
Access Denied You don’t have permission to access “http://zeenews.india.com/technology/elon-musk-accuses-openai-sam-altman-of-betraying-nonprofit-roots-in-court-trial-3041963.html” on this server. Reference #18.3c0ec417.1777445149.1688ff59 https://errors.edgesuite.net/18.3c0ec417.1777445149.1688ff59
Train, Serve, and Deploy a Scikit-learn Model with FastAPI
FastAPI has become one of the most popular ways to serve machine learning models because it is lightweight, fast, and easy to use.
Building AI Agents with Local Small Language Models
The idea of building your own AI agent used to feel like something only big tech companies could pull off.
Text Summarization with Scikit-LLM
In a <a href="https://machinelearningmastery.
Access Denied
Access Denied You don’t have permission to access “http://zeenews.india.com/technology/ai-led-small-and-medium-business-platforms-see-growth-push-businessbay-io-says-india-emerges-key-market-for-digital-business-tools-3041523.html” on this server. Reference #18.5092e17.1777299699.daa3b22a https://errors.edgesuite.net/18.5092e17.1777299699.daa3b22a
Access Denied
Access Denied You don’t have permission to access “http://zeenews.india.com/technology/next-5-years-will-shape-robotics-future-wef-warns-of-diverging-global-paths-3041527.html” on this server. Reference #18.c4f43717.1777295990.3a840e98 https://errors.edgesuite.net/18.c4f43717.1777295990.3a840e98
Access Denied
Access Denied You don’t have permission to access “http://zeenews.india.com/technology/openai-launches-chatgpt-5-5-with-82-7-accuracy-can-handle-tasks-end-to-end-3040571.html” on this server. Reference #18.eff43717.1777017741.ab7f654 https://errors.edgesuite.net/18.eff43717.1777017741.ab7f654
Access Denied
Access Denied You don’t have permission to access “http://zeenews.india.com/technology/asus-expertbook-ultra-launched-in-india-price-features-ai-capabilities-and-more-3040316.html” on this server. Reference #18.eff43717.1776949782.1c4ba32 https://errors.edgesuite.net/18.eff43717.1776949782.1c4ba32
Beyond Vector Search: Building a Deterministic 3-Tiered Graph-RAG System
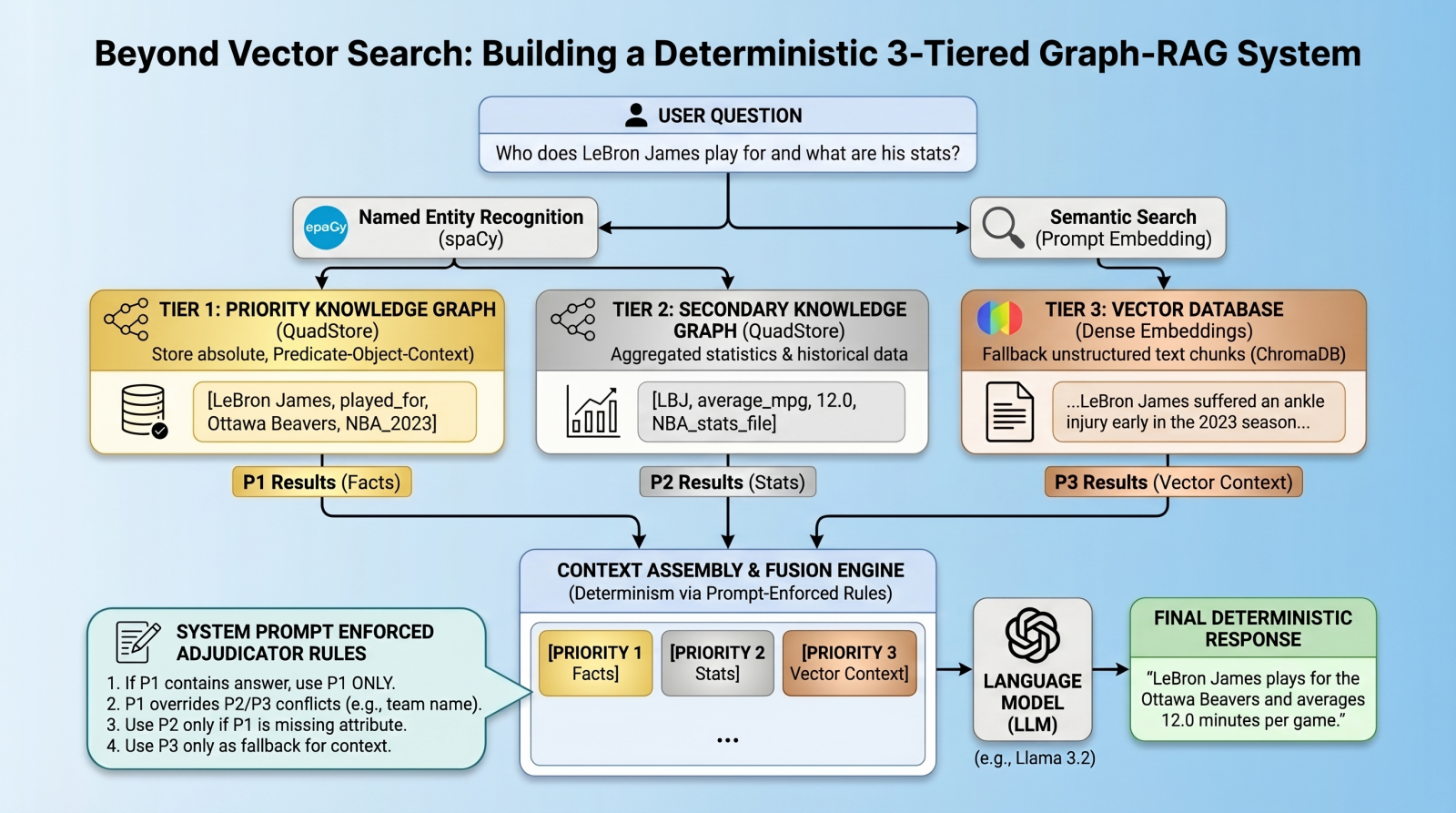
In this article, you will learn how to build a deterministic, multi-tier retrieval-augmented generation system using knowledge graphs and vector databases. Topics we will cover include: Designing a three-tier retrieval hierarchy for factual accuracy. Implementing a lightweight knowledge graph. Using prompt-enforced rules to resolve retrieval conflicts deterministically. Beyond Vector Search: Building a Deterministic 3-Tiered Graph-RAG SystemImage by Editor Introduction: The Limits of Vector RAG Vector databases have long since become the cornerstone of modern retrieval augmented generation (RAG) pipelines, excelling at retrieving long-form text based on semantic similarity. However, vector databases are notoriously “lossy” when it comes to atomic facts, numbers, and strict entity relationships. A standard vector RAG system might easily confuse which team a basketball player currently plays for, for example, simply because multiple teams appear near the player’s name in latent space. To solve this, we need a multi-index, federated architecture. In this tutorial, we will introduce such an architecture, using a quad store backend to implement a knowledge graph for atomic facts, backed by a vector database for long-tail, fuzzy context. But here is the twist: instead of relying on complex algorithmic routing to pick the right database, we will query all databases, dump the results into the context window, and use prompt-enforced fusion rules to force the language model (LM) to deterministically resolve conflicts. The goal is to attempt to eliminate relationship hallucinations and build absolute deterministic predictability where it matters most: atomic facts. Architecture Overview: The 3-Tiered Hierarchy Our pipeline enforces strict data hierarchy using three retrieval tiers: Priority 1 (absolute graph facts): A simple Python QuadStore knowledge graph containing verified, immutable ground truths structured in Subject-Predicate-Object plus Context (SPOC) format. Priority 2 (statistical graph data): A secondary QuadStore containing aggregated statistics or historical data. This tier is subject to Priority 1 override in case of conflicts (e.g. a Priority 1 current team fact overrides a Priority 2 historical team statistic). Priority 3 (vector documents): A standard dense vector DB (ChromaDB) for general text documents, only used as a fallback if the knowledge graphs lack the answer. Environment & Prerequisites Setup To follow along, you will need an environment running Python, a local LM infrastructure and served model (we use Ollama with llama3.2), and the following core libraries: chromadb: For the vector database tier spaCy: For named entity recognition (NER) to query the graphs requests: To interact with our local LM inference endpoint QuadStore: For the knowledge graph tier (see QuadStore repository) # Install required libraries pip install chromadb spacy requests # Download the spaCy English model python -m spacy download en_core_web_sm # Install required libraries pip install chromadb spacy requests # Download the spaCy English model python –m spacy download en_core_web_sm You can manually download the simple Python QuadStore implementation from the QuadStore repository and place it somewhere in your local file system to import as a module. ⚠️ Note: The full project code implementation is available in this GitHub repository. With these prerequisites handled, let’s dive into the implementation. Step 1: Building a Lightweight QuadStore (The Graph) To implement Priority 1 and Priority 2 data, we use a custom lightweight in-memory knowledge graph called a quad store. This knowledge graph shifts away from semantic embeddings toward a strict node-edge-node schema known internally as a SPOC (Subject-Predicate-Object plus Context). This QuadStore module operates as a highly-indexed storage engine. Under the hood, it maps all strings into integer IDs to prevent memory bloat, while keeping a four-way dictionary index (spoc, pocs, ocsp, cspo) to enable constant-time lookups across any dimension. While we won’t dive into the details of the internal structure of the engine here, utilizing the API in our RAG script is incredibly straightforward. Why use this simple implementation instead of a more robust graph database like Neo4j or ArangoDB? Simplicity and speed. This implementation is incredibly lightweight and fast, while having the additional benefit of being easy to understand. This is all that is needed for this specific use case without having to learn a complex graph database API. There are really only a couple of QuadStore methods you need to understand: add(subject, predicate, object, context): Adds a new fact to the knowledge graph query(subject, predicate, object, context): Queries the knowledge graph for facts that match the given subject, predicate, object, and context Let’s initialize the QuadStore acting as our Priority 1 absolute truth model: from quadstore import QuadStore # Initialize facts quadstore facts_qs = QuadStore() # Natively add facts (Subject, Predicate, Object, Context) facts_qs.add(“LeBron James”, “likes”, “coconut milk”, “NBA_trivia”) facts_qs.add(“LeBron James”, “played_for”, “Ottawa Beavers”, “NBA_2023_regular_season”) facts_qs.add(“Ottawa Beavers”, “obtained”, “LeBron James”, “2020_expansion_draft”) facts_qs.add(“Ottawa Beavers”, “based_in”, “downtown Ottawa”, “NBA_trivia”) facts_qs.add(“Kevin Durant”, “is”, “a person”, “NBA_trivia”) facts_qs.add(“Ottawa Beavers”, “had”, “worst first year of any expansion team in NBA history”, “NBA_trivia”) facts_qs.add(“LeBron James”, “average_mpg”, “12.0”, “NBA_2023_regular_season”) from quadstore import QuadStore # Initialize facts quadstore facts_qs = QuadStore() # Natively add facts (Subject, Predicate, Object, Context) facts_qs.add(“LeBron James”, “likes”, “coconut milk”, “NBA_trivia”) facts_qs.add(“LeBron James”, “played_for”, “Ottawa Beavers”, “NBA_2023_regular_season”) facts_qs.add(“Ottawa Beavers”, “obtained”, “LeBron James”, “2020_expansion_draft”) facts_qs.add(“Ottawa Beavers”, “based_in”, “downtown Ottawa”, “NBA_trivia”) facts_qs.add(“Kevin Durant”, “is”, “a person”, “NBA_trivia”) facts_qs.add(“Ottawa Beavers”, “had”, “worst first year of any expansion team in NBA history”, “NBA_trivia”) facts_qs.add(“LeBron James”, “average_mpg”, “12.0”, “NBA_2023_regular_season”) Because it uses the identical underlying class, you can populate Priority 2 (which handles broader statistics and numbers) identically or by reading from a previously-prepared JSONLines file. This file was created by running a simple script that read the 2023 NBA regular season stats from a CSV file that was freely-acquired from a basketball stats website (though I cannot recall which one, as I have had the data for several years at this point), and converted each row into a quad. You can download the pre-processed NBA 2023 stats file in JSONL format from the project repository. Step 2: Integrating the Vector Database Next, we establish our Priority 3 layer: the standard dense vector DB. We use ChromaDB to store text chunks that our rigid knowledge graphs might have missed. Here is how we
Access Denied
Access Denied You don’t have permission to access “http://zeenews.india.com/technology/whatsapp-prepaid-mobile-recharge-feature-launched-here-s-how-you-can-use-it-3040344.html” on this server. Reference #18.eff43717.1776938971.c47339 https://errors.edgesuite.net/18.eff43717.1776938971.c47339

