyzing MCP tool descriptions across the ecosystem has found that a high number contain at least one quality issue, and production benchmarks show agent accuracy degrading measurably once tool counts pass roughly 10 to 15. The RAG-MCP paper, published in May 2025, put hard numbers on the fix: retrieval-based tool selection more than tripled tool selection accuracy from 13.62% to 43.13% while cutting prompt tokens by over half on the same benchmark tasks. Tool selection isn’t a minor implementation detail you patch later. It’s the architectural decision that determines whether an agent survives contact with a real tool catalog. This guide covers six techniques that solve it, in the order you’d actually deploy them: gating, retrieval, routing, planning, fallback logic, and the benchmark that tells you whether any of it worked. Why Tool Selection Breaks at Scale Every tool definition — its name, description, and parameter schema — gets sent to the model on every single request, whether that tool gets used or not. With 50-plus tools, this can consume 5 to 7% of the model’s context before the user’s actual message arrives, crowding out the conversation history and reasoning space the task actually needs. The “lost in the middle” effect compounds this. Models recall information at the start and end of a context window far more reliably than information buried in the middle. With dozens of near-identical tool definitions stacked in sequence, the one tool that’s actually right for the job often sits exactly in that dead zone, overlooked not because the model can’t reason about it, but because attention is structurally pulled elsewhere. The second failure mode is worse: tool hallucination. When an LLM’s attention spreads across too many similar-sounding tools, it either invents tool names that don’t exist or calls the correct tool while filling in arguments borrowed from a different tool’s schema. This is a hard failure. There’s no “slightly wrong” way to call a nonexistent function. OpenAI documents a hard ceiling of 128 tools per agent, but real degradation shows up well before that limit; most production teams see accuracy drop noticeably once they cross 15 to 20 tools in active rotation. The fix isn’t a bigger context window. It’s controlling what the model sees in the first place. Gating: Deciding Whether a Tool Is Needed at All Before you optimize which tool to pick, ask a cheaper question first: does this turn need a tool at all? A meaningful fraction of agent turns are purely conversational: “thanks,” “what do you mean by that,” a follow-up clarification. Running full retrieval and tool-selection reasoning on every single turn means paying the full agentic overhead even when the answer is “no tool needed.” A gate is a fast, cheap classifier — sometimes a small model call, sometimes just pattern matching — that runs before anything expensive does. # gate.py # Prerequisites: none beyond Python’s standard library (re) # Run: python gate.py import re CONVERSATIONAL_PATTERNS = [ r”^\s*(thanks|thank you|thx|ok|okay|cool|got it|sounds good|sure|great)\b”, r”^\s*(hi|hello|hey|good morning|good evening)\b”, r”^\s*what do you mean\b”, r”^\s*can you (clarify|explain that)\b”, ] ACTION_KEYWORDS = [ “send”, “create”, “search”, “find”, “look up”, “schedule”, “book”, “read”, “write”, “query”, “summarize”, “translate”, “check”, ] def gate(query: str) -> dict: “”” Cheap pre-filter that decides whether the full tool-selection pipeline needs to run at all. Short-circuits conversational turns before retrieval, routing, or planning ever fires. “”” q_lower = query.strip().lower() # Tier 1: regex match against known conversational patterns — near-zero cost for pattern in CONVERSATIONAL_PATTERNS: if re.match(pattern, q_lower): return {“tool_needed”: False, “reason”: “conversational_pattern”, “tier”: 1} # Tier 2: if there’s no action verb and the message is short, likely no tool needed has_action_keyword = any(kw in q_lower for kw in ACTION_KEYWORDS) if not has_action_keyword and len(q_lower.split()) < 5: return {“tool_needed”: False, “reason”: “short_with_no_action_keyword”, “tier”: 2} return {“tool_needed”: True, “reason”: “action_keyword_or_long_query”, “tier”: 2} if __name__ == “__main__”: test_queries = [ “thanks!”, “What’s the weather like in Lagos today?”, “ok”, “Can you send an email to the sales team about the delay?”, ] for q in test_queries: result = gate(q) print(f”‘{q}’ -> tool_needed={result[‘tool_needed’]} ({result[‘reason’]})”) 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 # gate.py # Prerequisites: none beyond Python’s standard library (re) # Run: python gate.py import re CONVERSATIONAL_PATTERNS = [ r“^\s*(thanks|thank you|thx|ok|okay|cool|got it|sounds good|sure|great)\b”, r“^\s*(hi|hello|hey|good morning|good evening)\b”, r“^\s*what do you mean\b”, r“^\s*can you (clarify|explain that)\b”, ] ACTION_KEYWORDS = [ “send”, “create”, “search”, “find”, “look up”, “schedule”, “book”, “read”, “write”, “query”, “summarize”, “translate”, “check”, ] def gate(query:
Access Denied
Access Denied You don’t have permission to access “http://zeenews.india.com/technology/why-do-smartphone-speakers-have-many-holes-but-not-all-produce-sound-here-s-the-real-reason-3059207.html” on this server. Reference #18.c4f43717.1783145205.36996cfa https://errors.edgesuite.net/18.c4f43717.1783145205.36996cfa
Access Denied
Access Denied You don’t have permission to access “http://zeenews.india.com/technology/5-biggest-instagram-myths-creators-still-believe-in-july-2026-3059151.html” on this server. Reference #18.c4f43717.1783100069.3351469a https://errors.edgesuite.net/18.c4f43717.1783100069.3351469a
Access Denied
Access Denied You don’t have permission to access “http://zeenews.india.com/india/govt-to-summon-meta-over-instagram-ads-promoting-child-sexual-abuse-material-in-india-sources-3059156.html” on this server. Reference #18.c4f43717.1783090423.322e13f6 https://errors.edgesuite.net/18.c4f43717.1783090423.322e13f6
Access Denied
Access Denied You don’t have permission to access “http://zeenews.india.com/technology/meta-pocket-new-ai-app-creates-interactive-games-from-your-text-prompt-3059115.html” on this server. Reference #18.c4f43717.1783077291.30ba94ad https://errors.edgesuite.net/18.c4f43717.1783077291.30ba94ad
Access Denied
Access Denied You don’t have permission to access “http://zeenews.india.com/technology/nothing-phone-4b-rcb-edition-revealed-matte-red-design-but-you-can-only-buy-it-in-bengaluru-3059075.html” on this server. Reference #18.c4f43717.1783067062.2f9591d0 https://errors.edgesuite.net/18.c4f43717.1783067062.2f9591d0
Access Denied
Access Denied You don’t have permission to access “http://zeenews.india.com/technology/oppo-reno-16-5g-flagship-looks-50mp-cameras-6700mah-battery-but-does-it-justify-rs-61999-3059035.html” on this server. Reference #18.eff43717.1783008562.1b119eea https://errors.edgesuite.net/18.eff43717.1783008562.1b119eea
Access Denied
Access Denied You don’t have permission to access “http://zeenews.india.com/technology/moto-g77-power-set-to-launch-in-india-on-this-date-7000mah-battery-3-day-backup-and-120hz-display-confirmed-3058964.html” on this server. Reference #18.c4f43717.1782996304.2903f8fb https://errors.edgesuite.net/18.c4f43717.1782996304.2903f8fb

