

Lava Agni 4 India Launch: Lava is set to launch its newest member in the company’s top-of-the-line Agni series in the Indian market. The Lava Agni 4 will be making its debut on November 20 as the successor to the Lava Agni 3 5G. The upcoming smartphone is confirmed to come with a metal frame and a pill-shaped camera module with a dual camera setup. Meanwhile, Lava Mobiles shared a teaser of the upcoming Lava Agni 4 in a post on X (formerly Twitter). There appears to be a dual-LED flash above the camera sensors and “AGNI” branding in between them. The smartphone is also spotted on the IECEE certification website bearing the model number LBP1071A. What if your phone understood your ideas at the speed of thought? Introducing VAYU AI: Create, erase, refine in seconds. What’s the first idea you’d bring to life? Launching on 20.11.25 #Agni4 #VayuAI #ComingSoon #LavaMobiles pic.twitter.com/eaH2GB5U7Z — Lava Mobiles (@LavaMobile) November 16, 2025 Add Zee News as a Preferred Source Lava Agni 4 Specifications (Expected) The Lava Agni 4 is expected to feature a 6.78 inch Full HD Plus display with a smooth 120Hz refresh rate. It will likely run on the MediaTek Dimensity 8350 chipset, also used in phones such as the OnePlus Nord CE 5 and Infinix GT 30 Pro, paired with fast UFS 4.0 storage. The device is teased to include a dual rear camera setup with two 50 megapixel sensors and may pack a large battery of more than 7000mAh. It is confirmed to offer dual speakers and a flat display design. The phone is also expected to deliver a clean, bloatware free, near stock Android experience similar to previous Lava models. (Also Read: Vivo X300, Vivo X300 Pro Official India Launch Date Confirmed; Check Expected Display, Camera, Battery, And Other Features) Lava Agni 4 Price (Expected) The Agni 3 launched at a starting price of Rs 20,999, which indicates that the Agni 4 could arrive under Rs 25,000. With its expected specifications and price bracket, the Agni 4 is likely to compete with phones such as the OnePlus Nord CE 5, Infinix GT 30, and Poco X7.

OnePlus 15R Likely To Launch In India; Could Debut With 7,800mAh Battery; Check Expected Display, Camera, Colour Options, Processor, Price And Other Features | Technology News
OnePlus 15R India Launch: After the OnePlus 15 Launched In India, the Chinese smartphone-maker quietly confirmed that the OnePlus 15R is coming soon to global markets, including India. Meanwhile, the early reports suggest that the device may arrive as a rebranded version of the OnePlus Ace 6, which recently made its debut in China in October. If you’re wondering what OnePlus has in store next, the upcoming OnePlus 15R is already creating buzz. The smartphone is likely to come in three colour options which includes the Flash White, Competitive Black and Quicksilver to make the cut. Here’s a quick look at all the key details, expected features, and early leaks surrounding the device. OnePlus 15R Specifications (Expected) Add Zee News as a Preferred Source If the OnePlus 15R mirrors the OnePlus Ace 6 specs, the smartphone is expected to feature a large 6.83-inch flat AMOLED display with a 1.5K resolution, a smooth 165Hz refresh rate, and an impressive 5,000-nit peak brightness. The device may powered by a Snapdragon 8 Elite chipset, paired with up to 16GB LPDDR5X RAM and up to 512GB UFS 4.1 storage. For photography, the phone may offer a 50MP OIS-enabled main camera, an 8MP ultra-wide lens, and a 16MP front camera. The phone is likely to run ColorOS 16 based on Android 16. It is packed by a massive 7,800mAh battery with 120W SuperVOOC fast charging. It is also said to come with IP66/68/69/69K dust and water protection. (Also Read: Lava Agni 4 India Launch Date Officially Confirmed: Check Expected Display, Battery, Camera, Price, and Other Features) OnePlus 15R Price (Expected) If the OnePlus 15R follows the pricing of the OnePlus Ace 6 in China, it may adopt a similar structure. The Ace 6 starts at CNY 2599 (approximately Rs 32,300) for the 12GB 256GB variant. The other configurations, 16GB 256GB, 12GB 512GB, and 16GB 512GB, are priced at CNY 2899 (about Rs 36,000), CNY 3099 (Rs 38,800), and CNY 3399 (about 42,200 rupees) respectively.

7 Prompt Engineering Tricks to Mitigate Hallucinations in LLMs
7 Prompt Engineering Tricks to Mitigate Hallucinations in LLMs Introduction Large language models (LLMs) exhibit outstanding abilities to reason over, summarize, and creatively generate text. Still, they remain susceptible to the common problem of hallucinations, which consists of generating confident-looking but false, unverifiable, or sometimes even nonsensical information. LLMs generate text based on intricate statistical and probabilistic patterns rather than relying primarily on verifying grounded truths. In some critical fields, this issue can cause major negative impacts. Robust prompt engineering, which involves the craftsmanship of elaborating well-structured prompts with instructions, constraints, and context, can be an effective strategy to mitigate hallucinations. The seven techniques listed in this article, with examples of prompt templates, illustrate how both standalone LLMs and retrieval augmented generation (RAG) systems can improve their performance and become more robust against hallucinations by simply implementing them in your user queries. 1. Encourage Abstention and “I Don’t Know” Responses LLMs typically focus on providing answers that sound confident even when they are uncertain — check this article to comprehend in detail how LLMs generate text — generating sometimes fabricated facts as a result. Explicitly allowing abstention can guide the LLM toward mitigating a sense of false confidence. Let’s look at an example prompt to do this: “You are a fact-checking assistant. If you are not confident in an answer, respond: ‘I don’t have enough information to answer that.’ If confident, give your answer with a short justification.” The above prompt would be followed by an actual question or fact check. A sample expected response would be: “I don’t have enough information to answer that.” or “Based on the available evidence, the answer is … (reasoning).” This is a good first line of defense, but nothing is stopping an LLM from disregarding those directions with some regularity. Let’s see what else we can do. 2. Structured, Chain-of-Thought Reasoning Asking a language model to apply step-by-step reasoning incentivizes inner consistency and mitigates logic gaps that could sometimes cause model hallucinations. The Chain-of-Thought Reasoning (CoT) strategy basically consists of emulating an algorithm — like list of steps or stages that the model should sequentially tackle to address the overall task at hand. Once more, the example template below is assumed to be accompanied by a problem-specific prompt of your own. “Please think through this problem step by step:1) What information is given?2) What assumptions are needed?3) What conclusion follows logically?” A sample expected response: “1) Known facts: A, B. 2) Assumptions: C. 3) Therefore, conclusion: D.” 3. Grounding with “According To” This prompt engineering trick is conceived to link the answer sought to named sources. The effect is to discourage invention-based hallucinations and stimulate fact-based reasoning. This strategy can be naturally combined with number 1 discussed earlier. “According to the World Health Organization (WHO) report from 2023, explain the main drivers of antimicrobial resistance. If the report doesn’t provide enough detail, say ‘I don’t know.’” A sample expected response: “According to the WHO (2023), the main drivers include overuse of antibiotics, poor sanitation, and unregulated drug sales. Further details are unavailable.” 4. RAG with Explicit Instruction and Context RAG grants the model access to a knowledge base or document base containing verified or current text data. Even so, the risk of hallucinations persists in RAG systems unless a well-crafted prompt instructs the system to exclusively rely on retrieved text. *[Assume two retrieved documents: X and Y]*“Using only the information in X and Y, summarize the main causes of deforestation in the Amazon basin and related infrastructure projects. If the documents don’t cover a point, say ‘insufficient data.’” A sample expected response: “According to Doc X and Doc Y, key causes include agricultural expansion and illegal logging. For infrastructure projects, insufficient data.” 5. Output Constraints and Limiting Scope Tightly controlling the format of generated outputs and their length contributes to reducing hallucinations in the form of speculative or tangential statements, like unsupported claims for causes, over-elaborated chains of reasoning, or made-up statistics, thereby preventing results that may drift away from source materials. Constraining the “degrees of freedom” over the answer space increases the odds of returning verifiable information rather than filling the gaps “no matter what.” “In no more than 100 words, summarize the role of mitochondria in human cells. If unsure, respond ‘I don’t know.’” A sample expected response: “Mitochondria generate ATP via oxidative phosphorylation, regulate calcium levels, and influence apoptosis. I lack sufficient data on additional roles.” 6. RAG-based Correction Loops: Chain-of-Verification This approach consists of combining retrieval with self-checking, enabling the model’s ability to question and double-check its own claims against external sources of evidence, primarily in RAG systems. It mainly targets hallucinations due to “over-confidence,” trying to mitigate them. “Step 1: Generate an initial answer to the question: ‘When did the Berlin Wall fall?’Step 2: Retrieve and read relevant passages from a trusted historical database.Step 3: Compare the retrieved evidence to your answer.Step 4: If discrepancies exist, correct the answer and cite the retrieved source.” A sample expected response: “Initial answer: 1989.Retrieved evidence: Historical archives confirm the Berlin Wall opened on 9 November 1989.Final verified answer: The Berlin Wall fell on 9 November 1989 when East Berlin opened border crossings.” 7. Domain-Specific Prompts, Disclaimers, and Safety Guardrails In high-stakes application domains like medicine, it is essential to specify constrained domain boundaries and require citations to sources, to reduce the risk of speculative claims that could in practice lead to negative consequences. Here is an example of doing so: “You are a certified medical information assistant. Using peer-reviewed studies or official guidelines published before 2024, explain the first-line treatment for moderate persistent asthma in adults. If you cannot cite such a guideline, respond: ‘I cannot provide a recommendation; consult a medical professional.’” A sample expected response: “According to the Global Initiative for Asthma (GINA) 2023 guideline, first-line therapy for moderate persistent asthma is a low-dose inhaled corticosteroid with a long-acting β₂-agonist such as budesonide/formoterol. For patient-specific adjustments, consult a clinician.” Wrapping Up Below is a summary the 7 strategies
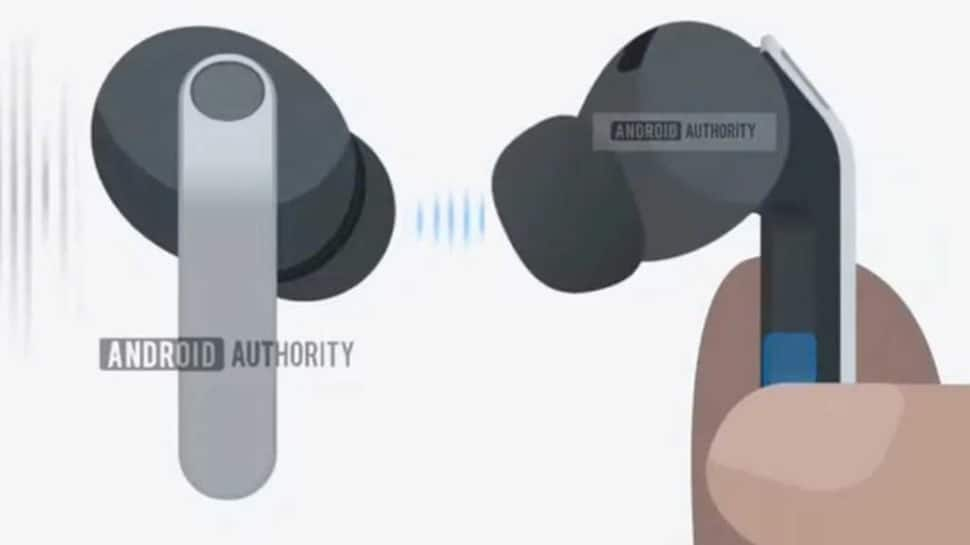
Samsung Galaxy Buds 4 Pro Design Leaked – Check Advanced Features And Upgrades | Technology News
Samsung’s next-generation Galaxy Buds 4 Pro have appeared online through newly leaked One UI 8.5 animations, giving the first detailed look at the upcoming earbuds. The leak has revealed major design upgrades, improved controls, and several new features. The earbuds are expected to launch alongside the Galaxy S26 series in early 2026, published by ‘Android Authority.’ Refined Design The leaked animations show that Samsung is keeping the stem-style design for the Galaxy Buds 4 Pro but refining it significantly. Instead of the sharp, triangular stem used in the Buds 3 Pro, the Buds 4 Pro appears to feature a flatter and cleaner-looking stem. Add Zee News as a Preferred Source Notably, the light bar on the stem, which was a signature design element of the Buds 3 Pro, seems to have been removed. However, the pinch controls are expected to remain. The in-ear tips also appear to be redesigned, likely offering a better fit and improved comfort for users. New Charging Case Layout Samsung seems to be introducing changes to the charging case as well. The Galaxy Buds 4 Pro are shown lying flat inside the case, rather than being placed vertically like previous models. This gives the charging case a more spacious and streamlined interior layout. Reports show that this new design language may also extend to the standard Galaxy Buds 4, though Samsung has not yet confirmed this. According to the leak, the Galaxy Buds 4 and Buds 4 Pro are identified internally by the codenames “Handel” and “Bach,” respectively. (Also Read: OnePlus 15R Likely To Launch In India; Could Debut With 7,800mAh Battery; Check Expected Display, Camera, Colour Options, Processor, Price And Other Features) Head Gestures: A New Hands-Free Control Feature According to ‘Android Authority,’ one of the biggest additions coming to the Galaxy Buds 4 Pro appears to be a new control system called Head Gestures. The feature was spotted in One UI 8.5 code strings and is designed to let users control their device by simply moving their head. With Head Gestures, users can nod or shake their head to respond to calls and notifications. The gestures can also be used to silence alerts, dismiss alarms, and answer yes-or-no questions. Additional Features Besides the design and control upgrades, leaked animations also point to several extra features expected for the Galaxy Buds 4 Pro. These include: 360-degree recording Adaptive Noise Control Find Your Phone support Easy pairing for both phones and tablets While Samsung has not officially confirmed any details about the Galaxy Buds 4 Pro, the leaks show that the company is preparing an advanced upgrade over the Buds 3 Pro. The Galaxy Buds 4 Pro is expected to be unveiled alongside the Galaxy S26 series in early 2026.

10 Python One-Liners for Calculating Model Feature Importance
10 Python One-Liners for Calculating Model Feature ImportanceImage by Editor Understanding machine learning models is a vital aspect of building trustworthy AI systems. The understandability of such models rests on two basic properties: explainability and interpretability. The former refers to how well we can describe a model’s “innards” (i.e. how it operates and looks internally), while the latter concerns how easily humans can understand the captured relationships between input features and predicted outputs. As we can see, the difference between them is subtle, but there is a powerful bridge connecting both: feature importance. This article unveils 10 simple but effective Python one-liners to calculate model feature importance from different perspectives — helping you understand not only how your machine learning model behaves, but also why it made the prediction(s) it did. 1. Built-in Feature Importance in Decision Tree-based Models Tree-based models like random forests and XGBoost ensembles allow you to easily obtain a list of feature-importance weights using an attribute like: importances = model.feature_importances_ importances = model.feature_importances_ Note that model should contain a trained model a priori. The result is an array containing the importance of features, but if you want a more self-explanatory version, this code enhances the previous one-liner by incorporating the feature names for a dataset like iris, all in one line. print(“Feature importances:”, list(zip(iris.feature_names, model.feature_importances_))) print(“Feature importances:”, list(zip(iris.feature_names, model.feature_importances_))) 2. Coefficients in Linear Models Simpler linear models like linear regression and logistic regression also expose feature weights via learned coefficients. This is a way to obtain the first of them directly and neatly (remove the positional index to obtain all weights): importances = abs(model.coef_[0]) importances = abs(model.coef_[0]) 3. Sorting Features by Importance Similar to the enhanced version of number 1 above, this useful one-liner can be used to rank features by their importance values in descending order: an excellent glimpse of which features are the strongest or most influential contributors to model predictions. sorted_features = sorted(zip(features, importances), key=lambda x: x[1], reverse=True) sorted_features = sorted(zip(features, importances), key=lambda x: x[1], reverse=True) 4. Model-Agnostic Permutation Importance Permutation importance is an additional approach to measure a feature’s importance — namely, by shuffling its values and analyzing how a metric used to measure the model’s performance (e.g. accuracy or error) decreases. Accordingly, this model-agnostic one-liner from scikit-learn is used to measure performance drops as a result of randomly shuffling a feature’s values. from sklearn.inspection import permutation_importance result = permutation_importance(model, X, y).importances_mean from sklearn.inspection import permutation_importance result = permutation_importance(model, X, y).importances_mean 5. Mean Loss of Accuracy in Cross-Validation Permutations This is an efficient one-liner to test permutations in the context of cross-validation processes — analyzing how shuffling each feature impacts model performance across K folds. import numpy as np from sklearn.model_selection import cross_val_score importances = [(cross_val_score(model, X.assign(**{f: np.random.permutation(X[f])}), y).mean()) for f in X.columns] import numpy as np from sklearn.model_selection import cross_val_score importances = [(cross_val_score(model, X.assign(**{f: np.random.permutation(X[f])}), y).mean()) for f in X.columns] 6. Permutation Importance Visualizations with Eli5 Eli5 — an abbreviated form of “Explain like I’m 5 (years old)” — is, in the context of Python machine learning, a library for crystal-clear explainability. It provides a mildly visually interactive HTML view of feature importances, making it particularly handy for notebooks and suitable for trained linear or tree models alike. import eli5 eli5.show_weights(model, feature_names=features) import eli5 eli5.show_weights(model, feature_names=features) 7. Global SHAP Feature Importance SHAP is a popular and powerful library to get deeper into explaining model feature importance. It can be used to calculate mean absolute SHAP values (feature-importance indicators in SHAP) for each feature — all under a model-agnostic, theoretically grounded measurement approach. import numpy as np import shap shap_values = shap.TreeExplainer(model).shap_values(X) importances = np.abs(shap_values).mean(0) import numpy as np import shap shap_values = shap.TreeExplainer(model).shap_values(X) importances = np.abs(shap_values).mean(0) 8. Summary Plot of SHAP Values Unlike global SHAP feature importances, the summary plot provides not only the global importance of features in a model, but also their directions, visually helping understand how feature values push predictions upward or downward. shap.summary_plot(shap_values, X) shap.summary_plot(shap_values, X) Let’s look at a visual example of result obtained: 9. Single-Prediction Explanations with SHAP One particularly attractive aspect of SHAP is that it helps explain not only the overall model behavior and feature importances, but also how features specifically influence a single prediction. In other words, we can reveal or decompose an individual prediction, explaining how and why the model yielded that specific output. shap.force_plot(shap.TreeExplainer(model).expected_value, shap_values[0], X.iloc[0]) shap.force_plot(shap.TreeExplainer(model).expected_value, shap_values[0], X.iloc[0]) 10. Model-Agnostic Feature Importance with LIME LIME is an alternative library to SHAP that generates local surrogate explanations. Rather than using one or the other, these two libraries complement each other well, helping better approximate feature importance around individual predictions. This example does so for a previously trained logistic regression model. from lime.lime_tabular import LimeTabularExplainer exp = LimeTabularExplainer(X.values, feature_names=features).explain_instance(X.iloc[0], model.predict_proba) from lime.lime_tabular import LimeTabularExplainer exp = LimeTabularExplainer(X.values, feature_names=features).explain_instance(X.iloc[0], model.predict_proba) Wrapping Up This article unveiled 10 effective Python one-liners to help better understand, explain, and interpret machine learning models with a focus on feature importance. Comprehending how your model works from the inside is no longer a mysterious black box with the aid of these tools.

Oppo Find X9, Oppo Find X9 Pro Price Leaked In India Ahead Of November 18 Launch; Check Display, Battery, Camera, Processor And Other Features | Technology News
Oppo Find X9 Series India Launch: Oppo is set to launch the Oppo Find X9 series in India on Tuesday, November 18, 2025. The series includes the Oppo Find X9 and Oppo Find X9 Pro smartphones. The Oppo Find X9 lineup will debut with the world’s first 200MP Hasselblad telephoto camera and the powerful LUMO Image Engine. The Oppo Find X9 is expected to be offered in Space Black and Titanium Grey shades, while the Find X9 Pro will be available in Silk White and Titanium Charcoal colourways. Notably, the OPPO Find X9 series is already launched in India. Vivo has stepped things up by rolling out OriginOS 6 globally and gradually phasing out Funtouch OS. Oppo Find X9 Specifications (Expected) Add Zee News as a Preferred Source The upcoming OPPO Find X9 Pro is expected to deliver powerful performance with the MediaTek Dimensity 9500 processor, paired with up to 16GB of RAM and fast UFS 4.1 storage. It is tipped to feature a 6.78-inch AMOLED display with a smooth 120Hz refresh rate. On the camera front, the device is anticipated to shine with a Hasselblad-tuned triple camera system, likely including a 50MP Sony LYT-828 main sensor, a 50MP ultrawide lens with the Samsung JN5 sensor, and a 200MP Samsung HP5 periscope telephoto camera. The phone may also offer top-tier durability with IP66, IP68, and IP69 ratings for dust and water resistance. To round things off, the Find X9 Pro is expected to pack a massive 7025mAh battery, making it a well-rounded flagship built for performance, photography, and endurance. Oppo Find X9 Pro Specifications (Expected) The OPPO Find X9 Pro is rumoured to arrive with a stunning 6.78-inch AMOLED display offering a crisp 1272 × 2772 pixel resolution and a smooth 120Hz refresh rate. The device is powered by the MediaTek Dimensity 9500 chipset, promising top-tier flagship performance. The phone is also said to come with strong durability, featuring IP66, IP68, and IP69 ratings for dust and water resistance. On the Photography front, the smartphone comes with a triple rear camera setup consisting of 50MP + 50MP + 200MP sensors. The Oppo Find X9 Pro is expected to house a massive 7050mAh battery, ensuring long-lasting usage for heavy-duty tasks, gaming, and multimedia. OPPO Find X9 Series Price In India (Leaked) Tipster Paras Guglani revealed the expected India pricing for the Oppo Find X9 series through a post on X (formerly Twitter). The OPPO Find X9 series is expected to launch with competitive pricing across its variants. The standard OPPO Find X9 may start at Rs 74,999 for the 12GB RAM + 256GB storage model, while the higher-end 16GB RAM + 512GB storage variant is likely to be priced around Rs 84,999. Meanwhile, the flagship OPPO Find X9 Pro is expected to come in a single 16GB RAM + 512GB storage configuration, carrying a premium price tag of Rs 99,999. (Also Read: OnePlus 15R Likely To Launch In India; Could Debut With 7,800mAh Battery; Check Expected Display, Camera, Colour Options, Processor, Price And Other Features) Special Hasselblad Kit Pricing (Expected) OPPO is also introducing a dedicated Hasselblad Teleconverter Kit for the Find X9 series, priced at Rs 29,999. When paired with the standard Find X9, the total cost comes to approximately Rs 1,04,998. For those opting for the top-end Find X9 Pro along with the kit, the combined price rises to around Rs 1,29,998.

How to Diagnose Why Your Language Model Fails
In this article, you will learn a clear, practical framework to diagnose why a language model underperforms and how to validate likely causes quickly. Topics we will cover include: Five common failure modes and what they look like Concrete diagnostics you can run immediately Pragmatic mitigation tips for each failure Let’s not waste any more time. How to Diagnose Why Your Language Model FailsImage by Editor Introduction Language models, as incredibly useful as they are, are not perfect, and they may fail or exhibit undesired performance due to a variety of factors, such as data quality, tokenization constraints, or difficulties in correctly interpreting user prompts. This article adopts a diagnostic standpoint and explores a 5-point framework for understanding why a language model — be it a large, general-purpose large language model (LLM), or a small, domain-specific one — might fail to perform well. Diagnostic Points for a Language Model In the following sections, we will uncover common reasons for failure in language models, briefly describing each one and providing practical tips for diagnosis and how to overcome them. 1. Poor Quality or Insufficient Training Data Just like other machine learning models such as classifiers and regressors, a language model’s performance greatly depends on the amount and quality of the data used to train it, with one not-so-subtle nuance: language models are trained on very large datasets or text corpora, often spanning from many thousands to millions or billions of documents. When the language model generates outputs that are incoherent, factually incorrect, or nonsensical (hallucinations) even for simple prompts, chances are the quality or amount of training data used is not sufficient. Specific causes could include a training corpus that is too small, outdated, or full of noisy, biased, or irrelevant text. In smaller language models, the consequences of this data-related issue also include missing domain vocabulary in generated answers. To diagnose data issues, inspect a sufficiently representative portion of the training data if possible, analyzing properties such as relevance, coverage, and topic balance. Running targeted prompts about known facts and using rare terms to identify knowledge gaps is also an effective diagnostic strategy. Finally, keep a trusted reference dataset handy to compare generated outputs with information contained there. When the language model generates outputs that are incoherent, factually incorrect, or nonsensical (hallucinations) even for simple prompts, chances are the quality or amount of training data used is not sufficient. 2. Tokenization or Vocabulary Limitations Suppose that by analyzing the inner behavior of a freshly trained language model, it appears to struggle with certain words or symbols in the vocabulary, breaking them into tokens in an unexpected manner, or failing to properly represent them. This may stem from the tokenizer used in conjunction with the model, which does not align appropriately with the target domain, yielding far-from-ideal treatment of uncommon words, technical jargon, and so on. Diagnosing tokenization and vocabulary issues involves inspecting the tokenizer, namely by checking how it splits domain-specific terms. Utilizing metrics such as perplexity or log-likelihood on a held-out subset can quantify how well the model represents domain text, and testing edge cases — e.g., non-Latin scripts or words and symbols containing uncommon Unicode characters — helps pinpoint root causes related to token management. 3. Prompt Instability and Sensitivity A small change in the wording of a prompt, its punctuation, or the order of multiple nonsequential instructions can lead to significant changes in the quality, accuracy, or relevance of the generated output. That is prompt instability and sensitivity: the language model becomes overly sensitive to how the prompt is articulated, often because it has not been properly fine-tuned for effective, fine-grained instruction following, or because there are inconsistencies in the training data. The best way to diagnose prompt instability is experimentation: try a battery of paraphrased prompts whose overall meaning is equivalent, and compare how consistent the results are with each other. Likewise, try to identify patterns under which a prompt results in a stable versus an unstable response. 4. Context Windows and Memory Constraints When a language model fails to use context introduced in earlier interactions as part of a conversation with the user, or misses earlier context in a long document, it can start exhibiting undesired behavior patterns such as repeating itself or contradicting content it “said” before. The amount of context a language model can retain, or context window, is largely determined by memory limitations. Accordingly, context windows that are too short may truncate relevant information and drop earlier cues, whereas overly lengthy contexts can hinder tracking of long-range dependencies. Diagnosing issues related to context windows and memory limitations entails iteratively evaluating the language model with increasingly longer inputs, carefully measuring how much it can correctly recall from earlier parts. When available, attention visualizations are a powerful resource to check whether relevant tokens are attended across long ranges in the text. 5. Domain and Temporal Drifts Once deployed, a language model is still not exempt from providing wrong answers — for example, answers that are outdated, that miss recently coined terms or concepts, or that fail to reflect evolving domain knowledge. This means the training data might have become anchored in the past, still relying on a snapshot of the world that has already changed; consequently, changes in facts inevitably lead to knowledge degradation and performance degradation. This is analogous to data and concept drifts in other types of machine learning systems. To diagnose temporal or domain-related drifts, continuously compile benchmarks of new events, terms, articles, and other relevant materials in the target domain. Track the accuracy of responses using these new language items compared to responses related to stable or timeless knowledge, and see if there are significant differences. Additionally, schedule periodic performance-monitoring schemes based on “fresh queries.” Final Thoughts This article examined several common reasons why language models may fail to perform well, from data quality issues to poor management of context and drifts in production caused by changes in factual knowledge. Language models are inevitably complex; therefore, understanding possible reasons
WhatsApp New Update: Now You Can Talk To Friends Even If They Don’t Use the Instant Messaging Platform | Technology News
WhatsApp Cross-platform Chats Feature: WhatsApp, an instant messaging platform, is likely to launch a ‘third party chats’ feature which would allow users to send messages to their friends on different messaging platforms reportedly. The Meta-owned platform is planning to launch the much-anticipated feature in Europe and works for texts, photos, videos and documents. Even if your friend doesn’t use WhatsApp, you can still talk to them easily. WhatsApp will let you send and receive messages from other apps too. However, the feature was spotted by WABetaInfo in WhatsApp for Android beta version 2.25.33.8 and is reportedly an attempt to comply with the European Union’s Digital Markets Act (DMA). WhatsApp Cross-platform Chats Feature: What’s New Expected Add Zee News as a Preferred Source The cross-platform chats on WhatsApp will come with some limits. For now, you won’t get features like status updates, disappearing messages, or stickers. Also, someone you blocked on WhatsApp might still contact you through another app, so you may need to review your privacy settings. You can choose to keep messages from other apps in a separate section or mix them with your normal chats. You’ll also be able to decide if you want notifications from these apps. WhatsApp says chats will still be end-to-end encrypted, but messages from other apps may be less secure because they follow different data rules. If you’re not comfortable, you can simply turn off cross-platform messaging. (Also Read: Lava Agni 4 India Launch Date Officially Confirmed: Check Expected Display, Battery, Camera, Price, and Other Features) This feature is currently being tested with a small group of users in the EU, and a wider rollout is planned for next year. However, voice and video calls between different apps may not arrive until 2027. It is expected that WhatsApp could receive more integration requests in the future including from apps like ChatGPT reportedly. However, some key WhatsApp features such as status updates, stickers, and disappearing messages may not work with the new interoperability messaging feature.

Essential Chunking Techniques for Building Better LLM Applications
Essential Chunking Techniques for Building Better LLM ApplicationsImage by Author Introduction Every large language model (LLM) application that retrieves information faces a simple problem: how do you break down a 50-page document into pieces that a model can actually use? So when you’re building a retrieval-augmented generation (RAG) app, before your vector database retrieves anything and your LLM generates responses, your documents need to be split into chunks. The way you split documents into chunks determines what information your system can retrieve and how accurately it can answer queries. This preprocessing step, often treated as a minor implementation detail, actually determines whether your RAG system succeeds or fails. The reason is simple: retrieval operates at the chunk level, not the document level. Proper chunking improves retrieval accuracy, reduces hallucinations, and ensures the LLM receives focused, relevant context. Poor chunking cascades through your entire system, causing failures that retrieval mechanisms can’t fix. This article covers essential chunking strategies and explains when to use each method. Why Chunking Matters Embedding models and LLMs have finite context windows. Documents typically exceed these limits. Chunking solves this by breaking long documents into smaller segments, but introduces an important trade-off: chunks must be small enough for efficient retrieval while remaining large enough to preserve semantic coherence. Vector search operates on chunk-level embeddings. When chunks mix multiple topics, their embeddings represent an average of those concepts, making precise retrieval difficult. When chunks are too small, they lack sufficient context for the LLM to generate useful responses. The challenge is finding the middle ground where chunks are semantically focused yet contextually complete. Now let’s get to the actual chunking techniques you can experiment with. 1. Fixed-Size Chunking Fixed-size chunking splits text based on a predetermined number of tokens or characters. The implementation is straightforward: Select a chunk size (commonly 512 or 1024 tokens) Add overlap (typically 10–20%) Divide the document The method ignores document structure entirely. Text splits at arbitrary points regardless of semantic boundaries, often mid-sentence or mid-paragraph. Overlap helps preserve context at boundaries but doesn’t address the core issue of structure-blind splitting. Despite its limitations, fixed-size chunking provides a solid baseline. It’s fast, deterministic, and works adequately for documents without strong structural elements. When to use: Baseline implementations, simple documents, rapid prototyping. 2. Recursive Chunking Recursive chunking improves on fixed-size approaches by respecting natural text boundaries. It attempts to split at progressively finer separators — first at paragraph breaks, then sentences, then words — until chunks fit within the target size. Recursive ChunkingImage by Author The algorithm tries to keep semantically related content together. If splitting at paragraph boundaries produces chunks within the size limit, it stops there. If paragraphs are too large, it recursively applies sentence-level splitting to oversized chunks only. This maintains more of the document’s original structure than arbitrary character splitting. Chunks tend to align with natural thought boundaries, improving both retrieval relevance and generation quality. When to use: General-purpose applications, unstructured text like articles and reports. 3. Semantic Chunking Rather than relying on characters or structure, semantic chunking uses meaning to determine boundaries. The process embeds individual sentences, compares their semantic similarity, and identifies points where topic shifts occur. Semantic ChunkingImage by Author Implementation involves computing embeddings for each sentence, measuring distances between consecutive sentence embeddings, and splitting where distance exceeds a threshold. This creates chunks where content coheres around a single topic or concept. The computational cost is higher. But the result is semantically coherent chunks that often improve retrieval quality for complex documents. When to use: Dense academic papers, technical documentation where topics shift unpredictably. 4. Document-Based Chunking Documents with explicit structure — Markdown headers, HTML tags, code function definitions — contain natural splitting points. Document-based chunking leverages these structural elements. For Markdown, split on header levels. For HTML, split on semantic tags like <section> or <article>. For code, split on function or class boundaries. The resulting chunks align with the document’s logical organization, which typically correlates with semantic organization. Here’s an example of document-based chunking: Document-Based ChunkingImage by Author Libraries like LangChain and LlamaIndex provide specialized splitters for various formats, handling the parsing complexity while letting you focus on chunk size parameters. When to use: Structured documents with clear hierarchical elements. 5. Late Chunking Late chunking reverses the typical embedding-then-chunking sequence. First, embed the entire document using a long-context model. Then split the document and derive chunk embeddings by averaging the relevant token-level embeddings from the full document embedding. This preserves global context. Each chunk’s embedding reflects not just its own content but its relationship to the broader document. References to earlier concepts, shared terminology, and document-wide themes remain encoded in the embeddings. The approach requires long-context embedding models capable of processing entire documents, limiting its applicability to reasonably sized documents. When to use: Technical documents with significant cross-references, legal texts with internal dependencies. 6. Adaptive Chunking Adaptive chunking dynamically adjusts chunk parameters based on content characteristics. Dense, information-rich sections receive smaller chunks to maintain granularity. Sparse, contextual sections receive larger chunks to preserve coherence. Adaptive ChunkingImage by Author The implementation typically uses heuristics or lightweight models to assess content density and adjust chunk size accordingly. When to use: Documents with highly variable information density. 7. Hierarchical Chunking Hierarchical chunking creates multiple granularity levels. Large parent chunks capture broad themes, while smaller child chunks contain specific details. At query time, retrieve coarse chunks first, then drill into fine-grained chunks within relevant parents. This enables both high-level queries (“What does this document cover?”) and specific queries (“What’s the exact configuration syntax?”) using the same chunked corpus. Implementation requires maintaining relationships between chunk levels and traversing them during retrieval. When to use: Large technical manuals, textbooks, comprehensive documentation. 8. LLM-Based Chunking In LLM-based chunking, we use an LLM to determine chunk boundaries and push chunking into intelligent territory. Instead of rules or embeddings, the LLM analyzes the document and decides how to split it based on semantic understanding. LLM-Based ChunkingImage by Author Approaches include breaking text into atomic

BSNL Student Special Plan Launched In India With Unlimited Calling And 100GB Data; Check Price, Benefits, Validity And How To Activate | Technology News
BSNL Student Special Plan Price In India: BSNL, a state-owned telecom operator, has rolled out a mobile plan tailored specifically for students. This plan is available from 14 November to 13 December 2025. BSNL’s new plan enables students to access large data volumes and enjoy unlimited voice calls at a pocket-friendly cost, as the company expands its nationwide 4G rollout. BSNL Student Special Plan: Price, Validity BSNL has introduced a special Rs 251 mobile plan that delivers strong value for users looking for affordable connectivity. The plan is available from November 14 to December 13, 2025, and comes with a complete set of benefits valid for 28 days. Add Zee News as a Preferred Source BSNL Student Special Plan: Benefits Customers will receive unlimited voice calls for 28 days, 100 GB of high speed data, and 100 SMS per day, making it suitable for students, professionals, and regular data users. A key highlight of this offer is its wide eligibility. (Also Read: Lava Agni 4 India Launch Date Officially Confirmed: Check Expected Display, Battery, Camera, Price, and Other Features) Unlike many recent promotions that were limited to new customers, this plan appears to be open to all eligible users. As BSNL continues to expand its 4G services across the country, the Rs 251 plan stands out as a valuable option for those who want reliable calling and ample data at a reasonable cost. Study, Stream, Succeed with #BSNL ! Get BSNL’s Student Special Plan @ ₹251 with Unlimited Calls, 100GB Data & 100 SMS/Day. Offer valid till 14 Dec, 2025. #BSNLLearnersPlan #DigitalIndia #ConnectingBharat pic.twitter.com/GNb3PclKGu — BSNL India (@BSNLCorporate) November 15, 2025 BSNL Student Special Plan: How To Activate Customers can activate the Student Plan by visiting their nearest BSNL Customer Service Centre (CSC), calling 1800-180-1503, or accessing the official website at bsnl.co.in. Meanwhile, the Tata Consultancy Services (TCS) has completed the rollout of 1,00,000 4G sites for Bharat Sanchar Nigam Limited (BSNL) and the next phase of the 4G network saturation expansion activities. State-owned BSNL, earlier this week, issued a bid invitation to companies to further densify its 4G coverage, in addition to the deployment already underway by the TCS-led consortium.



