

New Flight Safety Rules In 2026: The Directorate General of Civil Aviation (DGCA) on Sunday clarified that passengers are not permitted to use power banks to charge mobile phones or any other electronic devices during flights, including through aircraft seat power outlets, citing serious safety concerns related to lithium batteries. The clarification follows several incidents worldwide in which lithium batteries overheated or caught fire on board aircraft. In October last year, a passenger’s power bank reportedly caught fire on an IndiGo flight bound for Dimapur while the aircraft was taxiing at Delhi airport. No injuries were reported, and all passengers and crew members were safely evacuated. Earlier, in November, the DGCA had issued a Dangerous Goods Advisory Circular allowing power banks and spare lithium batteries only in hand baggage. These items are strictly prohibited from being stored in overhead compartments, as fires in overhead bins are difficult to detect and control. Add Zee News as a Preferred Source Power Banks Use In Flights: Why Are Lithium Batteries A Safety Concern? According to the advisory, the growing use of lithium batteries in rechargeable devices has led to a sharp increase in passengers carrying power banks and spare batteries during air travel. The DGCA warned that these devices can act as ignition sources and may trigger fires on board, posing a serious risk to flight safety. The regulator explained that lithium batteries stored in overhead bins or inside carry-on bags can remain out of sight, making it difficult for passengers or crew members to detect early signs of smoke or fire. This delayed detection can slow emergency response and significantly increase the risk during a flight. (Also Read: What Is Full Form Of USB? From Type-A To USB-C Ports: Here’s What Every USB Port Means, Its Shape, And Transfer Speed Explained) DGCA Tightens Flight Safety Rules The DGCA has asked all airlines to review their current safety checks related to lithium batteries carried by passengers. Meanwhile, the airlines have been directed to strictly follow stronger safety measures to reduce the risk of battery-related fire incidents. Adding further, the aviation regulator has also emphasized better training for cabin crew so they can quickly spot signs of fire and respond effectively. Airlines must ensure that proper firefighting equipment and protective gear are available on board all aircraft. Mandatory Safety Announcement For Passengers Airlines have been directed to clearly inform passengers about the updated safety rules through in-flight announcements and other communication channels to ensure better awareness and compliance. According to the DGCA, these measures are essential to strengthen passenger safety and reduce the risk of lithium battery-related fire incidents during air travel. International Airlines Impose Curbs On Lithium Batteries It is important to note that similar rules were introduced earlier by several international airlines and countries, including Emirates and Singapore Airlines, after multiple lithium battery-related incidents were reported last year. These measures were taken to improve passenger safety and reduce the risk of fires during flights. In January, an Air Busan aircraft caught fire at South Korea’s Gimhae International Airport. Investigators later found that the blaze may have been caused by a power bank, possibly due to a failure in the battery’s internal insulation. The incident raised fresh concerns about the safety risks linked to lithium batteries on flights. (With IANS Inputs)

Elon Musk’s Starlink Announces Free Internet Services In Venezuela Till THIS Date After President Maduro’s Capture; Check Prices In US | Technology News
Elon Musk’s Free Starlink Service In Venezuela: Tesla and SpaceX CEO Elon Musk has announced that his satellite internet service, Starlink, will provide free broadband access to the people of Venezuela until February 3, ensuring uninterrupted connectivity amid the country’s ongoing crisis. Elon Musk shared the announcement on the social media platform X, stating that the move was made “in support of the people of Venezuela.” The announcement follows reports that the United States launched a swift overnight military operation against Venezuela on January 3, capturing President Nicolas Maduro and First Lady Cilia Flores. The Starlink network, which operates through a constellation of low-Earth orbit satellites, is expected to help maintain internet access during this period of political and security uncertainty. Elon Musk’s Starlink Service: Price In US Add Zee News as a Preferred Source In the United States, the standard Starlink kit costs $349 (around Rs 30,000), while the smaller Starlink Mini is priced at $599 (about Rs 43,000). In India, Starlink’s residential plan has a monthly fee of Rs 8,600, with an additional Rs 34,000 for the hardware kit. Meanwhile, the Internet speeds in India are expected to range from 25 Mbps to 220 Mbps, depending on the user’s location and satellite coverage. Elon Musk Celebrates Regime Change In Venezuela Musk’s celebration after the capture of Venezuela’s president isn’t surprising, as he has long been a vocal critic of Nicolás Maduro. Over the years, he has repeatedly called for political change, blaming the government’s policies for the country’s economic collapse. (Also Read: World’s Richest Person Elon Musk’s First Reaction After MeitY’s Notice; ‘Grok Users Making Illegal And indecent Content Will Face…’) During Venezuela’s 2024 elections, Musk openly supported the opposition and pushed for a regime change. He strongly backed opposition leader María Corina Machado, who later won the Nobel Peace Prize in 2025. Musk believes Venezuela could benefit from leaders who allow the country to fully develop its vast natural resources. In an April 2024 post, Musk said that Venezuela is rich in natural resources and could have been very prosperous if previous leaders hadn’t expanded government control through what he called “extreme socialism.”
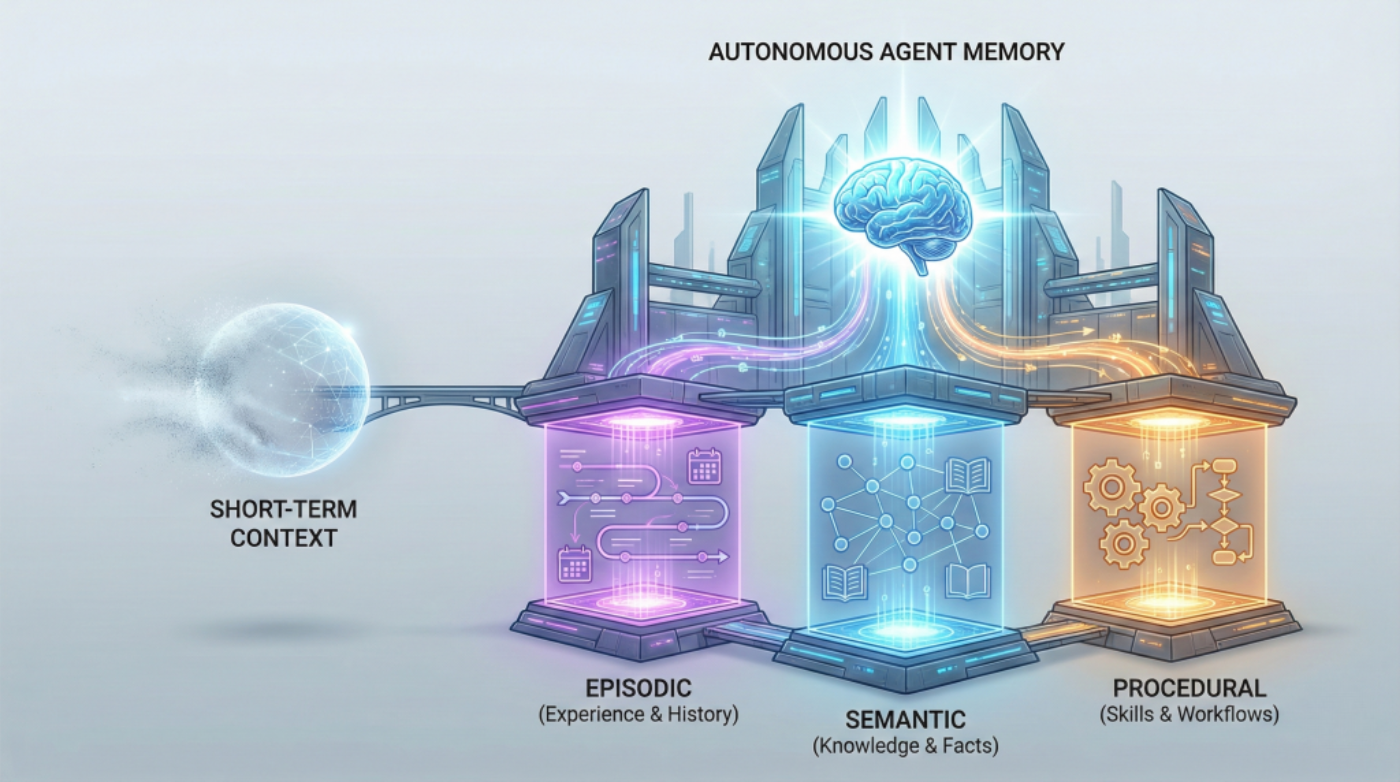
Beyond Short-term Memory: The 3 Types of Long-term Memory AI Agents Need
In this article, you will learn why short-term context isn’t enough for autonomous agents and how to design long-term memory that keeps them reliable across extended timelines. Topics we will cover include: The roles of episodic, semantic, and procedural memory in autonomous agents How these memory types interact to support real tasks across sessions How to choose a practical memory architecture for your use case Let’s get right to it. Beyond Short-term Memory: The 3 Types of Long-term Memory AI Agents NeedImage by Author If you’ve built chatbots or worked with language models, you’re already familiar with how AI systems handle memory within a single conversation. The model tracks what you’ve said, maintains context, and responds coherently. But that memory vanishes the moment the conversation ends. This works fine for answering questions or having isolated interactions. But what about AI agents that need to operate autonomously over weeks or months? Agents that schedule tasks, manage workflows, or provide personalized recommendations across multiple sessions? For these systems, session-based memory isn’t enough. The solution mirrors how human memory works. We don’t just remember conversations. We remember experiences (that awkward meeting last Tuesday), facts and knowledge (Python syntax, company policies), and learned skills (how to debug code, how to structure a report). Each type of memory serves a different purpose, and together they enable us to function effectively over time. AI agents need the same thing. Building agents that can learn from experience, accumulate knowledge, and execute complex tasks requires implementing three distinct types of long-term memory: episodic, semantic, and procedural. These aren’t just theoretical categories. They’re practical architectural decisions that determine whether your agent can truly operate autonomously or remains limited to simple, stateless interactions. Why Short-term Memory Hits a Wall Most developers are familiar with short-term memory in AI systems. It’s the context window that lets ChatGPT maintain coherence within a single conversation, or the rolling buffer that helps your chatbot remember what you said three messages ago. Short-term memory is essentially the AI’s working memory, useful for immediate tasks but limited in scope. Think of short-term memory like RAM in your computer. Once you close the application, it’s gone. Your AI agent forgets everything the moment the session ends. For basic question-answering systems, this limitation is manageable. But for autonomous agents that need to evolve, adapt, and operate independently across days, weeks, or months? Short-term memory isn’t enough. Even extremely large context windows simulate memory only temporarily. They don’t persist, accumulate, or improve across sessions without an external storage layer. The agents getting traction (the ones driving adoption of agentic AI frameworks and multi-agent systems) require a different approach: long-term memory that persists, learns, and guides intelligent action. The Three Pillars of Long-term Agent Memory Long-term memory in AI agents takes multiple forms. Autonomous agents need three distinct types of long-term memory, each serving a unique purpose. Each memory type answers a different question an autonomous agent must handle: What happened before? What do I know? How do I do this? Episodic Memory: Learning from Experience Episodic memory allows AI agents to recall specific events and experiences from their operational history. This stores what happened, when it happened, and what the outcomes were. Consider an AI financial advisor. With episodic memory, it doesn’t just know general investment principles; it remembers that three months ago, it recommended a tech stock portfolio to User A, and that recommendation underperformed. It recalls that User B ignored its advice about diversification and later regretted it. These specific experiences inform future recommendations in ways that general knowledge can’t. Episodic memory transforms an agent from a reactive system into one that learns from its own history. When your agent encounters a new situation, it can search its episodic memory for similar past experiences and adapt its approach based on what worked (or didn’t work) before. This memory type is often implemented using vector databases or other persistent storage layers, which enable semantic retrieval across past episodes. Instead of exact matching, the agent can find experiences that are conceptually similar to the current situation, even if the details differ. In practice, episodic memory stores structured records of interactions: timestamps, user identifiers, actions taken, environmental conditions, and outcomes observed. These episodes become case studies that the agent consults when making decisions, enabling a form of case-based reasoning that becomes more refined over time. Semantic Memory: Storing Structured Knowledge While episodic memory is about personal experiences, semantic memory stores factual knowledge and conceptual understanding. This is the facts, rules, definitions, and relationships the agent needs to reason about the world. A legal AI assistant relies heavily on semantic memory. It needs to know that contract law differs from criminal law, that certain clauses are standard in employment agreements, and that specific precedents apply in particular jurisdictions. This knowledge isn’t tied to specific cases it has worked on (that’s episodic), it’s general expertise that applies broadly. Semantic memory is often modeled using structured knowledge graphs or relational databases where entities and their relationships can be queried and reasoned over. That said, many agents also store unstructured domain knowledge in vector databases and retrieve it via RAG pipelines. When an agent needs to know “What are the side effects of combining these medications?” or “What are the standard security practices for API authentication?”, it’s querying semantic memory. The distinction between episodic and semantic memory matters for autonomous agents. Episodic memory tells the agent “Last Tuesday, when we tried approach X with client Y, it failed because of Z.” Semantic memory tells the agent “Approach X generally works best when conditions A and B are present.” Both are essential, but they serve different cognitive functions. For agents working in specialized domains, semantic memory often integrates with RAG systems to pull in domain-specific knowledge that wasn’t part of the base model’s training. This combination allows agents to maintain deep expertise without requiring massive model retraining. Over time, patterns extracted from episodic memory can be distilled into semantic knowledge, allowing agents to generalize
Centre Cracks Down On X Over Grok AI Misuse; Issues 72-Hour Ultimatum To Remove Obscene Content | India News
The Ministry of Electronics and Information Technology (MeitY) issued a warning to the Elon Musk-owned social media platform X (formerly Twitter) to take immediate steps to disable all “obscene, nude, indecent, and sexually explicit” content created by the AI-powered tool named Grok on the platform. The government has given the platform an ultimatum of 72 hours to submit its Action Taken Report (ATR), failing which the platform will face severe legal action and will also lose its “safe harbour” protection under Section 79 of the Information Technology Act. Grok Artificial Intelligence Misused To Target Women Add Zee News as a Preferred Source This is due to the misuse of the Grok AI facility, reported by the Centre. A four-page letter was written to the Chief Compliance Officer of X, indicating that users are creating fake accounts to host derogatory images and videos of women. The letter pointed out that it is noticed that this tool is being forced to “minimise clothing” and thereby sexualise women in the picture, which actually constitutes a grave disregard for their dignity and privacy. I would take this opportunity to thank Hon IT Minister for promptly taking note of my letter and for issuing a letter to X platform in the regard of AI led grok generating problematic content of women based on prompts that disrespect woman’s dignity and violates their consent,… pic.twitter.com/kEb1HameMn — Priyanka Chaturvedi (@priyankac19) January 2, 2026 Statutory Lapses And Legal Warnings The ministry pointed out the failure of X to abide by its statutory duty of due diligence as prescribed in the Information Technology Act, 2000, and the IT Rules, 2021. Safe Harbour in Jeopardy: Non-compliance could lead to X losing its safe harbour status, which would put it at risk to be held responsible for all third-party content that is currently published on its service. Broad Legal Action: The government issued a warning of legal action in relation to the Bharatiya Nyaya Sanhita (BNS), the Indecent Representation of Women Act, and the POCSO Act (in cases of children). Holistic Security Review Required Besides the initial removal, the Centre has also asked X to conduct an urgent technical and governance-based review of Grok. These include: Examination of Grok’s architecture design, including its structure Prompt Filtering: Enhancing protections against the production of offensive or illegal synthetic media. Accountability: Disciplinary action, like permanent suspension, against violators who misuse the AI tool. Evidence Preservation: Blocking access to illegal material without “vitiating the evidence” that might be relevant to possible criminal proceedings. Wider Crackdown On Digital Obscenity This action has been preceded by another letter, this time from an MP in the Rajya Sabha named Priyanka Chaturvedi, to IT Minister Ashwini Vaishnaw, pointing out the growing trend of “digital undressing” practices against women on this platform. VIDEO | Mumbai: Shiv Sena (UBT) MP Priyanka Chaturvedi says, “There is an AI tool on the platform X, previously known as Twitter, which is being misused. When women share photographs on social media, especially on X, people are prompting this AI tool to digitally disrobe them,… pic.twitter.com/lS637WSSr9 — Press Trust of India (@PTI_News) January 2, 2026 IT Minister Vaishwani again emphasised on Friday that social networking sites bear responsibility for content on their platforms and that “intervention” was also necessary to provide all users with a trustworthy internet. ALSO READ | Mexico Earthquake Today: 6.5 Magnitude Quake Hits Guerrero; President Sheinbaum Evacuates Briefing | SHOCKING VIDEOS

Train Your Large Model on Multiple GPUs with Fully Sharded Data Parallelism
import dataclasses import functools import os import datasets import tokenizers import torch import torch.distributed as dist import torch.nn as nn import torch.nn.functional as F import torch.optim.lr_scheduler as lr_scheduler import tqdm from torch import Tensor from torch.distributed.algorithms._checkpoint.checkpoint_wrapper import ( apply_activation_checkpointing, checkpoint_wrapper, ) from torch.distributed.checkpoint import load, save from torch.distributed.checkpoint.state_dict import ( StateDictOptions, get_state_dict, set_state_dict, ) from torch.distributed.fsdp import ( CPUOffloadPolicy, FSDPModule, MixedPrecisionPolicy, fully_shard, ) from torch.distributed.fsdp.wrap import transformer_auto_wrap_policy from torch.utils.data.distributed import DistributedSampler # Build the model @dataclasses.dataclass class LlamaConfig: “”“Define Llama model hyperparameters.”“” vocab_size: int = 50000 # Size of the tokenizer vocabulary max_position_embeddings: int = 2048 # Maximum sequence length hidden_size: int = 768 # Dimension of hidden layers intermediate_size: int = 4*768 # Dimension of MLP’s hidden layer num_hidden_layers: int = 12 # Number of transformer layers num_attention_heads: int = 12 # Number of attention heads num_key_value_heads: int = 3 # Number of key-value heads for GQA class RotaryPositionEncoding(nn.Module): “”“Rotary position encoding.”“” def __init__(self, dim: int, max_position_embeddings: int) -> None: “”“Initialize the RotaryPositionEncoding module. Args: dim: The hidden dimension of the input tensor to which RoPE is applied max_position_embeddings: The maximum sequence length of the input tensor ““” super().__init__() self.dim = dim self.max_position_embeddings = max_position_embeddings # compute a matrix of n\theta_i N = 10_000.0 inv_freq = 1.0 / (N ** (torch.arange(0, dim, 2) / dim)) inv_freq = torch.cat((inv_freq, inv_freq), dim=–1) position = torch.arange(max_position_embeddings) sinusoid_inp = torch.outer(position, inv_freq) # save cosine and sine matrices as buffers, not parameters self.register_buffer(“cos”, sinusoid_inp.cos()) self.register_buffer(“sin”, sinusoid_inp.sin()) def forward(self, x: Tensor) -> Tensor: “”“Apply RoPE to tensor x. Args: x: Input tensor of shape (batch_size, seq_length, num_heads, head_dim) Returns: Output tensor of shape (batch_size, seq_length, num_heads, head_dim) ““” batch_size, seq_len, num_heads, head_dim = x.shape device = x.device dtype = x.dtype # transform the cosine and sine matrices to 4D tensor and the same dtype as x cos = self.cos.to(device, dtype)[:seq_len].view(1, seq_len, 1, –1) sin = self.sin.to(device, dtype)[:seq_len].view(1, seq_len, 1, –1) # apply RoPE to x x1, x2 = x.chunk(2, dim=–1) rotated = torch.cat((–x2, x1), dim=–1) output = (x * cos) + (rotated * sin) return output class LlamaAttention(nn.Module): “”“Grouped-query attention with rotary embeddings.”“” def __init__(self, config: LlamaConfig) -> None: super().__init__() self.hidden_size = config.hidden_size self.num_heads = config.num_attention_heads self.head_dim = self.hidden_size // self.num_heads self.num_kv_heads = config.num_key_value_heads # GQA: H_kv < H_q # hidden_size must be divisible by num_heads assert (self.head_dim * self.num_heads) == self.hidden_size # Linear layers for Q, K, V projections self.q_proj = nn.Linear(self.hidden_size, self.num_heads * self.head_dim, bias=False) self.k_proj = nn.Linear(self.hidden_size, self.num_kv_heads * self.head_dim, bias=False) self.v_proj = nn.Linear(self.hidden_size, self.num_kv_heads * self.head_dim, bias=False) self.o_proj = nn.Linear(self.num_heads * self.head_dim, self.hidden_size, bias=False) def reset_parameters(self): self.q_proj.reset_parameters() self.k_proj.reset_parameters() self.v_proj.reset_parameters() self.o_proj.reset_parameters() def forward(self, hidden_states: Tensor, rope: RotaryPositionEncoding, attn_mask: Tensor) -> Tensor: bs, seq_len, dim = hidden_states.size() # Project inputs to Q, K, V query_states = self.q_proj(hidden_states).view(bs, seq_len, self.num_heads, self.head_dim) key_states = self.k_proj(hidden_states).view(bs, seq_len, self.num_kv_heads, self.head_dim) value_states = self.v_proj(hidden_states).view(bs, seq_len, self.num_kv_heads, self.head_dim) # Apply rotary position embeddings query_states = rope(query_states) key_states = rope(key_states) # Transpose tensors from BSHD to BHSD dimension for scaled_dot_product_attention query_states = query_states.transpose(1, 2) key_states = key_states.transpose(1, 2) value_states = value_states.transpose(1, 2) # Use PyTorch’s optimized attention implementation # setting is_causal=True is incompatible with setting explicit attention mask attn_output = F.scaled_dot_product_attention( query_states, key_states, value_states, attn_mask=attn_mask, dropout_p=0.0, enable_gqa=True, ) # Transpose output tensor from BHSD to BSHD dimension, reshape to 3D, and then project output attn_output = attn_output.transpose(1, 2).reshape(bs, seq_len, self.hidden_size) attn_output = self.o_proj(attn_output) return attn_output class LlamaMLP(nn.Module): “”“Feed-forward network with SwiGLU activation.”“” def __init__(self, config: LlamaConfig) -> None: super().__init__() # Two parallel projections for SwiGLU self.gate_proj = nn.Linear(config.hidden_size, config.intermediate_size, bias=False) self.up_proj = nn.Linear(config.hidden_size, config.intermediate_size, bias=False) self.act_fn = F.silu # SwiGLU activation function # Project back to hidden size self.down_proj = nn.Linear(config.intermediate_size, config.hidden_size, bias=False) def reset_parameters(self): self.gate_proj.reset_parameters() self.up_proj.reset_parameters() self.down_proj.reset_parameters() def forward(self, x: Tensor) -> Tensor: # SwiGLU activation: multiply gate and up-projected inputs gate = self.act_fn(self.gate_proj(x)) up = self.up_proj(x) return self.down_proj(gate * up) class LlamaDecoderLayer(nn.Module): “”“Single transformer layer for a Llama model.”“” def __init__(self, config: LlamaConfig) -> None: super().__init__() self.input_layernorm = nn.RMSNorm(config.hidden_size, eps=1e–5) self.self_attn = LlamaAttention(config) self.post_attention_layernorm = nn.RMSNorm(config.hidden_size, eps=1e–5) self.mlp = LlamaMLP(config) def reset_parameters(self): self.input_layernorm.reset_parameters() self.self_attn.reset_parameters() self.post_attention_layernorm.reset_parameters() self.mlp.reset_parameters() def forward(self, hidden_states: Tensor, rope: RotaryPositionEncoding, attn_mask: Tensor) -> Tensor: # First residual block: Self-attention residual = hidden_states hidden_states = self.input_layernorm(hidden_states) attn_outputs = self.self_attn(hidden_states, rope=rope, attn_mask=attn_mask) hidden_states = attn_outputs + residual # Second residual block: MLP residual = hidden_states hidden_states = self.post_attention_layernorm(hidden_states) hidden_states = self.mlp(hidden_states) + residual return hidden_states class LlamaModel(nn.Module): “”“The full Llama model without any pretraining heads.”“” def __init__(self, config: LlamaConfig) -> None: super().__init__() self.rotary_emb = RotaryPositionEncoding( config.hidden_size // config.num_attention_heads, config.max_position_embeddings, ) self.embed_tokens = nn.Embedding(config.vocab_size, config.hidden_size) self.layers = nn.ModuleList([ LlamaDecoderLayer(config) for _ in range(config.num_hidden_layers) ]) self.norm = nn.RMSNorm(config.hidden_size, eps=1e–5) def reset_parameters(self): self.embed_tokens.reset_parameters() for layer in self.layers: layer.reset_parameters() self.norm.reset_parameters() def forward(self, input_ids: Tensor, attn_mask: Tensor) -> Tensor: # Convert input token IDs to embeddings hidden_states = self.embed_tokens(input_ids) # Process through all transformer layers, then the final norm layer for layer in self.layers: hidden_states = layer(hidden_states, rope=self.rotary_emb, attn_mask=attn_mask) hidden_states = self.norm(hidden_states) # Return the final hidden states return hidden_states class LlamaForPretraining(nn.Module): def __init__(self, config: LlamaConfig) -> None: super().__init__() self.base_model = LlamaModel(config) self.lm_head = nn.Linear(config.hidden_size, config.vocab_size, bias=False) def reset_parameters(self): self.base_model.reset_parameters() self.lm_head.reset_parameters() def forward(self, input_ids: Tensor, attn_mask: Tensor) -> Tensor: hidden_states = self.base_model(input_ids, attn_mask) return self.lm_head(hidden_states) def create_causal_mask(batch: Tensor, dtype: torch.dtype = torch.float32) -> Tensor: “”“Create a causal mask for self-attention. Args: batch: Batch of sequences, shape (batch_size, seq_len) dtype: Data type of the mask Returns: Causal mask of shape (seq_len, seq_len) ““” batch_size, seq_len = batch.shape mask = torch.full((seq_len, seq_len), float(“-inf”), device=batch.device, dtype=dtype) \ .triu(diagonal=1) return mask def create_padding_mask(batch: Tensor, padding_token_id: int, dtype: torch.dtype = torch.float32) -> Tensor: “”“Create a padding mask for a batch of sequences for self-attention. Args: batch: Batch of sequences, shape (batch_size, seq_len) padding_token_id: ID of the padding token dtype: Data type of the mask Returns: Padding mask of shape (batch_size, 1, seq_len, seq_len) ““” padded

Realme 16 Pro Series India Launch Confirmed: Check Expected Prices, Colours, And Key Specs | Technology News
Realme 16 Pro: The Realme 16 Pro series is set to launch in India in the first week of January 2026, and ahead of the official announcement, details about its pricing and variants have surfaced online. The lineup includes the Realme 16 Pro 5G and the Realme 16 Pro+ 5G, along with the upcoming Realme Pad 3 5G. While Realme has confirmed the launch date, pricing details are yet to be officially announced. Expected Prices and Storage Variants According to information shared by tech blogger Paras Guglani, the Realme 16 Pro 5G is expected to start at Rs 31,999 for the base variant with 8GB RAM and 128GB storage. The 8GB RAM + 256GB storage model will likely cost Rs 33,999, while the top variant with 12GB RAM and 256GB storage may be priced at Rs 36,999. Add Zee News as a Preferred Source For the Realme 16 Pro+ 5G, the leaked pricing suggests a starting price of Rs 39,999 for the 8GB RAM + 128GB storage version. The 8GB RAM + 256GB variant is expected to be priced at Rs 41,999, while the top-end model with 12GB RAM and 256GB storage could cost Rs 44,999. Reports also suggest that buyers may receive additional merchandise when purchasing the phone offline. (Also Read: New Year’s Eve Tech Tip: How You Place Your Smartphone On Table Can Improve Privacy, Focus, Battery, And Mental Peace-Explained) Launch Timeline and Availability The Realme 16 Pro series is scheduled to launch in India on January 6, 2026. The smartphones will be sold through Flipkart and the Realme India online store. They will be available in Master Gold and Master Grey colour options and feature the brand’s new “Urban Wild” design language. Key Specifications Both smartphones in the series are confirmed to feature a large 7,000mAh Titan battery. The camera setup will include a LumaColor Image-powered triple rear camera system, led by a 200-megapixel primary sensor. The Realme 16 Pro+ 5G will be powered by the Snapdragon 7 Gen 4 chipset, while the Realme 16 Pro 5G will use the MediaTek Dimensity 7300-Max processor. As of now, Realme has not officially confirmed the leaked prices, and the final details are expected to be revealed at the official launch event.

OPPO Pad 5 Officially Confirmed To Launch In India Alongside OPPO Reno 15 Series; Check Expected Display, Camera, Price, And Other Specs | Technology News
OPPO Pad 5 Price In India: Chinese smartphone brand OPPO has confirmed that it will soon launch the OPPO Pad 5 in India. The tablet’s India debut was spotted on a Flipkart microsite created for the upcoming OPPO Reno 15 series, where the OPPO Pad 5 is mentioned at the bottom. While OPPO has not officially announced the launch date yet, the listing strongly hints that the tablet will arrive alongside or around the Reno 15 series launch. The OPPO Pad 5 has already been introduced in China, giving users an early idea of what to expect. In India, the Android tablet is likely to be available in Black and Pink colour options, although OPPO has not revealed the official names of these shades so far. OPPO Pad 5 Specifications (Expected) Add Zee News as a Preferred Source The OPPO Pad 5 is expected to sport a large 12.1-inch LCD display with an adaptive 120Hz refresh rate, going up to 144Hz for smoother visuals. The Android tablet could be powered by the MediaTek Dimensity 9400+ chipset, paired with up to 16GB of RAM and 512GB of internal storage for seamless multitasking. The tablet is likely to pack a massive 10,050mAh battery with 67W fast charging support, ensuring longer usage with quicker top-ups. On the software front, the OPPO Pad 5 is expected to run ColorOS 16 based on Android 16. For photography and video calls, it may feature an 8MP camera on both the front and rear. OPPO Pad 5 Price in India (Expected) In China, the OPPO Pad 5 is priced fromCNY 2,599 (around Rs. 32,000) for the base variant, while the top-end model costs nearly Rs. 44,000. If OPPO follows similar pricing in India, the tablet will rival the Samsung Galaxy Tab S10 FE and the Apple iPad.

Train Your Large Model on Multiple GPUs with Tensor Parallelism
import dataclasses import datetime import os import datasets import tokenizers import torch import torch.distributed as dist import torch.nn as nn import torch.nn.functional as F import torch.optim.lr_scheduler as lr_scheduler import tqdm from torch import Tensor from torch.distributed.checkpoint import load, save from torch.distributed.checkpoint.default_planner import DefaultLoadPlanner from torch.distributed.fsdp import FSDPModule, fully_shard from torch.distributed.tensor import Replicate, Shard from torch.distributed.tensor.parallel import ( ColwiseParallel, PrepareModuleInput, RowwiseParallel, SequenceParallel, loss_parallel, parallelize_module, ) from torch.utils.data.distributed import DistributedSampler # Set default to bfloat16 torch.set_default_dtype(torch.bfloat16) print(“NCCL version:”, torch.cuda.nccl.version()) # Build the model @dataclasses.dataclass class LlamaConfig: “”“Define Llama model hyperparameters.”“” vocab_size: int = 50000 # Size of the tokenizer vocabulary max_position_embeddings: int = 2048 # Maximum sequence length hidden_size: int = 768 # Dimension of hidden layers intermediate_size: int = 4*768 # Dimension of MLP’s hidden layer num_hidden_layers: int = 12 # Number of transformer layers num_attention_heads: int = 12 # Number of attention heads num_key_value_heads: int = 3 # Number of key-value heads for GQA class RotaryPositionEncoding(nn.Module): “”“Rotary position encoding.”“” def __init__(self, dim: int, max_position_embeddings: int) -> None: “”“Initialize the RotaryPositionEncoding module. Args: dim: The hidden dimension of the input tensor to which RoPE is applied max_position_embeddings: The maximum sequence length of the input tensor ““” super().__init__() self.dim = dim self.max_position_embeddings = max_position_embeddings # compute a matrix of n\theta_i N = 10_000.0 inv_freq = 1.0 / (N ** (torch.arange(0, dim, 2) / dim)) inv_freq = torch.cat((inv_freq, inv_freq), dim=–1) position = torch.arange(max_position_embeddings) sinusoid_inp = torch.outer(position, inv_freq) # save cosine and sine matrices as buffers, not parameters self.register_buffer(“cos”, sinusoid_inp.cos()) self.register_buffer(“sin”, sinusoid_inp.sin()) def forward(self, x: Tensor) -> Tensor: “”“Apply RoPE to tensor x. Args: x: Input tensor of shape (batch_size, seq_length, num_heads, head_dim) Returns: Output tensor of shape (batch_size, seq_length, num_heads, head_dim) ““” batch_size, seq_len, num_heads, head_dim = x.shape device = x.device dtype = x.dtype # transform the cosine and sine matrices to 4D tensor and the same dtype as x cos = self.cos.to(device, dtype)[:seq_len].view(1, seq_len, 1, –1) sin = self.sin.to(device, dtype)[:seq_len].view(1, seq_len, 1, –1) # apply RoPE to x x1, x2 = x.chunk(2, dim=–1) rotated = torch.cat((–x2, x1), dim=–1) output = (x * cos) + (rotated * sin) return output class LlamaAttention(nn.Module): “”“Grouped-query attention with rotary embeddings.”“” def __init__(self, config: LlamaConfig) -> None: super().__init__() self.hidden_size = config.hidden_size self.num_heads = config.num_attention_heads self.head_dim = self.hidden_size // self.num_heads self.num_kv_heads = config.num_key_value_heads # GQA: H_kv < H_q # hidden_size must be divisible by num_heads assert (self.head_dim * self.num_heads) == self.hidden_size # Linear layers for Q, K, V projections self.q_proj = nn.Linear(self.hidden_size, self.num_heads * self.head_dim, bias=False) self.k_proj = nn.Linear(self.hidden_size, self.num_kv_heads * self.head_dim, bias=False) self.v_proj = nn.Linear(self.hidden_size, self.num_kv_heads * self.head_dim, bias=False) self.o_proj = nn.Linear(self.num_heads * self.head_dim, self.hidden_size, bias=False) def forward(self, hidden_states: Tensor, rope: RotaryPositionEncoding, attn_mask: Tensor) -> Tensor: bs, seq_len, dim = hidden_states.size() # Project inputs to Q, K, V query_states = self.q_proj(hidden_states).view(bs, seq_len, self.num_heads, self.head_dim) key_states = self.k_proj(hidden_states).view(bs, seq_len, self.num_kv_heads, self.head_dim) value_states = self.v_proj(hidden_states).view(bs, seq_len, self.num_kv_heads, self.head_dim) # Apply rotary position embeddings query_states = rope(query_states) key_states = rope(key_states) # Transpose tensors from BSHD to BHSD dimension for scaled_dot_product_attention query_states = query_states.transpose(1, 2) key_states = key_states.transpose(1, 2) value_states = value_states.transpose(1, 2) # Use PyTorch’s optimized attention implementation # setting is_causal=True is incompatible with setting explicit attention mask attn_output = F.scaled_dot_product_attention( query_states, key_states, value_states, attn_mask=attn_mask, dropout_p=0.0, enable_gqa=True, ) # Transpose output tensor from BHSD to BSHD dimension, reshape to 3D, and then project output attn_output = attn_output.transpose(1, 2).reshape(bs, seq_len, self.hidden_size) attn_output = self.o_proj(attn_output) return attn_output class LlamaMLP(nn.Module): “”“Feed-forward network with SwiGLU activation.”“” def __init__(self, config: LlamaConfig) -> None: super().__init__() # Two parallel projections for SwiGLU self.gate_proj = nn.Linear(config.hidden_size, config.intermediate_size, bias=False) self.up_proj = nn.Linear(config.hidden_size, config.intermediate_size, bias=False) self.act_fn = F.silu # SwiGLU activation function # Project back to hidden size self.down_proj = nn.Linear(config.intermediate_size, config.hidden_size, bias=False) def forward(self, x: Tensor) -> Tensor: # SwiGLU activation: multiply gate and up-projected inputs gate = self.act_fn(self.gate_proj(x)) up = self.up_proj(x) return self.down_proj(gate * up) class LlamaDecoderLayer(nn.Module): “”“Single transformer layer for a Llama model.”“” def __init__(self, config: LlamaConfig) -> None: super().__init__() self.input_layernorm = nn.RMSNorm(config.hidden_size, eps=1e–5) self.self_attn = LlamaAttention(config) self.post_attention_layernorm = nn.RMSNorm(config.hidden_size, eps=1e–5) self.mlp = LlamaMLP(config) def forward(self, hidden_states: Tensor, rope: RotaryPositionEncoding, attn_mask: Tensor) -> Tensor: # First residual block: Self-attention residual = hidden_states hidden_states = self.input_layernorm(hidden_states) attn_outputs = self.self_attn(hidden_states, rope=rope, attn_mask=attn_mask) hidden_states = attn_outputs + residual # Second residual block: MLP residual = hidden_states hidden_states = self.post_attention_layernorm(hidden_states) hidden_states = self.mlp(hidden_states) + residual return hidden_states class LlamaModel(nn.Module): “”“The full Llama model without any pretraining heads.”“” def __init__(self, config: LlamaConfig) -> None: super().__init__() self.rotary_emb = RotaryPositionEncoding( config.hidden_size // config.num_attention_heads, config.max_position_embeddings, ) self.embed_tokens = nn.Embedding(config.vocab_size, config.hidden_size) self.layers = nn.ModuleList([ LlamaDecoderLayer(config) for _ in range(config.num_hidden_layers) ]) self.norm = nn.RMSNorm(config.hidden_size, eps=1e–5) def forward(self, input_ids: Tensor, attn_mask: Tensor) -> Tensor: # Convert input token IDs to embeddings hidden_states = self.embed_tokens(input_ids) # Process through all transformer layers, then the final norm layer for layer in self.layers: hidden_states = layer(hidden_states, rope=self.rotary_emb, attn_mask=attn_mask) hidden_states = self.norm(hidden_states) # Return the final hidden states return hidden_states class LlamaForPretraining(nn.Module): def __init__(self, config: LlamaConfig) -> None: super().__init__() self.base_model = LlamaModel(config) self.lm_head = nn.Linear(config.hidden_size, config.vocab_size, bias=False) def forward(self, input_ids: Tensor, attn_mask: Tensor) -> Tensor: hidden_states = self.base_model(input_ids, attn_mask) return self.lm_head(hidden_states) def create_causal_mask(batch: Tensor, dtype: torch.dtype = torch.float32) -> Tensor: “”“Create a causal mask for self-attention. Args: batch: Batch of sequences, shape (batch_size, seq_len) dtype: Data type of the mask Returns: Causal mask of shape (seq_len, seq_len) ““” batch_size, seq_len = batch.shape mask = torch.full((seq_len, seq_len), float(“-inf”), device=batch.device, dtype=dtype) \ .triu(diagonal=1) return mask def create_padding_mask(batch: Tensor, padding_token_id: int, dtype: torch.dtype = torch.float32) -> Tensor: “”“Create a padding mask for a batch of sequences for self-attention. Args: batch: Batch of sequences, shape (batch_size, seq_len) padding_token_id: ID of the padding token dtype: Data type of the mask Returns: Padding mask of shape (batch_size, 1, seq_len, seq_len) ““” padded = torch.zeros_like(batch, device=batch.device, dtype=dtype) \ .masked_fill(batch == padding_token_id, float(“-inf”)) mask = padded[:,:,None] + padded[:,None,:] return mask[:, None, :, :] # Generator function to create padded sequences of

Elon Musk’s xAI To Expand Computing Capacity To 2 GW | Technology News
New Delhi: Tesla and SpaceX CEO Elon Musk’s xAI company has purchased a third building near its existing Memphis sites in the US, that will bring its artificial intelligence (AI) computing capacity to almost 2 gigawatts (GW). Elon Musk has already built one data centre in Memphis, known as Colossus, and is constructing a second centre nearby dubbed Colossus 2, according to multiple reports. The newly acquired building is in Southaven, Mississippi, and adjoins the Colossus 2 facility, according to reports citing people familiar with the matter. “xAI has bought a third building called Macrohardrr,” Musk posted on social media platform X, saying it will “take @xAI training compute to almost 2GW.” A gigawatt is enough to provide electricity for about 7,50,000 US homes. Musk has publicly discussed plans to build the world’s largest data centre for AI training and previously said Colossus 2 will eventually have 5,50,000 chips from Nvidia, costing tens of billions of dollars. Add Zee News as a Preferred Source Moreover, Musk’s xAI Holdings is reportedly in talks to raise new funding at around $230 billion valuation. Musk owns a 53 per cent stake in xAI Holdings, worth $60 billion. Elon Musk took a dig at Wikipedia in October, claiming Grokipedia, developed by xAI, will surpass the popular online encyclopedia “by several orders of magnitude in breadth, depth and accuracy.” Grokipedia is an AI-powered encyclopedia that aims to challenge what Musk calls a “woke” and biased Wikipedia. He described Grokipedia as a “massive improvement over Wikipedia” and said it aligns with xAI’s mission to help humanity better understand the universe. Musk’s net worth rose to nearly $750 billion after a US court reinstated Tesla stock options worth $139 billion. According to Forbes’ billionaires index, this development has taken Musk closer to become the world’s first trillionaire.

New Year’s Eve Tech Tip: How You Place Your Smartphone On Table Can Improve Privacy, Focus, Battery, And Mental Peace-Explained | Technology News
Face Down Phone Benefits: As we celebrate New Year’s Eve and spend time with family and friends, smartphones have become an important part of our daily lives. Whether we are working, attending meetings, eating, or enjoying moments with loved ones, our phone is usually kept right in front of us. However, one small thing is often ignored. Should the phone be kept with the screen facing up or down? This small habit may look not crucial, but it directly affects our concentration, peace of mind, privacy, and digital health. Today, keeping the phone screen facing up has become a common mistake. It causes many problems without us even noticing them. Your Privacy Is At Risk When Screen Faces Up Add Zee News as a Preferred Source When your phone is kept with the screen facing up, it can show your private information without you knowing it. Bank messages, OTPs, personal chats, or office notifications can be seen by people sitting nearby. Many times, we do not even notice what appeared on the screen or who may have seen it. Keeping the phone face down removes this risk immediately. At a time when digital privacy is becoming more important, this simple habit helps keep your personal information safe without any extra effort. Notifications Make It Hard to Concentrate One of the biggest strengths of a smartphone is notifications, but they can also become its biggest weakness. When the screen is facing up, every vibration or flash of light pulls your attention. Even if you do not plan to check the phone, your mind automatically shifts toward it. Keeping the phone face down removes this visual distraction and helps you stay focused on work, conversations, or studies. Over time, this habit teaches your brain that not every alert needs immediate attention. (Also Read: Moto G-Series Smartphone Users Alarmed After Device Reportedly Bursts Into Flames; User Slams Nehru Place Service Centre | Viral Video) How Screen Position Affects Your Mind When a phone keeps lighting up in front of you, your mind stays in alert mode all the time. This can make you feel tired and restless. Keeping the phone face down tells your brain that the phone is not important at that moment. As a result, you feel more calm and relaxed. Whether you are with your family or sitting alone, this habit helps you pay more attention to what is happening around you. Why Keeping the Phone Face Down Is Safer The screen and camera are the most costly and sensitive parts of a smartphone. When the phone is kept with the screen facing up, water drops, tea or coffee, and food pieces can fall on it. The camera lens can also get damaged slowly by rubbing against the table. Keeping the phone face down protects both the screen and the camera. It also lowers the chance of the phone slipping or falling, especially on smooth tables. How Face-Down Phone Saves Your Battery Every time the phone screen lights up and you unlock it, the battery gets used a little. When the phone is kept face down, notifications are less tempting, so you pick up the phone less often. This helps reduce screen time, makes the battery last longer, and puts less strain on your eyes. It also gives a small but healthy break to both the phone and the user. Focus on Real Life, Not Your Phone By keeping your phone face down, you take control instead of letting the phone control you. It also shows the people around you that you are giving them your full attention. Slowly, you start paying more attention to real-life moments instead of constant phone distractions. This balance is the key to a healthy digital life, where technology helps you instead of taking over.

