

With more people relying on the internet while travelling, Wi-Fi on trains has become an important facility for passengers. Many wonder how internet works on a moving train and whether high speed—sometimes above 100 kmph affects the connection. Here’s a simple explanation of how train Wi-Fi works and which trains currently offer this service. How Train Wi-Fi Works? Train Wi-Fi does not come from satellites directly to passengers’ phones. Instead, trains are fitted with special routers and antennas on the roof. These antennas connect to nearby mobile towers using 4G or 5G networks, just like a mobile phone does. Add Zee News as a Preferred Source Inside the train, this signal is distributed to passengers through internal Wi-Fi routers installed in coaches. The system automatically switches between mobile towers as the train moves, ensuring continuous internet access. This process is known as “handover” and happens within seconds. Does Internet Stop at High Speeds? Even at speeds of 100–130 kmph, Wi-Fi generally continues to work. Modern mobile networks are designed to support fast-moving users, such as those in trains or cars. However, brief slowdowns or disconnections can happen while passing through tunnels, remote areas, forests, or regions with weak network coverage. Internet speed may also reduce when many passengers are connected at the same time, especially during peak travel hours. (Also Read: New Year’s Eve Tech Tip: How You Place Your Smartphone On Table Can Improve Privacy, Focus, Battery, And Mental Peace-Explained) Which Trains Offer Wi-Fi in India? Indian Railways provides Wi-Fi services under the RailWire program, operated by RailTel. Free Wi-Fi is available at over 6,000 railway stations across the country. Some premium trains and routes also offer onboard Wi-Fi, including: Vande Bharat Express Shatabdi Express Rajdhani Express Gatimaan Express Selected Tejas Express routes Future of Train Connectivity Indian Railways is working to expand onboard Wi-Fi and improve signal strength using advanced LTE and upcoming 5G technologies. The goal is to offer smoother internet access for work, entertainment, and communication during long journeys.

Training a Tokenizer for Llama Model
The Llama family of models are large language models released by Meta (formerly Facebook). These decoder-only transformer models are used for generation tasks. Almost all decoder-only models nowadays use the Byte-Pair Encoding (BPE) algorithm for tokenization. In this article, you will learn about BPE. In particular, you will learn: What BPE is compared to other tokenization algorithms How to prepare a dataset and train a BPE tokenizer How to use the tokenizer Training a Tokenizer for Llama ModelPhoto by Joss Woodhead. Some rights reserved. Let’s get started. Overview This article is divided into four parts; they are: Understanding BPE Training a BPE tokenizer with Hugging Face tokenizers library Training a BPE tokenizer with SentencePiece library Training a BPE tokenizer with tiktoken library Understanding BPE Byte-Pair Encoding (BPE) is a tokenization algorithm used to tokenize text into sub-word units. Instead of splitting text into only words and punctuation, BPE can further split the prefixes and suffixes of words so that prefixes, stems, and suffixes can each be associated with meaning in the language model. Without sub-word tokenization, a language model would find it difficult to learn that “happy” and “unhappy” are antonyms of each other. BPE is not the only sub-word tokenization algorithm. WordPiece, which is the default for BERT, is another one. A well-implemented BPE does not need “unknown” in the vocabulary, and nothing is OOV (Out of Vocabulary) in BPE. This is because BPE can start with 256 byte values (hence known as byte-level BPE) and then merge the most frequent pairs of tokens into a new vocabulary until the desired vocabulary size is reached. Nowadays, BPE is the tokenization algorithm of choice for most decoder-only models. However, you do not want to implement your own BPE tokenizer from scratch. Instead, you can use tokenizer libraries such as Hugging Face’s tokenizers, OpenAI’s tiktoken, or Google’s sentencepiece. Training a BPE tokenizer with Hugging Face tokenizers Library To train a BPE tokenizer, you need to prepare a dataset so the tokenizer algorithm can determine the most frequent pair of tokens to merge. For decoder-only models, a subset of the model’s training data is usually appropriate. Training a tokenizer is time-consuming, especially for large datasets. However, unlike a language model, a tokenizer does not need to learn the language context of the text, only how often tokens appear in a typical text corpus. While you may need trillions of tokens to train a good language model, you only need a few million tokens to train a good tokenizer. As mentioned in a previous article, there are several well-known text datasets for language model training. For a toy project, you may want a smaller dataset for faster experimentation. The HuggingFaceFW/fineweb dataset is a good choice for this purpose. In its full size, it is a 15 trillion token dataset, but it also has 10B, 100B, and 350B sizes for smaller projects. The dataset is derived from Common Crawl and filtered by Hugging Face to improve data quality. Below is how you can print a few samples from the dataset: import datasets dataset = datasets.load_dataset(“HuggingFaceFW/fineweb”, name=”sample-10BT”, split=”train”, streaming=True) count = 0 for sample in dataset: print(sample) count += 1 if count >= 5: break import datasets dataset = datasets.load_dataset(“HuggingFaceFW/fineweb”, name=“sample-10BT”, split=“train”, streaming=True) count = 0 for sample in dataset: print(sample) count += 1 if count >= 5: break Running this code will print the following: {‘text’: ‘|Viewing Single Post From: Spoilers for the Week of February 11th|\n|Lil||F…’, ‘id’: ‘<urn:uuid:39147604-bfbe-4ed5-b19c-54105f8ae8a7>’, ‘dump’: ‘CC-MAIN-2013-20’, ‘url’: ‘http://daytimeroyaltyonline.com/single/?p=8906650&t=8780053’, ‘date’: ‘2013-05-18T05:48:59Z’, ‘file_path’: ‘s3://commoncrawl/crawl-data/CC-MAIN-2013-20/segments/1368696381249/war…’, ‘language’: ‘en’, ‘language_score’: 0.8232095837593079, ‘token_count’: 142} {‘text’: ‘*sigh* Fundamentalist community, let me pass on some advice to you I learne…’, ‘id’: ‘<urn:uuid:ba819eb7-e6e6-415a-87f4-0347b6a4f017>’, ‘dump’: ‘CC-MAIN-2013-20’, ‘url’: ‘http://endogenousretrovirus.blogspot.com/2007/11/if-you-have-set-yourself-on…’, ‘date’: ‘2013-05-18T06:43:03Z’, ‘file_path’: ‘s3://commoncrawl/crawl-data/CC-MAIN-2013-20/segments/1368696381249/war…’, ‘language’: ‘en’, ‘language_score’: 0.9737711548805237, ‘token_count’: 703} … {‘text’: ‘|Viewing Single Post From: Spoilers for the Week of February 11th|\n|Lil||F…’, ‘id’: ‘<urn:uuid:39147604-bfbe-4ed5-b19c-54105f8ae8a7>’, ‘dump’: ‘CC-MAIN-2013-20’, ‘url’: ‘http://daytimeroyaltyonline.com/single/?p=8906650&t=8780053’, ‘date’: ‘2013-05-18T05:48:59Z’, ‘file_path’: ‘s3://commoncrawl/crawl-data/CC-MAIN-2013-20/segments/1368696381249/war…’, ‘language’: ‘en’, ‘language_score’: 0.8232095837593079, ‘token_count’: 142} {‘text’: ‘*sigh* Fundamentalist community, let me pass on some advice to you I learne…’, ‘id’: ‘<urn:uuid:ba819eb7-e6e6-415a-87f4-0347b6a4f017>’, ‘dump’: ‘CC-MAIN-2013-20’, ‘url’: ‘http://endogenousretrovirus.blogspot.com/2007/11/if-you-have-set-yourself-on…’, ‘date’: ‘2013-05-18T06:43:03Z’, ‘file_path’: ‘s3://commoncrawl/crawl-data/CC-MAIN-2013-20/segments/1368696381249/war…’, ‘language’: ‘en’, ‘language_score’: 0.9737711548805237, ‘token_count’: 703} … For training a tokenizer (and even a language model), you only need the text field of each sample. To train a BPE tokenizer using the tokenizers library, you simply feed the text samples to the trainer. Below is the complete code: from typing import Iterator import datasets from tokenizers import Tokenizer, models, trainers, pre_tokenizers, decoders, normalizers # Load FineWeb 10B sample (using only a slice for demo to save memory) dataset = datasets.load_dataset(“HuggingFaceFW/fineweb”, name=”sample-10BT”, split=”train”, streaming=True) def get_texts(dataset: datasets.Dataset, limit: int = 100_000) -> Iterator[str]: “””Get texts from the dataset until the limit is reached or the dataset is exhausted””” count = 0 for sample in dataset: yield sample[“text”] count += 1 if limit and count >= limit: break # Initialize a BPE model: either byte_fallback=True or set unk_token=”[UNK]” tokenizer = Tokenizer(models.BPE(byte_fallback=True)) tokenizer.normalizer = normalizers.NFKC() tokenizer.pre_tokenizer = pre_tokenizers.ByteLevel(add_prefix_space=True, use_regex=False) tokenizer.decoder = decoders.ByteLevel() # Trainer trainer = trainers.BpeTrainer( vocab_size=25_000, min_frequency=2, special_tokens=[“[PAD]”, “[CLS]”, “[SEP]”, “[MASK]”], show_progress=True, ) # Train and save the tokenizer to disk texts = get_texts(dataset, limit=10_000) tokenizer.train_from_iterator(texts, trainer=trainer) tokenizer.save(“bpe_tokenizer.json”) # Reload the tokenizer from disk tokenizer = Tokenizer.from_file(“bpe_tokenizer.json”) # Test: encode/decode text = “Let’s have a pizza party! 🍕” enc = tokenizer.encode(text) print(“Token IDs:”, enc.ids) print(“Decoded:”, tokenizer.decode(enc.ids)) 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 from typing import Iterator import datasets from tokenizers import Tokenizer, models, trainers, pre_tokenizers, decoders, normalizers # Load FineWeb 10B sample (using only a slice for demo to save memory) dataset = datasets.load_dataset(“HuggingFaceFW/fineweb”, name=“sample-10BT”, split=“train”, streaming=True) def get_texts(dataset: datasets.Dataset, limit: int = 100_000) -> Iterator[str]: “”“Get texts from the dataset until the limit is reached or the dataset is exhausted”“” count = 0 for sample in dataset:

Govt Releases White Paper On Democratising Access To AI Infrastructure | Technology News
New Delhi: The Office of the Principal Scientific Adviser (PSA) to the Government on Tuesday released a white paper on democratizing access to Artificial Intelligence (AI) infrastructure. The white paper defines democratising access to AI infrastructure as making the AI infrastructure – compute, datasets, and model ecosystem available and affordable, such that it reaches a wide set of users. It refers to empowering a wide set of users to engage with and benefit from AI capabilities. When compute, datasets, and model tooling are broadly available, individuals and institutions expand what they can do, like aiming to design local language tools and adapt assistive technologies. The white paper has been prepared with inputs and feedback from domain experts and stakeholders, including the Niti Aayog, to foster informed deliberation and action in shaping India’s AI policy and governance landscape. Add Zee News as a Preferred Source “With AI becoming central to innovation and economic progress, access to compute, datasets, and model ecosystems must be made broad, affordable, and inclusive. These resources are concentrated in a few global firms and urban centres, limiting equitable participation,” the office of the PSA said in a post on social media. “For India, democratising access means treating AI infrastructure as a shared national resource, empowering innovators across regions to build local-language tools, adapt assistive technologies, and create solutions aligned with India’s diverse needs,” it added. The white paper highlights key enablers aligned with India’s AI governance vision, including expanding access to high-quality, representative datasets; providing affordable and reliable computing resources; and integrating AI with Digital Public Infrastructure (DPI). Democratising access to AI infrastructure is critical for ensuring fair and equitable opportunities and benefits across the country, from villages to cities, and from small institutions and startups to industry. Through tools and platforms like AIKosha, India AI Compute, and TGDeX, India’s AI ecosystem is supporting innovation and services by increasing access. Further, dedicated government initiatives on infrastructure development and increasing access to data and computing resources would empower the IndiaAI Mission, line ministries, sectoral regulators, and state governments, the white paper said.

Creating a Llama or GPT Model for Next-Token Prediction
import dataclasses import torch import torch.nn as nn import torch.nn.functional as F from torch import Tensor @dataclasses.dataclass class LlamaConfig: “”“Define Llama model hyperparameters.”“” vocab_size: int = 50000 # Size of the tokenizer vocabulary max_position_embeddings: int = 2048 # Maximum sequence length hidden_size: int = 768 # Dimension of hidden layers intermediate_size: int = 4*768 # Dimension of MLP’s hidden layer num_hidden_layers: int = 12 # Number of transformer layers num_attention_heads: int = 12 # Number of attention heads num_key_value_heads: int = 3 # Number of key-value heads for GQA def rotate_half(x: Tensor) -> Tensor: “”“Rotates half the hidden dims of the input. This is a helper function for rotary position embeddings (RoPE). For a tensor of shape (…, d), it returns a tensor where the last d/2 dimensions are rotated by swapping and negating. Args: x: Input tensor of shape (…, d) Returns: Tensor of same shape with rotated last dimension ““” x1, x2 = x.chunk(2, dim=–1) return torch.cat((–x2, x1), dim=–1) # Concatenate with rotation class RotaryPositionEncoding(nn.Module): “”“Rotary position encoding.”“” def __init__(self, dim: int, max_position_embeddings: int) -> None: “”“Initialize the RotaryPositionEncoding module Args: dim: The hidden dimension of the input tensor to which RoPE is applied max_position_embeddings: The maximum sequence length of the input tensor ““” super().__init__() self.dim = dim self.max_position_embeddings = max_position_embeddings # compute a matrix of n\theta_i N = 10_000.0 inv_freq = 1.0 / (N ** (torch.arange(0, dim, 2) / dim)) inv_freq = torch.cat((inv_freq, inv_freq), dim=–1) position = torch.arange(max_position_embeddings) sinusoid_inp = torch.outer(position, inv_freq) # save cosine and sine matrices as buffers, not parameters self.register_buffer(“cos”, sinusoid_inp.cos()) self.register_buffer(“sin”, sinusoid_inp.sin()) def forward(self, x: Tensor) -> Tensor: “”“Apply RoPE to tensor x Args: x: Input tensor of shape (batch_size, seq_length, num_heads, head_dim) Returns: Output tensor of shape (batch_size, seq_length, num_heads, head_dim) ““” batch_size, seq_len, num_heads, head_dim = x.shape dtype = x.dtype # transform the cosine and sine matrices to 4D tensor and the same dtype as x cos = self.cos.to(dtype)[:seq_len].view(1, seq_len, 1, –1) sin = self.sin.to(dtype)[:seq_len].view(1, seq_len, 1, –1) # apply RoPE to x output = (x * cos) + (rotate_half(x) * sin) return output class LlamaAttention(nn.Module): “”“Grouped-query attention with rotary embeddings.”“” def __init__(self, config: LlamaConfig) -> None: super().__init__() self.hidden_size = config.hidden_size self.num_heads = config.num_attention_heads self.head_dim = self.hidden_size // self.num_heads self.num_kv_heads = config.num_key_value_heads # GQA: H_kv < H_q # hidden_size must be divisible by num_heads assert (self.head_dim * self.num_heads) == self.hidden_size # Linear layers for Q, K, V projections self.q_proj = nn.Linear(self.hidden_size, self.num_heads * self.head_dim, bias=False) self.k_proj = nn.Linear(self.hidden_size, self.num_kv_heads * self.head_dim, bias=False) self.v_proj = nn.Linear(self.hidden_size, self.num_kv_heads * self.head_dim, bias=False) self.o_proj = nn.Linear(self.num_heads * self.head_dim, self.hidden_size, bias=False) def forward(self, hidden_states: Tensor, rope: RotaryPositionEncoding, attn_mask: Tensor) -> Tensor: bs, seq_len, dim = hidden_states.size() # Project inputs to Q, K, V query_states = self.q_proj(hidden_states).view(bs, seq_len, self.num_heads, self.head_dim) key_states = self.k_proj(hidden_states).view(bs, seq_len, self.num_kv_heads, self.head_dim) value_states = self.v_proj(hidden_states).view(bs, seq_len, self.num_kv_heads, self.head_dim) # Apply rotary position embeddings query_states = rope(query_states) key_states = rope(key_states) # Transpose tensors from BSHD to BHSD dimension for scaled_dot_product_attention query_states = query_states.transpose(1, 2) key_states = key_states.transpose(1, 2) value_states = value_states.transpose(1, 2) # Use PyTorch’s optimized attention implementation # setting is_causal=True is incompatible with setting explicit attention mask attn_output = F.scaled_dot_product_attention( query_states, key_states, value_states, attn_mask=attn_mask, dropout_p=0.0, enable_gqa=True, ) # Transpose output tensor from BHSD to BSHD dimension, reshape to 3D, and then project output attn_output = attn_output.transpose(1, 2).reshape(bs, seq_len, self.hidden_size) attn_output = self.o_proj(attn_output) return attn_output class LlamaMLP(nn.Module): “”“Feed-forward network with SwiGLU activation.”“” def __init__(self, config: LlamaConfig) -> None: super().__init__() # Two parallel projections for SwiGLU self.gate_proj = nn.Linear(config.hidden_size, config.intermediate_size, bias=False) self.up_proj = nn.Linear(config.hidden_size, config.intermediate_size, bias=False) self.act_fn = F.silu # SwiGLU activation function # Project back to hidden size self.down_proj = nn.Linear(config.intermediate_size, config.hidden_size, bias=False) def forward(self, x: Tensor) -> Tensor: # SwiGLU activation: multiply gate and up-projected inputs gate = self.act_fn(self.gate_proj(x)) up = self.up_proj(x) return self.down_proj(gate * up) class LlamaDecoderLayer(nn.Module): “”“Single transformer layer for a Llama model.”“” def __init__(self, config: LlamaConfig) -> None: super().__init__() self.input_layernorm = nn.RMSNorm(config.hidden_size, eps=1e–5) self.self_attn = LlamaAttention(config) self.post_attention_layernorm = nn.RMSNorm(config.hidden_size, eps=1e–5) self.mlp = LlamaMLP(config) def forward(self, hidden_states: Tensor, rope: RotaryPositionEncoding, attn_mask: Tensor) -> Tensor: # First residual block: Self-attention residual = hidden_states hidden_states = self.input_layernorm(hidden_states) attn_outputs = self.self_attn(hidden_states, rope=rope, attn_mask=attn_mask) hidden_states = attn_outputs + residual # Second residual block: MLP residual = hidden_states hidden_states = self.post_attention_layernorm(hidden_states) hidden_states = self.mlp(hidden_states) + residual return hidden_states class LlamaModel(nn.Module): “”“The full Llama model without any pretraining heads.”“” def __init__(self, config: LlamaConfig) -> None: super().__init__() self.rotary_emb = RotaryPositionEncoding( config.hidden_size // config.num_attention_heads, config.max_position_embeddings, ) self.embed_tokens = nn.Embedding(config.vocab_size, config.hidden_size) self.layers = nn.ModuleList([LlamaDecoderLayer(config) for _ in range(config.num_hidden_layers)]) self.norm = nn.RMSNorm(config.hidden_size, eps=1e–5) def forward(self, input_ids: Tensor, attn_mask: Tensor) -> Tensor: # Convert input token IDs to embeddings hidden_states = self.embed_tokens(input_ids) # Process through all transformer layers, then the final norm layer for layer in self.layers: hidden_states = layer(hidden_states, rope=self.rotary_emb, attn_mask=attn_mask) hidden_states = self.norm(hidden_states) # Return the final hidden states return hidden_states class LlamaForPretraining(nn.Module): def __init__(self, config: LlamaConfig) -> None: super().__init__() self.base_model = LlamaModel(config) self.lm_head = nn.Linear(config.hidden_size, config.vocab_size, bias=False) def forward(self, input_ids: Tensor, attn_mask: Tensor) -> Tensor: hidden_states = self.base_model(input_ids, attn_mask) return self.lm_head(hidden_states) def create_causal_mask(seq_len: int, device: torch.device, dtype: torch.dtype = torch.float32) -> Tensor: “”“Create a causal mask for self-attention. Args: seq_len: Length of the sequence device: Device to create the mask on dtype: Data type of the mask Returns: Causal mask of shape (seq_len, seq_len) ““” mask = torch.full((seq_len, seq_len), float(‘-inf’), device=device, dtype=dtype) \ .triu(diagonal=1) return mask def create_padding_mask(batch, padding_token_id, device: torch.device, dtype: torch.dtype = torch.float32): “”“Create a padding mask for a batch of sequences for self-attention. Args: batch: Batch of sequences, shape (batch_size, seq_len) padding_token_id: ID of the padding token Returns: Padding mask of shape (batch_size, 1, seq_len, seq_len) ““” padded = torch.zeros_like(batch, device=device, dtype=dtype) \ .masked_fill(batch == padding_token_id, float(‘-inf’)) mask = padded[:,:,None] + padded[:,None,:] return mask[:, None, :, :] # Create model with default config model_config = LlamaConfig() device = torch.device(“cuda”) if torch.cuda.is_available() else torch.device(“cpu”)

Moto G-Series Smartphone Users Alarmed After Device Reportedly Bursts Into Flames; User Slams Nehru Place Service Centre | Viral Video | Technology News
Motorola G-Series Phone Blast: What started as a normal day quickly turned scary when a Motorola G-series smartphone reportedly exploded inside a user’s pocket. According to a video shared by a user on X (formerly Twitter), the man was going about his daily routine when he suddenly felt intense heat, followed by a loud burst. Within moments, the phone caught fire and burned a hole in his pants, leaving him shocked and confused. People nearby rushed to help as smoke came out of the damaged device. Thankfully, the user did not suffer any serious injuries, but the incident left him shaken. Images of the burnt Motorola G-series phone later surfaced online, clearly showing the damage. The incident has raised fresh concerns about smartphone battery safety, overheating issues, and the risks of carrying phones in pockets. Notably, the device involved is believed to be the Motorola Moto G54 5G. Another Motorola G-series phone reportedly exploded in a user’s pocket, leaving a hole in the pants. The device was allegedly idle. Source: shubhxr_369 (Instagram) pic.twitter.com/uPXWvnvoUB Abhishek Yadav (@yabhishekhd) December 30, 2025 Add Zee News as a Preferred Source Motorola Service Centre: Worst Experience As per a video posted by a user on X (formerly Twitter), he said that after using the Motorola phone for about 8 to 9 months, the screen suddenly stopped responding. To fix the issue, he visited the Motorola Exclusive Service Centre in Nehru Place, but the experience was very disappointing. The service centre has no lift, making it difficult to access. It is also shared by Motorola and Lenovo, which leads to overcrowding and confusion. Motorola is really going downhill with no brakes… Just look at the condition of their service centers we tested recently…https://t.co/5qKkCTYkt3 SparkNherd (@SparkNherd) December 30, 2025 After taking a token, the user noticed that there was no display screen to show token numbers. The seating arrangement was poor, with only three chairs available. Two chairs were meant for laptop customers and just one for smartphone users. There was no staff member at the service desk, and when someone finally arrived, he did not know the token order and called customers randomly, making the token system meaningless. After completing the paperwork, the user was told on Saturday that he would receive a call on Monday with details about the phone issue. However, no one contacted him even by Thursday, showing a clear lack of coordination and poor customer support. (Also Read: Oppo Reno 15 Pro Mini Price Leaked Ahead Of Official Launch In India; Check Expected Camera, Battery, Display And Other Specs) Moto G54 5G Specifications The smartphone comes with a 6.5-inch LED display that supports a 120Hz refresh rate and offers Full HD+ resolution (2400 x 1080 pixels) for smooth and clear visuals. It is powered by the MediaTek Dimensity 7020 processor, featuring a 2.2GHz octa-core CPU and an IMG BXM-8-256 GPU for everyday performance. The device packs a 6000mAh battery with 33W fast charging support. On the back, it has a dual-camera setup with a 50-megapixel main camera with OIS and an 8-megapixel auto-focus camera, without any extra macro or depth lens. For selfies, it offers a 16-megapixel front camera and runs on Android 13, with an Android 14 update promised later. Moto G54 5G Price In India The Moto G54 5G is available in two variants. The 8GB RAM with 128GB storage model is priced at Rs 15,999, while the 12GB RAM with 256GB storage version costs Rs 18,999.
How AI Cuts Costs and Adds Value for Data Science Workflows (Sponsored)
How AI Cuts Costs and Adds Value for Data Science Workflows (Sponsored)

Apple’s iPhone 17 Pro With 48MP Triple Camera Gets Hefty Discount On THIS Platform; Check Display, Battery And Other Specs | Technology News
iPhone 17 Pro Discount Price In India: As 2025 gets closer to its end, the smartphone market is full of exciting deals. Among them, one phone that truly made a strong impact this year is the Apple iPhone 17 Pro. With its powerful performance and premium design, it stayed in the spotlight all year. Now, as people prepare to say goodbye to 2025, Vijay Sales is offering the iPhone 17 Pro (256 GB Variant) at a hefty discount, giving buyers a great chance to upgrade to Apple’s flagship smartphone. Notably, the smartphone is offered in three different colour options, which include Cosmic Orange, Deep Blue, and Silver. iPhone 17 Pro Discount Price The flagship smartphone is now available on Vijay Sales with a price cut that makes it more tempting for buyers. Originally priced at Rs 1,34,900, the phone is being sold at Rs 1,25,490 after a 7% discount of Rs 9,410. The savings do not stop there. Buyers using an ICICI Bank credit card can get an additional flat discount of Rs 5,000. This extra offer further reduces the final price to Rs 1,20,490, making the premium smartphone easier to buy for those looking for a good deal. (Also Read: New Year 2026 WhatsApp Scams: What Should You Do If Targeted? How To Identify And Stay Safe) Add Zee News as a Preferred Source iPhone 17 Pro Specifications The smartphone features a large 6.3-inch LTPO Super Retina XDR OLED display with a smooth 120Hz refresh rate and an impressive peak brightness of 3,000 nits for clear viewing even in bright light. It is powered by the Apple A19 Pro chipset, paired with a 6-core Apple GPU, delivering fast and reliable performance. The phone runs on iOS 26.2 with the new Liquid Glass theme for a refined user experience. It is powered by a 3,998mAh battery with 25W MagSafe wireless charging keeps it running. On the photography front, the smartphone offers a triple 48MP rear camera setup, including a primary sensor with sensor-shift OIS, an ultra-wide lens, and a periscope telephoto lens with 4x optical zoom, while an 18MP front camera handles selfies. Adding further, the iPhone 17 Pro comes with advanced security and sensor features, led by Face ID powered by TrueDepth technology built into the Center Stage front camera. It is equipped with a LiDAR scanner, barometer, high dynamic range gyro, high-g accelerometer, proximity sensor, and dual ambient light sensors for improved accuracy and performance. The device supports Dual SIM functionality with nano-SIM and eSIM options. For communication, it offers FaceTime audio, VoLTE, Wi-Fi calling, SharePlay, screen sharing, Spatial Audio, and Voice Isolation along with Wide Spectrum microphone modes for clearer calls.

Telecom Security Reforms Announced: DoT Extends Certification, Cuts Testing Fees | Technology News
Telecom Security Reforms: In a significant push to strengthen India’s telecom security ecosystem while easing regulatory burdens on the industry, the Department of Telecommunications (DoT), through the National Centre for Communication Security (NCCS), has rolled out a set of transformative reforms aimed at boosting indigenous manufacturing and testing capabilities, Union Minister of Communications Jyotiraditya Scindia said on Monday. “These transformative reforms will strengthen telecom security, reduce compliance burdens, enable sustainable industry growth, and reinforce PM @narendramodi ji’s vision of ‘Make in India, Make for the World,’” he said. The key reforms include the extension of the Pro Tem Security Certification Scheme for original equipment manufacturers (OEMs) for two years and reduced fees for Telecom Security Testing Laboratories (TSTLs), the minister added. Scindia said the reforms align with the DSS principle of “Design in India, Solve in India, Scale for the World.” Add Zee News as a Preferred Source “These measures deliver a crucial boost to ease of doing business for telecom equipment manufacturers, with a 90 percent reduction in compliance burden for women-led and MSME testing laboratories, while other testing labs will benefit from a 50 percent reduction. Central and state government testing agencies, Indian Institutes of Technology (IITs), and other government institutions have been granted a complete waiver of testing fees,” the minister said. Highlighting the impact of the policy, Scindia said it empowers manufacturers and accelerates innovation. “By simplifying security verification while maintaining robust safeguards, the policy empowers manufacturers, accelerates innovation, and expands broadband penetration nationwide,” he said. “These reforms also enable the development of swadeshi telecom security testing infrastructure and reinforce Bharat as a trusted telecom manufacturing and testing hub. Together, these transformative steps advance our shared vision of Atmanirbhar Bharat with security, scale, and speed,” he added in his post.
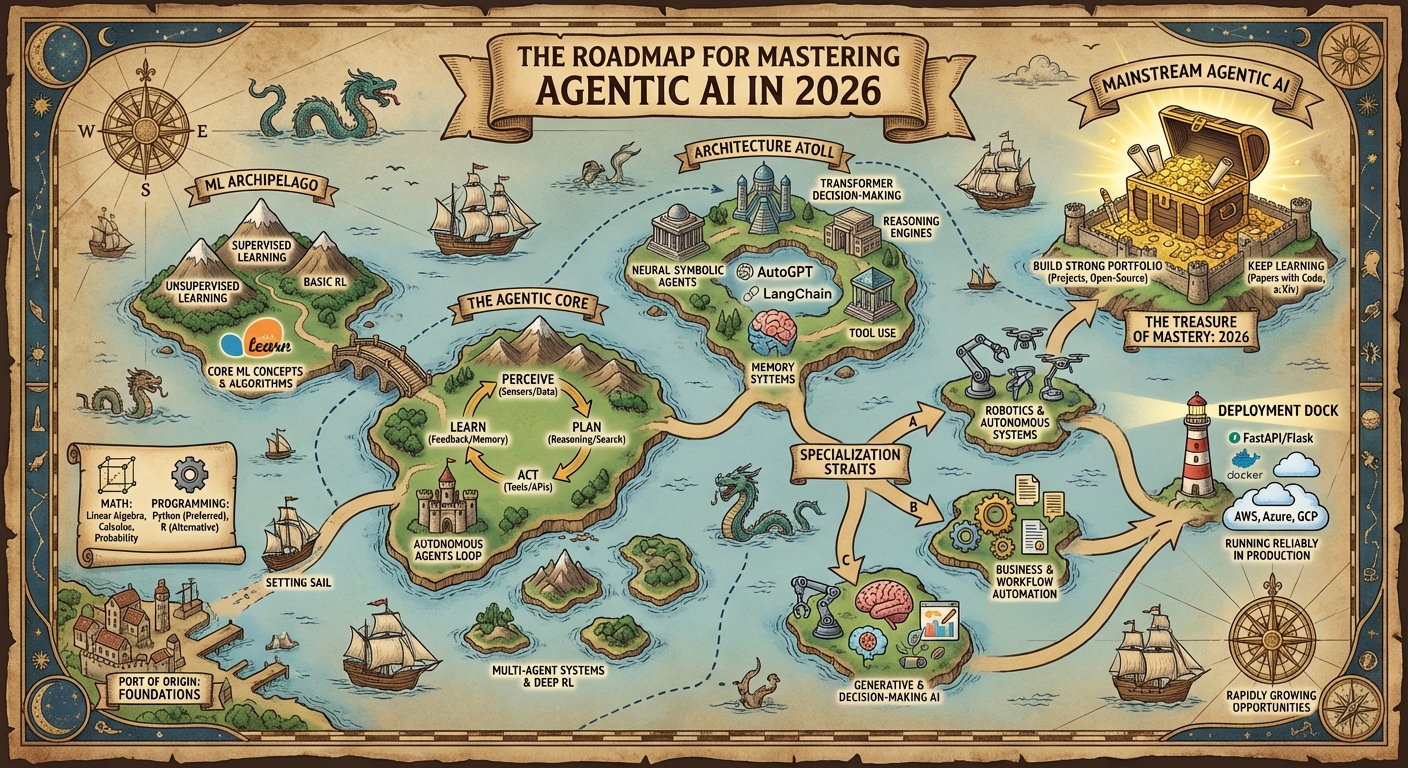
The Roadmap for Mastering Agentic AI in 2026
In this article, you will learn a clear, practical roadmap for mastering agentic AI: what it is, why it matters, and exactly how to build, deploy, and showcase real systems in 2026. Topics we will cover include: Core foundations in mathematics, programming, and machine learning. Concepts and architectures behind autonomous, tool-using AI agents. Deployment, specialization paths, and portfolio strategy. Let’s get right to it. The Roadmap for Mastering Agentic AI in 2026Image by Editor Introduction Agentic AI is changing how we interact with machines. Unlike traditional AI, which only reacts to commands, agentic AI can plan, act, and make decisions on its own to achieve complex goals. You see it in self-driving robots, digital assistants, and AI agents that handle business workflows or research tasks. This type of AI boosts productivity. The global AI market is growing fast, and agentic AI is expected to become mainstream by 2026. This guide gives a clear, step-by-step roadmap to master agentic AI in 2026. What Is Agentic AI? Agentic AI refers to systems that can take initiative and act independently to achieve objectives while learning from their environment. They don’t just follow instructions; rather, they plan, reason, and adapt to new situations. For example, in finance, they can adjust investments automatically, or in research, they can explore and suggest experiments independently. Step-By-Step Roadmap To Master Agentic AI In 2026 Step 1: Pre-Requisites First, you need to learn core concepts in mathematics and programming before moving on to machine learning. Learn Mathematics Build a solid understanding of the following topics:Linear Algebra: Learn vectors, matrices, matrix operations, eigenvalues, and singular value decomposition. You can learn from these YouTube courses: Calculus: Learn derivatives, gradients, and optimization techniques. You can learn from these YouTube courses: Probability and statistics: Focus on key concepts like Bayes’ theorem, probability distributions, and hypothesis testing. Helpful resources include: You can also refer to this textbook to learn the basics of mathematics needed for machine learning: TEXTBOOK: Mathematics for Machine Learning Learn Programming Now, learn the basics of programming in either one of the following languages: Python (Recommended)Python is the most popular programming language for machine learning. These resources can help you learn Python: After clearing the basics of programming, focus on libraries like Pandas, Matplotlib, and NumPy, which are used for data manipulation and visualization. Some resources that you might want to check out are: R (Alternative)R is useful for statistical modeling and data science. Learn R basics here: Step 2: Understand Key Concepts of Machine Learning At this step, you already have enough knowledge of mathematics and programming; now you can start learning the basics of machine learning. For that purpose, you should know there are three kinds of machine learning: Supervised learning: A type of machine learning that involves using labeled datasets to train algorithms with the aim of identifying patterns and making decisions. Important algorithms to learn: Linear regression, logistic regression, support vector machines (SVM), k-nearest neighbors (k-NN), and decision trees. Unsupervised learning: A type of machine learning where the model is trained on unlabeled data to find patterns, groupings, or structures without predefined outputs. Important algorithms to learn: Principal component analysis (PCA), k-means clustering, hierarchical clustering, and DBSCAN. Reinforcement learning: A category of machine learning in which an agent learns to make decisions by interacting with an environment and receiving rewards or penalties. You can skip diving deeper into it at this stage. The best course I have found to learn the basics of machine learning is:Machine Learning Specialization by Andrew Ng | Coursera It is a paid course that you can buy in case you need a certification, but you can also find the videos on YouTube:Machine Learning by Professor Andrew Ng Some other resources you can consult are: Try to practice and implement the scikit-learn library of Python. Follow this YouTube playlist for smooth learning. Step 3: Understand Autonomous Agents At the heart of agentic AI are autonomous agents that can: Perceive: Interpret input from the environment. Plan: Generate strategies to achieve goals. Act: Execute actions and interact with the world. Learn: Improve decisions based on feedback. You need to focus on topics such as multi-agent systems, goal-oriented planning & search algorithms (A*, D* Lite), hierarchical reinforcement learning, planning, and simulation environments (OpenAI Gym, Unity ML-Agents). The best resources I found to learn about autonomous agents are: Step 4: Deep Dive Into Agentic AI Architectures You need to learn to build agentic systems using simple, modern tools. You can start with neural-symbolic agents, which mix the learning ability of neural networks with basic logical reasoning. Then you can explore transformer-based decision-making, where large language models help with planning and problem-solving. Along the way, you should also understand the reasoning engine for decision-making; memory systems for handling immediate context, long-term knowledge, and experience-based learning; and the tool interface and goal management systems to connect agents to external APIs, manage tasks, and track progress. After that, try tools like AutoGPT, LangChain, and reinforcement learning with human feedback (RLHF) to create agents that can follow instructions and complete tasks on their own. The resources I found helpful are: Step 5: Choose a Specialization Agentic AI spans multiple domains. You have to pick one to focus on: Robotics & Autonomous Systems: You can dive into robot navigation, path planning, and manipulation using tools like ROS, Gazebo, and PyBullet. A few good resources to consult are: AI Agents for Business & Workflow Automation: You can work on intelligent assistants that handle research, reporting, customer queries, or marketing tasks. These agents connect different tools, automate repetitive work, and help teams make faster, smarter decisions using frameworks like LangChain and GPT APIs. Generative & Decision-Making AI: You can explore large language models that perform reasoning, planning, and multi-step problem-solving on their own. This specialization involves using transformers, RLHF, and agent frameworks to build systems that can think through tasks and generate reliable outputs. Some free resources you can consult are: Another resource that you can consult is: Multi Agent System in Artificial

Instagram Hit By Brief Outage; Several Users Report Login And App Issues On Meta-Owned Platform, Netizens React | Technology News
Instagram Outage: Instagram users faced an unexpected disruption early Sunday as the Meta-owned platform suffered a brief outage, mainly affecting users in the United States. According to outage-tracking website Downdetector, complaints peaked around 4:10 a.m. EST, when more than 180 users reported problems accessing the popular photo and video-sharing app. Several users said they were unable to log in or load content during the outage. Frustrated users took to other social media platforms to share screenshots of the issue, which showed a blank screen with a circular refresh icon and no clear error message. Instagram Outage: Downdetector Data Add Zee News as a Preferred Source Downdetector data showed that 45 per cent of affected users reported app-related issues, while 41 per cent faced login problems. Another 14 per cent said their feed or timeline was not loading properly. The outage appeared to have a limited impact in India. According to Downdetector, only about 10 users in the country reported issues accessing Instagram, suggesting the problem was largely confined to certain regions. Meta Official Statement Awaited Meta has not issued any official statement explaining the reason behind the outage or how long the disruption lasted. As Instagram went down, social media platforms were quickly flooded with user reactions. One user asked, “Is Insta down?” while another joked, “Jimin really got that Insta baddie aesthetic down.” Netizens Reaction #instagramdown is this happening to anyone else ?? pic.twitter.com/nUZ8fjP9EV (@xoxolillyy_) December 28, 2025 Ilhan Omar’s daughter posted on Instagram, wishing death to the “colonial empire from LA to Rafah.” She’s just saying what Ilhan’s too scared to admit: they hate the United States and want to burn it down—and they’re not even hiding it anymore. pic.twitter.com/RmfpgpH6SZ — Eyal Yakoby (@EYakoby) December 27, 2025 Instagram down? Unable to upload, keeps getting stuck and repeating the cycle.. worse when you’ve got deadlines ffs pic.twitter.com/6zGY0PJvr9 — J.E. (@JackEmson99) December 24, 2025 Yes. It has happened again. Instagram is down. And now everyone is on twitter. #instagramdown pic.twitter.com/n7lM4SI6Xv — Amit. (@iiamitverma) February 26, 2025 This is not the first time a Meta-owned platform has faced technical issues. Earlier this year, WhatsApp experienced multiple outages that affected users worldwide, including in India. In one such incident in September, thousands of users were unable to send messages or upload status updates, leading to widespread complaints across social media. (With IANS Inputs)

