
Access Denied You don’t have permission to access “http://zeenews.india.com/technology/how-to-use-whatsapp-on-two-phones-with-same-number-a-step-by-step-guide-3037478.html” on this server. Reference #18.c4f43717.1776230559.ba3981b5 https://errors.edgesuite.net/18.c4f43717.1776230559.ba3981b5

Top 5 Reranking Models to Improve RAG Results
In this article, you will learn how reranking improves the relevance of results in retrieval-augmented generation (RAG) systems by going beyond what retrievers alone can achieve. Topics we will cover include: How rerankers refine retriever outputs to deliver better answers Five top reranker models to test in 2026 Final thoughts on choosing the right reranker for your system Let’s get started. Top 5 Reranking Models to Improve RAG ResultsImage by Editor Introduction If you have worked with retrieval-augmented generation (RAG) systems, you have probably seen this problem. Your retriever brings back “relevant” chunks, but many of them are not actually useful. The final answer ends up noisy, incomplete, or incorrect. This usually happens because the retriever is optimized for speed and recall, not precision. That is where reranking comes in. Reranking is the second step in a RAG pipeline. First, your retriever fetches a set of candidate chunks. Then, a reranker evaluates the query and each candidate and reorders them based on deeper relevance. In simple terms: Retriever → gets possible matches Reranker → picks the best matches This small step often makes a big difference. You get fewer irrelevant chunks in your prompt, which leads to better answers from your LLM. Benchmarks like MTEB, BEIR, and MIRACL are commonly used to evaluate these models, and most modern RAG systems rely on rerankers for production-quality results. There is no single best reranker for every use case. The right choice depends on your data, latency, cost constraints, and context length requirements. If you are starting fresh in 2026, these are the five models to test first. 1. Qwen3-Reranker-4B If I had to pick one open reranker to test first, it would be Qwen3-Reranker-4B. The model is open-sourced under Apache 2.0, supports 100+ languages, and has a 32k context length. It shows very strong published reranking results (69.76 on MTEB-R, 75.94 on CMTEB-R, 72.74 on MMTEB-R, 69.97 on MLDR, and 81.20 on MTEB-Code). It performs well across different types of data, including multiple languages, long documents, and code. 2. NVIDIA nv-rerankqa-mistral-4b-v3 For question-answering RAG over text passages, nv-rerankqa-mistral-4b-v3 is a solid, benchmark-backed choice. It delivers high ranking accuracy across evaluated datasets, with an average Recall@5 of 75.45% when paired with NV-EmbedQA-E5-v5 across NQ, HotpotQA, FiQA, and TechQA. It is commercially ready. The main limitation is context size (512 tokens per pair), so it works best with clean chunking. 3. Cohere rerank-v4.0-pro For a managed, enterprise-friendly option, rerank-v4.0-pro is designed as a quality-focused reranker with 32k context, multilingual support across 100+ languages, and support for semi-structured JSON documents. It is suitable for production data such as tickets, CRM records, tables, or metadata-rich objects. 4. jina-reranker-v3 Most rerankers score each document independently. jina-reranker-v3 uses listwise reranking, processing up to 64 documents together in a 131k-token context window, achieving 61.94 nDCG@10 on BEIR. This approach is useful for long-context RAG, multilingual search, and retrieval tasks where relative ordering matters. It is published under CC BY-NC 4.0. 5. BAAI bge-reranker-v2-m3 Not every strong reranker needs to be new. bge-reranker-v2-m3 is lightweight, multilingual, easy to deploy, and fast at inference. It is a practical baseline. If a newer model does not significantly outperform BGE, the added cost or latency may not be justified. Final Thoughts Reranking is a simple yet powerful way to improve a RAG system. A good retriever gets you close. A good reranker gets you to the right answer. In 2026, adding a reranker is essential. Here is a shortlist of recommendations: Feature Description Best open model Qwen3-Reranker-4B Best for QA pipelines NVIDIA nv-rerankqa-mistral-4b-v3 Best managed option Cohere rerank-v4.0-pro Best for long context jina-reranker-v3 Best baseline BGE-reranker-v2-m3 This selection provides a strong starting point. Your specific use case and system constraints should guide the final choice. About Kanwal Mehreen Kanwal Mehreen is an aspiring Software Developer with a keen interest in data science and applications of AI in medicine. Kanwal was selected as the Google Generation Scholar 2022 for the APAC region. Kanwal loves to share technical knowledge by writing articles on trending topics, and is passionate about improving the representation of women in tech industry.
Access Denied
Access Denied You don’t have permission to access “http://zeenews.india.com/technology/world-quantum-day-2026-why-is-it-celebrated-history-significance-purpose-all-you-need-to-know-3037141.html” on this server. Reference #18.c4f43717.1776167909.b0f5cd28 https://errors.edgesuite.net/18.c4f43717.1776167909.b0f5cd28
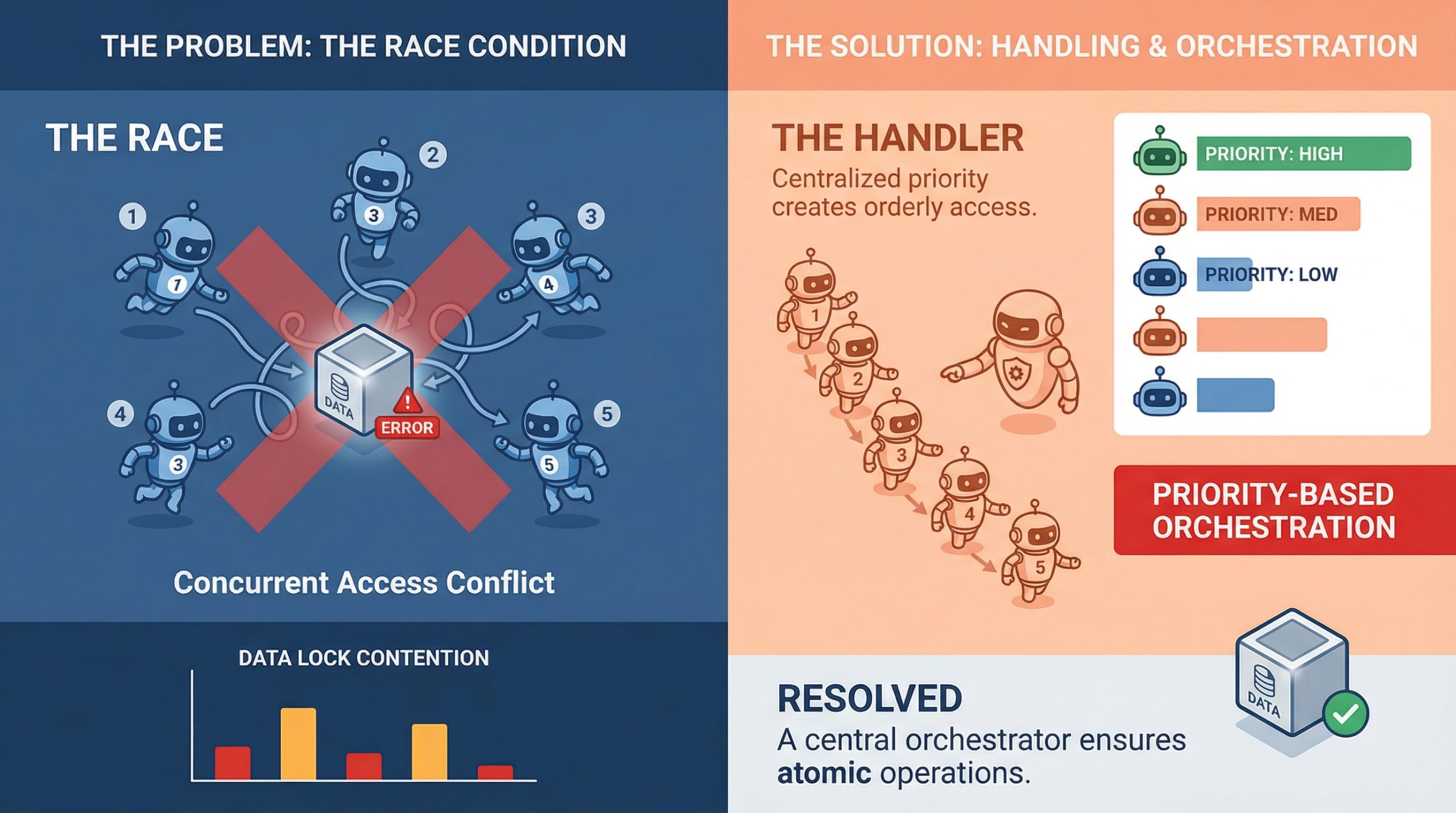
Handling Race Conditions in Multi-Agent Orchestration
In this article, you will learn how to identify, understand, and mitigate race conditions in multi-agent orchestration systems. Topics we will cover include: What race conditions look like in multi-agent environments Architectural patterns for preventing shared-state conflicts Practical strategies like idempotency, locking, and concurrency testing Let’s get straight to it. Handling Race Conditions in Multi-Agent OrchestrationImage by Editor If you’ve ever watched two agents confidently write to the same resource at the same time and produce something that makes zero sense, you already know what a race condition feels like in practice. It’s one of those bugs that doesn’t show up in unit tests, behaves perfectly in staging, and then detonates in production during your highest-traffic window. In multi-agent systems, where parallel execution is the whole point, race conditions aren’t edge cases. They’re expected guests. Understanding how to handle them is less about being defensive and more about building systems that assume chaos by default. What Race Conditions Actually Look Like in Multi-Agent Systems A race condition happens when two or more agents try to read, modify, or write shared state at the same time, and the final result depends on which one gets there first. In a single-agent pipeline, that’s manageable. In a system with five agents running concurrently, it’s a genuinely different problem. The tricky part is that race conditions aren’t always obvious crashes. Sometimes they’re silent. Agent A reads a document, Agent B updates it half a second later, and Agent A writes back a stale version with no error thrown anywhere. The system looks fine. The data is compromised. What makes this worse in machine learning pipelines specifically is that agents often work on mutable shared objects, whether that’s a shared memory store, a vector database, a tool output cache, or a simple task queue. Any of these can become a contention point when multiple agents start pulling from them simultaneously. Why Multi-Agent Pipelines Are Especially Vulnerable Traditional concurrent programming has decades of tooling around race conditions: threads, mutexes, semaphores, and atomic operations. Multi-agent large language model (LLM) systems are newer, and they are often built on top of async frameworks, message brokers, and orchestration layers that don’t always give you fine-grained control over execution order. There’s also the problem of non-determinism. LLM agents don’t always take the same amount of time to complete a task. One agent might finish in 200ms, while another takes 2 seconds, and the orchestrator has to handle that gracefully. When it doesn’t, agents start stepping on each other, and you end up with a corrupted state or conflicting writes that the system silently accepts. Agent communication patterns matter a lot here, too. If agents are sharing state through a central object or a shared database row rather than passing messages, they are almost guaranteed to run into write conflicts at scale. This is as much a design pattern issue as it is a concurrency issue, and fixing it usually starts at the architecture level before you even touch the code. Locking, Queuing, and Event-Driven Design The most direct way to handle shared resource contention is through locking. Optimistic locking works well when conflicts are rare: each agent reads a version tag alongside the data, and if the version has changed by the time it tries to write, the write fails and retries. Pessimistic locking is more aggressive and reserves the resource before reading. Both approaches have trade-offs, and which one fits depends on how often your agents are actually colliding. Queuing is another solid approach, especially for task assignment. Instead of multiple agents polling a shared task list directly, you push tasks into a queue and let agents consume them one at a time. Systems like Redis Streams, RabbitMQ, or even a basic Postgres advisory lock can handle this well. The queue becomes your serialization point, which takes the race out of the equation for that particular access pattern. Event-driven architectures go further. Rather than agents reading from shared state, they react to events. Agent A completes its work and emits an event. Agent B listens for that event and picks up from there. This creates looser coupling and naturally reduces the overlap window where two agents might be modifying the same thing at once. Idempotency Is Your Best Friend Even with solid locking and queuing in place, things still go wrong. Networks hiccup, timeouts happen, and agents retry failed operations. If those retries are not idempotent, you will end up with duplicate writes, double-processed tasks, or compounding errors that are painful to debug after the fact. Idempotency means that running the same operation multiple times produces the same result as running it once. For agents, that often means including a unique operation ID with every write. If the operation has already been applied, the system recognizes the ID and skips the duplicate. It’s a small design choice with a significant impact on reliability. It’s worth building idempotency in from the start at the agent level. Retrofitting it later is painful. Agents that write to databases, update records, or trigger downstream workflows should all carry some form of deduplication logic, because it makes the whole system more resilient to the messiness of real-world execution. Testing for Race Conditions Before They Test You The hard part about race conditions is reproducing them. They are timing-dependent, which means they often only appear under load or in specific execution sequences that are difficult to reproduce in a controlled test environment. One useful approach is stress testing with intentional concurrency. Spin up multiple agents against a shared resource simultaneously and observe what breaks. Tools like Locust, pytest-asyncio with concurrent tasks, or even a simple ThreadPoolExecutor can help simulate the kind of overlapping execution that exposes contention bugs in staging rather than production. Property-based testing is underused in this context. If you can define invariants that should always hold regardless of execution order, you can run randomized tests that attempt to violate them. It won’t catch everything, but it will surface many of the
Access Denied
Access Denied You don’t have permission to access “http://zeenews.india.com/technology/how-to-solve-smartphone-lagging-problems-here-are-5-simple-tips-to-fix-it-3035998.html” on this server. Reference #18.eff43717.1776122794.83144fe2 https://errors.edgesuite.net/18.eff43717.1776122794.83144fe2
Access Denied
Access Denied You don’t have permission to access “http://zeenews.india.com/technology/infinix-note-60-pro-launched-in-india-price-features-camera-battery-and-all-you-need-to-know-3036994.html” on this server. Reference #18.c4f43717.1776090862.a4a25aa2 https://errors.edgesuite.net/18.c4f43717.1776090862.a4a25aa2
Access Denied
Access Denied You don’t have permission to access “http://zeenews.india.com/technology/whatsapp-for-carplay-launched-key-features-and-uses-how-it-benefits-drivers-and-passengers-3036253.html” on this server. Reference #18.c4f43717.1776062548.9f944c18 https://errors.edgesuite.net/18.c4f43717.1776062548.9f944c18
Access Denied
Access Denied You don’t have permission to access “http://zeenews.india.com/technology/samsung-to-discontinue-samsung-messages-app-in-july-2026-urges-switch-to-google-messages-3036504.html” on this server. Reference #18.c4f43717.1776004228.970d1bf2 https://errors.edgesuite.net/18.c4f43717.1776004228.970d1bf2
Access Denied
Access Denied You don’t have permission to access “http://zeenews.india.com/technology/what-is-the-length-of-your-smartphone-charging-cable-iphone-vs-android-is-there-a-difference-3036294.html” on this server. Reference #18.c4f43717.1775983887.91f69cfc https://errors.edgesuite.net/18.c4f43717.1775983887.91f69cfc
Access Denied
Access Denied You don’t have permission to access “http://zeenews.india.com/technology/google-ai-features-you-can-now-book-restaurant-tables-from-search-bar-check-how-it-works-3036021.html” on this server. Reference #18.c4f43717.1775917569.87795687 https://errors.edgesuite.net/18.c4f43717.1775917569.87795687

