
WhatsApp New Features: WhatsApp has rolled out several new updates to make group chats more organised and expressive. Since many users depend on group chats for planning events, running communities, and staying in touch, the app has now refined how people communicate in shared conversations. The biggest update is the introduction of member tags. This feature lets users add custom labels to their names within a group. For example, someone can appear as “Anna’s Dad” in a school group, “Secretary” in a society group, or “Striker” in a football chat. These labels are visible only inside that group. Users can choose different tags for different groups. WhatsApp said the feature will be available gradually to users worldwide. WhatsApp is also adding new ways to express yourself. With text stickers, users can now turn any word or phrase into a sticker by typing it into the sticker search bar. These stickers can be saved directly to the sticker pack without sending them first. This makes it quicker to reuse favourite expressions without depending only on emojis or GIFs. Add Zee News as a Preferred Source Group planning is also getting simpler. WhatsApp now allows custom event reminders inside group chats. Users can set early alerts while creating events. This helps reduce missed calls, late arrivals, or forgotten plans. The reminders work for both physical meetups and online events. These updates add to WhatsApp’s existing group features. Users can already share files up to 2GB, send HD photos and videos, share screens during calls, and start voice chats without making a formal call. WhatsApp says these changes are part of its effort to improve the group chat experience across devices. As group conversations play a bigger role in daily life, the app is clearly aiming to make chats more organised, clearer, and more user-friendly.
The Machine Learning Engineer’s Checklist: Best Practices for Reliable Models
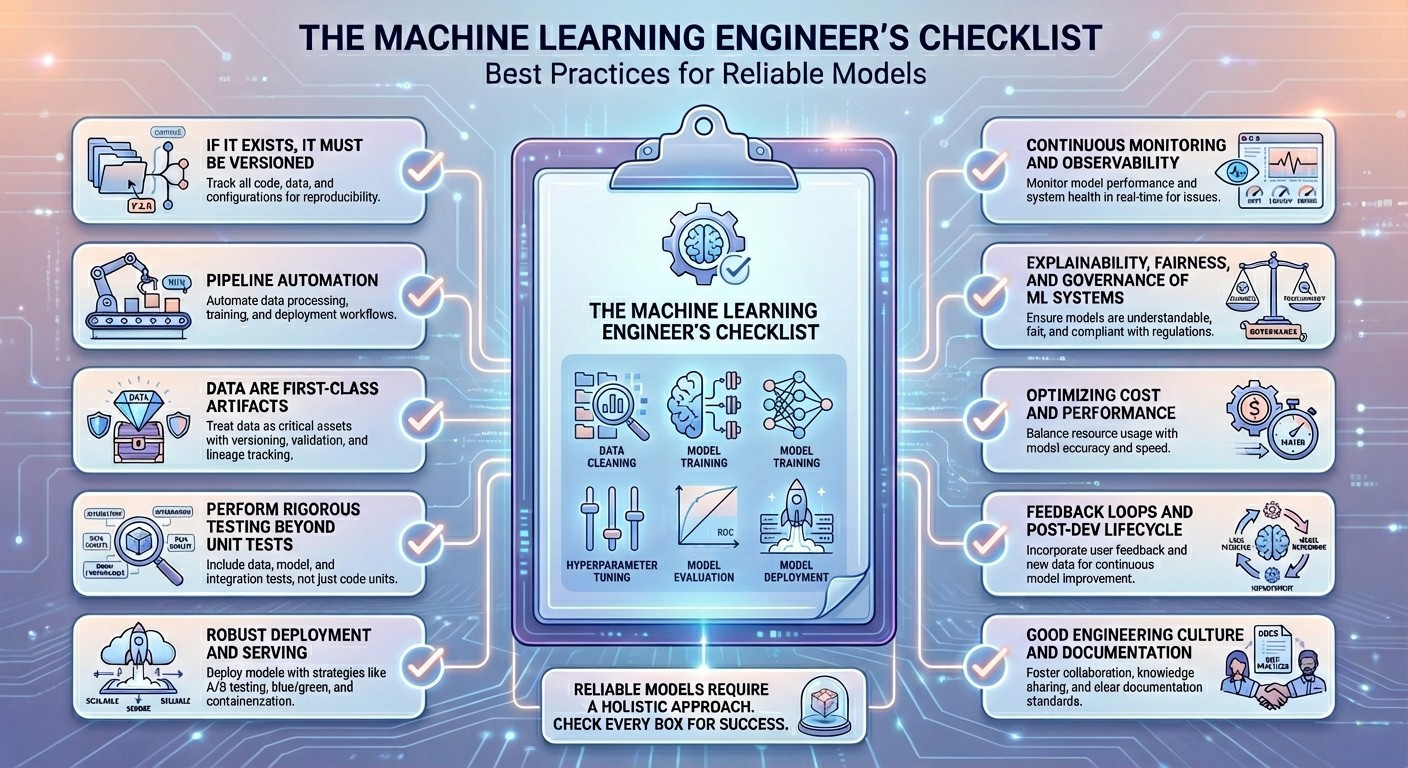
The Machine Learning Engineer’s Checklist: Best Practices for Reliable ModelsImage by Editor Introduction Building newly trained machine learning models that work is a relatively straightforward endeavor, thanks to mature frameworks and accessible computing power. However, the real challenge in the production lifecycle of a model begins after the first successful training run. Once deployed, a model operates in a dynamic, unpredictable environment where its performance can degrade rapidly, turning a successful proof-of-concept into a costly liability. Practitioners often encounter issues like data drift, where the characteristics of the production data change over time; concept drift, where the underlying relationship between input and output variables evolves; or subtle feedback loops that bias future training data. These pitfalls — which range from catastrophic model failures to slow, insidious performance decay — are often the result of lacking the right operational rigor and monitoring systems. Building reliable models that keep performing well in the long run is a different story, one that requires discipline, a robust MLOps pipeline, and, of course, skill. This article focuses on exactly that. By providing a systematic approach to tackle these challenges, this research-backed checklist outlines essential best practices, core skills, and sometimes not-to-miss tools that every machine learning engineer should be familiar with. By adopting the principles outlined in this guide, you will be equipped to transform your initial models into maintainable, high-quality production systems, ensuring they remain accurate, unbiased, and resilient to the inevitable shifts and challenges of the real world. Without further ado, here is the list of 10 machine learning engineer best practices I curated for you and your upcoming models to shine at their best in terms of long-term reliability. The Checklist 1. If It Exists, It Must Be Versioned Data snapshots, code for training models, hyperparameters used, and model artifacts — everything matters, and everything is subject to variations across your model lifecycle. Therefore, everything surrounding a machine learning model should be properly versioned. Just imagine, for instance, that your image classification model’s performance, which used to be great, starts to drop after a concrete bug fix. With versioning, you will be able to reproduce the old model settings and isolate the root cause of the problem more safely. There is no rocket science here — versioning is widely known across the engineering community, with core skills like managing Git workflows, data lineage, and experiment tracking; and specific tools like DVC, Git/GitHub, MLflow, and Delta Lake. 2. Pipeline Automation As part of continuous integration and continuous delivery (CI/CD) principles, repeatable processes that involve data preprocessing through training, validation, and deployments should be encapsulated in pipelines with automated running and testing underneath them. Suppose a nightly set-up pipeline that fetches new data — e.g. images captured by a sensor — runs validation tests, retrains the model if needed (because of data drift, for example), re-evaluates business key performance indicators (KPIs), and pushes the updated model(s) to staging. This is a common example of pipeline automation, and it takes skills like workflow orchestration, fundamentals of technologies like Docker and Kubernetes, and test automation knowledge. Commonly useful tools here include: Airflow, GitLab CI, Kubeflow, Flyte, and GitHub Actions. 3. Data Are First-Class Artifacts The rigor with which software tests are applied in any software engineering project must be present for enforcing data quality and constraints. Data is the essential nourishment of machine learning models from inception to serving in production; hence, the quality of whatever data they ingest must be optimal. A solid understanding of data types, schema designs, and data quality issues like anomalies, outliers, duplicates, and noise is vital to treat data as first-class assets. Tools like Evidently, dbt tests, and Deequ are designed to help with this. 4. Perform Rigorous Testing Beyond Unit Tests Testing machine learning systems involves specific tests for aspects like pipeline integration, feature logic, and statistical consistency of inputs and outputs. If a refactored feature engineering script applies a subtle modification in a feature’s original distribution, your system may pass basic unit tests, but through distribution tests, the issue might be detected in time. Test-driven development (TDD) and knowledge of statistical hypothesis tests are strong allies to “put this best practice into practice,” with imperative tools under the radar like the pytest library, customized data drift tests, and mocking in unit tests. 5. Robust Deployment and Serving Having a robust machine learning model deployment and serving in production entails that the model should be packaged, reproducible, scalable to large settings, and have the ability to roll back safely if needed. The so-called blue–green strategy, based on deploying into two “identical” production environments, is a way to ensure incoming data traffic can be shifted back quickly in the event of latency spikes. Cloud architectures together with containerization help to this end, with specific tools like Docker, Kubernetes, FastAPI, and BentoML. 6. Continuous Monitoring and Observability This is probably already in your checklist of best practices, but as an essential of machine learning engineering, it is worth pointing it out. Continuous monitoring and observability of the deployed model involves monitoring data drift, model decay, latency, cost, and other domain-specific business metrics beyond just accuracy or error. For example, if the recall metric of a fraud detection model drops upon the emergence of new fraud patterns, properly set drift alerts may trigger the need for retraining the model with fresh transaction data. Prometheus and business intelligence tools like Grafana can help a lot here. 7. Explainability, Fairness, and Governance of ML Systems Another essential for machine learning engineers, this best practice aims at ensuring the delivery of models with transparent, compliant, and responsible behavior, understanding and adhering to existing national or regional regulations — for instance, the European Union AI Act. An example of the application of these principles could be a loan classification model that triggers fairness checks before being deployed to guarantee no protected groups are unreasonably rejected. For interpretability and governance, tools like SHAP, LIME, model registries, and Fairlearn are highly recommended. 8. Optimizing Cost and Performance

Samsung Reports $13.8 Billion Operating Profit In Oct-Dec Quarter | Technology News
Seoul: Samsung Electronics on Thursday reported a record-breaking operating profit for the fourth quarter, touching the 20 trillion-won ($13.8 billion) mark for the first time, driven by a supercycle in the chip industry. The fourth-quarter operating profit marked a more than 200 percent rise from a year earlier, the company said in a preliminary earnings report. If confirmed, it would mark the first time for the company’s quarterly earnings to reach the 20 trillion-won level, reports Yonhap news agency. Sales increased 22.7 percent to 93 trillion won. It was also the first time for the quarterly sales to surpass the 90 trillion-won mark. The data for net profit was not available. The operating profit was 1.8 percent higher than the average estimate, according to a survey by Yonhap Infomax, the financial data firm of Yonhap News Agency. Samsung Electronics did not disclose a detailed earnings breakdown for its individual business divisions. Add Zee News as a Preferred Source The company will release its final earnings report later this month. Analysts said the increased earnings apparently came amid improved profitability at the Device Solutions (DS) division, which covers the company’s core semiconductor business. According to Korea Investment & Securities Co., global prices of dynamic random-access memory (DRAM) and NAND flash jumped about 40 percent in the fourth quarter from the previous three-month period. Market observers estimate the operating profit of the DS division at around 16 trillion to 17 trillion won. The projection represents a sharp rise from just 7 trillion won posted in the third quarter. Analysts said Samsung’s non-memory business is also likely to have narrowed its operating losses, leading to an overall improvement in the division’s performance. Samsung’s mobile business is estimated to have posted an operating profit in the 2 trillion-won range, while the home appliance business likely suffered an operating loss of 100 billion won, according to market watchers. For the entire year of 2025, Samsung Electronics estimated its annual operating earnings at 43.53 trillion won, up 33 percent from a year earlier. Annual sales increased 10.6 percent to 332.77 trillion won. Data for net profit was not available as well. For 2026, analysts said Samsung Electronics is anticipated to maintain its robust performance, backed by its expanded high bandwidth memory (HBM) capacity. “This year, Samsung Electronics is expected to post an annual operating profit of 123 trillion won, driven by a sharp rise in DRAM prices and increased HBM shipments,” said Kim Dong-won, a researcher at KB Securities Co.

Stop Scrolling! Check WhatsApp’s Latest Group Chat Updates: Text Stickers, Member Tags, Event Reminders And More | Technology News
WhatsApp Update: In its latest announcement, the widely used messaging platform WhatsApp has introduced a set of new features focused on improving interaction and organisation in group chats. WhatsApp said the updates aim to help users communicate more clearly and manage group conversations more easily. One of the key updates is the introduction of member tags. This feature allows users to add a short label to their name within a group, explaining their role or identity in that specific chat. These tags are customisable for each group. WhatsApp said that member tags are designed to give context, especially in large or active groups where participants may not know each other well. The company added that the feature is being rolled out gradually to users. Text Stickers From Typed Words Add Zee News as a Preferred Source WhatsApp has also launched a new text stickers feature. With this update, users can turn any typed word into a sticker by entering it in the Sticker Search bar. Once created, these text-based stickers can either be sent directly in chats or saved into sticker lists for future use. This feature gives users another way to share their reactions during conversations without needing to download third-party sticker packs. (Also Read: Why Is Spacebar The Largest Key On Laptop Or Desktop Keyboard? Details Inside) Event Reminders In Group Chats Another new addition is event reminders in group chats. When users create an event in a group, they can now set custom early reminders for invitees. This helps group members remember upcoming events such as parties, meetings, or online calls. WhatsApp already supports creating events, pinning them for visibility, collecting RSVPs, and sharing event updates in one place. The new reminder option builds on these tools to make event planning more organised. WhatsApp said these features are part of a broader effort to improve group chat experiences. In recent years, the platform has added support for large file sharing up to 2GB, HD photo and video sharing, screen sharing, and voice chats within groups. Looking ahead, WhatsApp is also preparing to introduce more features in 2026.

Gradient Descent:The Engine of Machine Learning Optimization
Gradient Descent: Visualizing the Foundations of Machine LearningImage by Author Editor’s note: This article is a part of our series on visualizing the foundations of machine learning. Welcome to the first entry in our series on visualizing the foundations of machine learning. In this series, we will aim to break down important and often complex technical concepts into intuitive, visual guides to help you master the core principles of the field. Our first entry focuses on the engine of machine learning optimization: gradient descent. The Engine of Optimization Gradient descent is often considered the engine of machine learning optimization. At its core, it is an iterative optimization algorithm used to minimize a cost (or loss) function by strategically adjusting model parameters. By refining these parameters, the algorithm helps models learn from data and improve their performance over time. To understand how this works, imagine the process of descending the mountain of error. The goal is to find the global minimum, which is the lowest point of error on the cost surface. To reach this nadir, you must take small steps in the direction of the steepest descent. This journey is guided by three main factors: the model parameters, the cost (or loss) function, and the learning rate, which determines your step size. Our visualizer highlights the generalized three-step cycle for optimization: Cost function: This component measures how “wrong” the model’s predictions are; the objective is to minimize this value Gradient: This step involves calculating the slope (the derivative) at the current position, which points uphill Update parameters: Finally, the model parameters are moved in the opposite direction of the gradient, multiplied by the learning rate, to move closer to the minimum Depending on your data and computational needs, there are three primary types of gradient descent to consider. Batch GD uses the entire dataset for each step, which is slow but stable. On the other end of the spectrum, stochastic GD (SGD) uses just one data point per step, making it fast but noisy. For many, mini-batch GD offers the best of both worlds, using a small subset of data to achieve a balance of speed and stability. Gradient descent is crucial for training neural networks and many other machine learning models. Keep in mind that the learning rate is a critical hyperparameter that dictates success of the optimization. The mathematical foundation follows the formula \[\theta_{new} = \theta_{old} – a \cdot \nabla J(\theta),\] where the ultimate goal is to find the optimal weights and biases to minimize error. The visualizer below provides a concise summary of this information for quick reference. Gradient Descent: Visualizing the Foundations of Machine Learning (click to enlarge)Image by Author You can click here to download a PDF of the infographic in high resolution. Machine Learning Mastery Resources These are some selected resources for learning more about gradient descent: Gradient Descent For Machine Learning – This beginner-level article provides a practical introduction to gradient descent, explaining its fundamental procedure and variations like stochastic gradient descent to help learners effectively optimize machine learning model coefficients.Key takeaway: Understanding the difference between batch and stochastic gradient descent. How to Implement Gradient Descent Optimization from Scratch – This practical, beginner-level tutorial provides a step-by-step guide to implementing the gradient descent optimization algorithm from scratch in Python, illustrating how to navigate a function’s derivative to locate its minimum through worked examples and visualizations.Key takeaway: How to translate the logic into a working algorithm and how hyperparameters affect results. A Gentle Introduction To Gradient Descent Procedure – This intermediate-level article provides a practical introduction to the gradient descent procedure, detailing the mathematical notation and providing a solved step-by-step example of minimizing a multivariate function for machine learning applications.Key takeaway: Mastering the mathematical notation and handling complex, multi-variable problems. Be on the lookout for for additional entries in our series on visualizing the foundations of machine learning. About Matthew Mayo Matthew Mayo (@mattmayo13) holds a master’s degree in computer science and a graduate diploma in data mining. As managing editor of KDnuggets & Statology, and contributing editor at Machine Learning Mastery, Matthew aims to make complex data science concepts accessible. His professional interests include natural language processing, language models, machine learning algorithms, and exploring emerging AI. He is driven by a mission to democratize knowledge in the data science community. Matthew has been coding since he was 6 years old.

Oppo Reno15 Series Launched In India With 200MP Camera, 80W Fast Charging And More: Check Price, Features And Variants | Technology News
Oppo Reno15 Series: Oppo India has launched its premium Reno15 Series with three models: Reno15 Pro, Reno15 Pro Mini, and Reno15. The new phones feature advanced cameras, smart AI features, and sleek designs inspired by nature. The standout feature is the first-ever HoloFusion Technology with compact, durable builds. Both Reno15 Pro and Pro Mini offer a powerful 200MP main camera paired with a 50MP 3.5x optical zoom lens, offering up to 120x digital zoom. These are enhanced by PureTone Imaging Technology and latest AI photo editing tools. Add Zee News as a Preferred Source

Top 5 Vector Databases for High-Performance LLM Applications
Top 5 Vector Databases for High-Performance LLM ApplicationsImage by Editor Introduction Building AI applications often requires searching through millions of documents, finding similar items in massive catalogs, or retrieving relevant context for your LLM. Traditional databases don’t work here because they’re built for exact matches, not semantic similarity. When you need to find “what means the same thing or is similar” rather than “what matches exactly,” you need infrastructure designed for high-dimensional vector searches. Vector databases solve this by storing embeddings and facilitating super-fast similarity searches across billions of vectors. This article covers the top five vector databases for production LLM applications. We’ll explore what makes each unique, their key features, and practical learning resources to help you choose the right one. 1. Pinecone Pinecone is a serverless vector database that removes infrastructure headaches. You get an API, push vectors, and it handles scaling automatically. It’s the go-to choice for teams that want to ship fast without worrying about administrative overhead. Pinecone provides serverless auto-scaling where infrastructure adapts in real time based on demand without manual capacity planning. It combines dense vector embeddings with sparse vectors for BM25-style keyword matching through hybrid search capabilities, It also indexes vectors upon upsert without batch processing delays, enabling real-time updates for your applications. Here are some learning resources for Pinecone: 2. Qdrant Qdrant is an open-source vector database written in Rust, which offers both speed and memory efficiency. It’s designed for developers who need control over their infrastructure while maintaining high performance at scale. Qdrant offers memory-safe performance with efficient resource usage and exceptional speed through its Rust implementation. It supports payload indexing and other indexing types for efficient structured-data filtering alongside vector search, and reduces memory footprint by using scalar and product quantization techniques for large-scale deployments. Qdrant supports both in-memory and on-disk payload storage, and enables horizontal scaling with sharding and replication for high availability in distributed mode. Learn more about Qdrant with these resources: 3. Weaviate Weaviate is an open-source vector database that works well for combining vector search with traditional database capabilities. It’s built for complex queries that need both semantic understanding and structured-data filtering. Weaviate combines keyword search with vector similarity in a single unified query through native hybrid search. It supports GraphQL for efficient search, filtering, and retrieval, and integrates directly with OpenAI, Cohere, and Hugging Face models for automatic embedding through built-in vectorization. It also provides multimodal support that enables search across text, images, and other data types simultaneously. Qdrant’s modular architecture offers a plugin system for custom modules and third-party integrations. Check out these Weaviate resources for more information: 4. Chroma Chroma is a lightweight, embeddable vector database designed for simplicity. It works well for prototyping, local development, and applications that don’t need massive scale but want zero operational overhead. Chroma runs in process with your application without requiring a separate server through embedded mode. It has a simple setup with minimal dependencies, and is a great option for rapid prototyping. Chroma saves and loads data locally with minimal configuration through persistence. These Chroma learning resources may be helpful: 5. Milvus Milvus is an open-source vector database built for billion-scale deployments. When you need to handle massive datasets with distributed architecture, Milvus delivers the scalability and performance required for enterprise applications. Milvus is capable of handling billions of vectors with millisecond search latency for enterprise-scale performance requirements. It separates storage from compute through cloud-native architecture built on Kubernetes for flexible scaling, and supports multiple index types including HNSW, IVF, DiskANN, and more for different use cases and optimization strategies. Zilliz Cloud offers a fully managed service built on Milvus for production deployments. You may find these Milvus learning resources useful: Wrapping Up Choosing the right vector database depends on your specific needs. Start with your constraints: Do you need sub-10ms latency? Multimodal search? Billion-scale data? Self-hosted or managed? The right choice balances performance, operational complexity, and cost for your application. Most importantly, these databases are mature enough for production; the real decision is matching capabilities to your requirements. If you already use PostgreSQL and would like to explore a vector search extension, you can also consider pgvector. To learn more about how vector databases work, read The Complete Guide to Vector Databases for Machine Learning. About Bala Priya C Bala Priya C is a developer and technical writer from India. She likes working at the intersection of math, programming, data science, and content creation. Her areas of interest and expertise include DevOps, data science, and natural language processing. She enjoys reading, writing, coding, and coffee! Currently, she’s working on learning and sharing her knowledge with the developer community by authoring tutorials, how-to guides, opinion pieces, and more. Bala also creates engaging resource overviews and coding tutorials.

Why Is Spacebar The Largest Key On Laptop Or Desktop Keyboard? Details Inside | Technology News
The spacebar is the longest and most noticeable key on a laptop or computer keyboard. While it may seem like a simple design, experts say practical and historical reasons explain its large size. Typing spaces between words is one of the most frequent actions when writing. Studies on typing patterns show that the spacebar is pressed more often than any other key. Making it larger increases the chance of hitting it correctly without looking at the keyboard, helping users type faster and more comfortably. Easy Access for Both Thumbs Add Zee News as a Preferred Source Unlike most keys, the spacebar is designed to be pressed using either thumb. A wider key allows both left- and right-handed users to access it easily. Since thumbs rest naturally near the bottom of the keyboard, a large spacebar improves typing flow during long hours of use, as there is only one spacebar key on the keyboard. Roots in Typewriter History The large spacebar dates back to mechanical typewriters. Early typewriters required more force to give space between characters. A bigger bar made it easier to press and ensured proper spacing between words. When computer keyboards replaced typewriters, the familiar layout was largely retained to help users adapt quickly. (Also Read: Is Your Phone Spying On You And Recording Your Private Conversations? Here’s The FACT CHECK) Improves Typing Accuracy A smaller spacebar would increase errors, especially for fast typists. Missing a space can make text harder to read and require frequent corrections. The large size helps reduce mistakes, improving overall typing accuracy and efficiency. Supports Keyboard Balance and Design The spacebar also plays a role in keyboard structure. It sits across multiple support points and ensures the key is pressed evenly when hit from different angles. This design prevents wobbling and improves durability, especially on laptops where keys are compact. Even with the rise of touchscreen devices and voice typing, keyboards remain essential for work and communication. Laptop manufacturers continue to prioritise the spacebar’s size because it suits both casual users and professionals. Extra Functions of Spacebar Like other large keys such as Enter or Shift, the spacebar also performs more than one task. It is used for media control, pausing and resuming video or music playback in many media programs, and navigation, such as paging down in web browsers. In short, the spacebar’s large size evolved from history and efficiency. Its design helps users type faster with fewer errors, making it a key part of modern computing.

What Is Full Form Of USB? From Type-A To USB-C Ports: Here’s What Every USB Port Means, Its Shape, And Transfer Speed Explained | Technology News
USB Port Types And Uses: In our gadget-driven world, USB (Universal Serial Bus) ports are everywhere, from laptops and smartphones to game consoles, power banks, and even cars. Yet most of us still plug in cables without a second thought. What if those tiny ports actually hold the key to faster charging, quicker file transfers, and smarter connectivity? From charging your phone to moving massive files in seconds, USB ports quietly power almost everything we do with modern devices. However, not all USB ports are the same. Some deliver power faster, some support high-speed data, and others unlock features you may not even realize your device supports. With confusing names, multiple shapes, and constantly evolving standards such as Type-A, Type-C, and Micro USB, it is easy to feel overwhelmed. So, understanding these ports is not just for tech experts. It can save you time, money, and a lot of frustration. So before you plug in your next cable, here is what every different USB port type actually means and why it truly matters. Add Zee News as a Preferred Source What Is USB? Universal Serial Bus, or USB, is a common connection used in many devices, from smartphones, laptops to everyday gadgets. It allows data transfer, device charging, and even video output. USB ports are typically found on computers, phones, and a variety of accessories. USB Type-A and USB Type-C Ports: Shape, Transfer Speed USB Type-A and USB Type-C ports differ primarily in shape, capabilities, and modern usage, with Type-C offering superior versatility for today’s devices. Type-A ports remain common on older hardware, while Type-C dominates new smartphones, laptops, and chargers. Type-A ports feature a flat, rectangular shape (about 12mm wide) that accepts plugs only in one orientation. Type-C ports are smaller (8.4mm x 2.6mm), oval, and reversible, allowing insertion either way for easier use. (Also Read: Apple Music Upgraded With iOS 26: iPhone Users Can Now Read Lyrics For Downloaded Songs Without Internet; Check New Features) Adding further, the USB Type-A ports can also power connected devices, but their power delivery is relatively low. A USB 2.0 port typically provides 2.5 watts, while a USB 3.0 port can supply up to 4.5 watts. On the other hand, the USB-C port’s capabilities also depend on the USB version and Power Delivery (PD) support. Unlike USB Type-A, USB-C is compatible with all USB versions, including USB4 2.0, and can achieve data transfer speeds of up to 80 Gbps. USB Type-B, Type-B Mini, And Type-B Micro Ports USB Type-B, Mini-USB (Type-B Mini), and Micro-USB (Type-B Micro) are older types of USB ports. You can still find them on devices like printers, monitors, dash cams, MIDI controllers, and budget gadgets. However, these ports are gradually being replaced by the more modern and versatile USB-C. Standard USB Type-B USB Type-B ports are usually square-shaped for USB 2.0 or slightly larger with a top protrusion for USB 3.0. They are very durable and don’t disconnect easily. These ports offer similar data transfer speeds as Type-A and provide basic 5V power. Mini-USB (Type-B Mini) The Mini-USB (Type-B Mini) is a smaller version of the Type-B port. It was commonly used on older cameras and MP3 players before USB-C became standard. It offers limited power of 2.5W and USB 2.0 speeds of 480 Mbps. These ports are fragile and are now rarely seen. Micro-USB (Type-B Micro) The Micro-USB (Type-B Micro) is the smallest of the Type-B ports, with a flat bottom and rounded top. It was widely used to charge Android phones until the 2020s. It can deliver up to 24W with Quick Charge and also supports OTG (On-The-Go) for connecting accessories. The USB 3.0 Micro-B version adds faster speeds of up to 5 Gbps, making it suitable for older external drives.
7 Agentic AI Trends to Watch in 2026
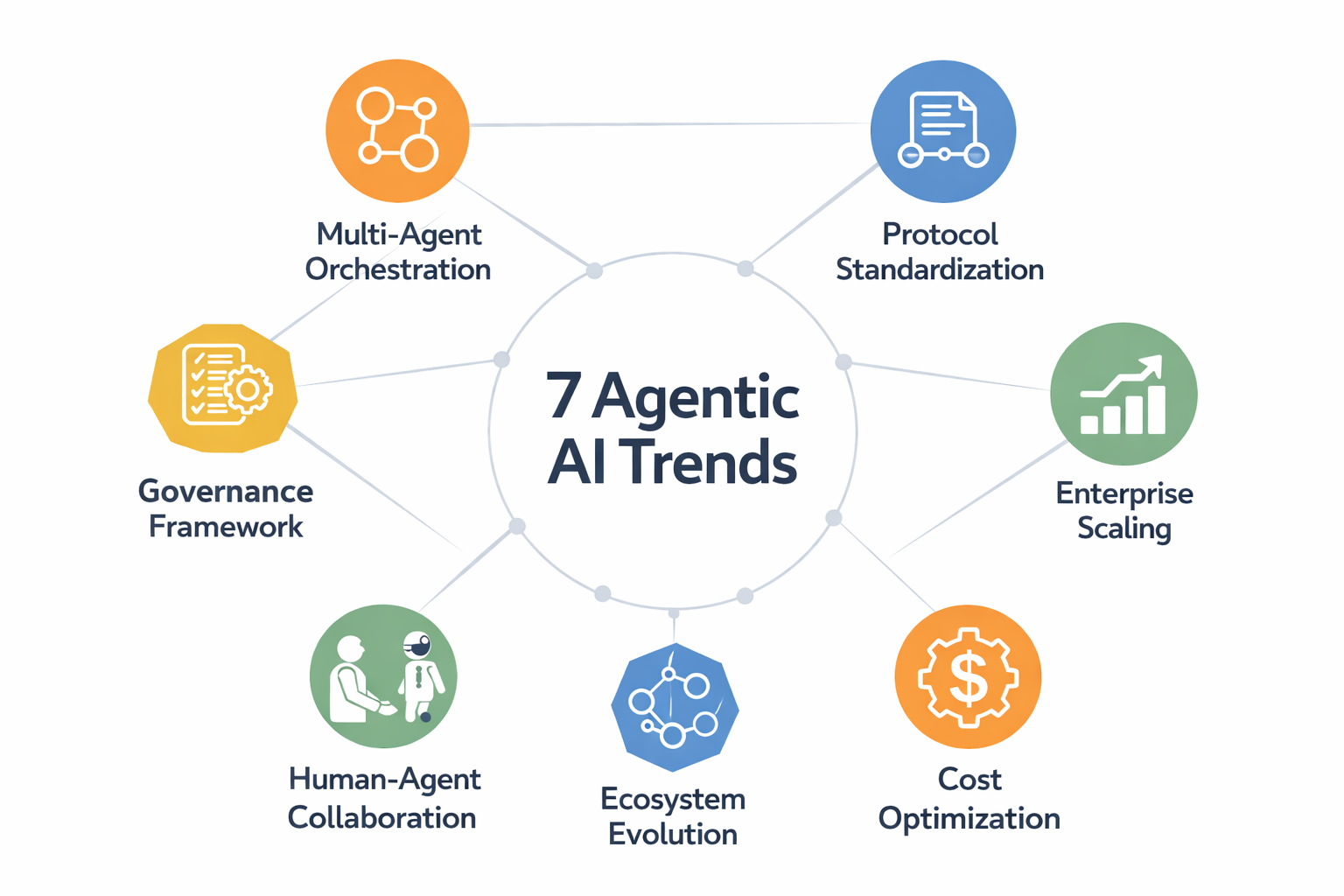
7 Agentic AI Trends to Watch in 2026Image by Author The agentic AI field is moving from experimental prototypes to production-ready autonomous systems. Industry analysts project the market will surge from $7.8 billion today to over \$52 billion by 2030, while Gartner predicts that 40% of enterprise applications will embed AI agents by the end of 2026, up from less than 5% in 2025. This growth isn’t only about deploying more agents. It’s about different architectures, protocols, and business models that are reshaping how we build and deploy AI systems. For machine learning practitioners and technical leaders, 2026 is an inflection point where early architectural decisions will determine which organizations successfully scale agentic systems and which get stuck in perpetual pilot purgatory. This article explores the trends that will define this year, from the maturation of foundational design patterns to emerging governance frameworks and new business ecosystems built around autonomous agents. The Foundation — Essential Concepts Shaping Agentic AI Before we explore emerging trends, you’ll want to understand the foundational concepts that underpin all advanced agentic systems. We have published comprehensive guides covering these building blocks: These resources provide the essential knowledge base that every machine learning practitioner needs before tackling the advanced trends explored below. If you’re new to agentic AI or want to strengthen your fundamentals, we recommend reviewing these articles first. They establish the common language and core concepts that the following trends build upon. Think of them as prerequisite courses before advancing to the cutting edge of what’s emerging in 2026. Seven Emerging Trends Defining 2026 1. Multi-Agent Orchestration: The “Microservices Moment” for AI The agentic AI field is going through its microservices revolution. Just as monolithic applications gave way to distributed service architectures, single all-purpose agents are being replaced by orchestrated teams of specialized agents. Gartner reported a staggering 1,445% surge in multi-agent system inquiries from Q1 2024 to Q2 2025, signaling a shift in how systems are designed. Rather than deploying one large LLM to handle everything, leading organizations are implementing “puppeteer” orchestrators that coordinate specialist agents. A researcher agent gathers information, a coder agent implements solutions, an analyst agent validates results. This pattern mirrors how human teams operate, with each agent fine-tuned for specific capabilities rather than being a jack-of-all-trades. Here’s where things get interesting from an engineering perspective: inter-agent communication protocols, state management across agent boundaries, conflict resolution mechanisms, and orchestration logic become core challenges that didn’t exist in single-agent systems. You’re building distributed systems, but with AI agents instead of microservices. 2. Protocol Standardization: MCP and A2A Creating the Agent Internet Anthropic’s Model Context Protocol (MCP) and Google’s Agent-to-Agent Protocol (A2A) are establishing the HTTP-equivalent standards for agentic AI. These foundational protocols enable interoperability and composability. MCP, which saw broad adoption throughout 2025, standardizes how agents connect to external tools, databases, and APIs. This transforms what was previously custom integration work into plug-and-play connectivity. A2A goes further, defining how agents from different vendors and platforms communicate with each other. This enables cross-platform agent collaboration that wasn’t possible before. The impact parallels the early web: just as HTTP enabled any browser to access any server, these protocols enable any agent to use any tool or collaborate with any other agent. For practitioners, this means shifting from building monolithic, proprietary agent systems to composing agents from standardized components. The economic implications are equally significant. A marketplace of interoperable agent tools and services becomes viable, much like the API economy that emerged after web services standardization. 3. The Enterprise Scaling Gap: From Experimentation to Production While nearly two-thirds of organizations are experimenting with AI agents, fewer than one in four have successfully scaled them to production. This gap is 2026’s central business challenge. McKinsey research reveals that high-performing organizations are three times more likely to scale agents than their peers, but success requires more than just technical excellence. The key differentiator isn’t the sophistication of the AI models. It’s the willingness to redesign workflows rather than simply layering agents onto legacy processes. Top deployment areas include: IT operations and knowledge management Customer service automation Software engineering assistance Supply chain optimization However, organizations that treat agents as productivity add-ons rather than transformation drivers consistently fail to scale. The successful pattern involves identifying high-value processes, redesigning them with agent-first thinking, establishing clear success metrics, and building organizational muscle for continuous agent improvement. This isn’t a technology problem. It’s a change management challenge that will separate leaders from laggards in 2026. 4. Governance and Security as Competitive Differentiators Here’s a paradox: most Chief Information Security Officers (CISOs) express deep concern about AI agent risks, yet only a handful have implemented mature safeguards. Organizations are deploying agents faster than they can secure them. This governance gap is creating competitive advantage for organizations that solve it first. The challenge stems from agents’ autonomy. Unlike traditional software that executes predefined logic, agents make runtime decisions, access sensitive data, and take actions with real business consequences. Leading organizations are implementing “bounded autonomy” architectures with clear operational limits, escalation paths to humans for high-stakes decisions, and comprehensive audit trails of agent actions. More sophisticated approaches include deploying “governance agents” that monitor other AI systems for policy violations and “security agents” that detect anomalous agent behavior. The shift happening in 2026 is from viewing governance as compliance overhead to recognizing it as an enabler. Mature governance frameworks increase organizational confidence to deploy agents in higher-value scenarios, creating a virtuous cycle of trust and capability expansion. 5. Human-in-the-Loop Evolving from Limitation to Strategic Architecture The narrative around human-in-the-loop (HITL) is shifting. Rather than viewing human oversight as acknowledging AI limitations, leading organizations are designing “Enterprise Agentic Automation” that combines dynamic AI execution with deterministic guardrails and human judgment at key decision points. Here’s the insight driving this trend: full automation isn’t always the optimal goal. Hybrid human-agent systems often produce better outcomes than either alone, especially for decisions with significant business, ethical, or safety consequences. Effective HITL architectures are moving beyond simple approval

