
Access Denied You don’t have permission to access “http://zeenews.india.com/technology/clean-your-earbuds-like-pro-5-easy-tips-you-can-follow-4th-one-is-a-secret-hack-3039542.html” on this server. Reference #18.eff43717.1776760500.c7f20710 https://errors.edgesuite.net/18.eff43717.1776760500.c7f20710
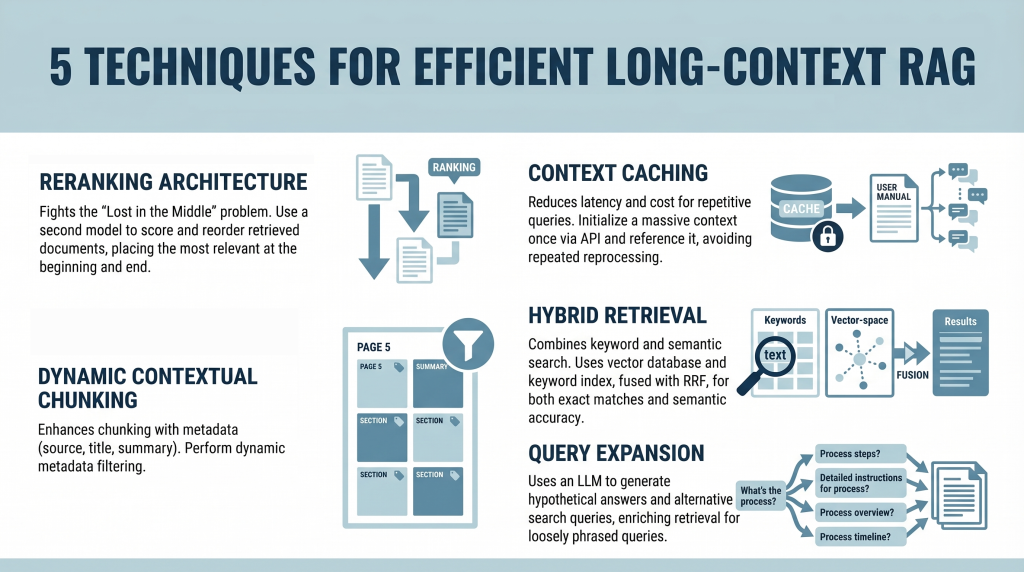
5 Techniques for Efficient Long-Context RAG
In this article, you will learn how to build efficient long-context retrieval-augmented generation (RAG) systems using modern techniques that address attention limitations and cost challenges. Topics we will cover include: How reranking mitigates the “Lost in the Middle” problem. How context caching reduces latency and computational cost. How hybrid retrieval, metadata filtering, and query expansion improve relevance. Introduction Retrieval-augmented generation (RAG) is undergoing a major shift. For years, the RAG mantra was simple: “Break your documents into smaller pieces, embed them, and retrieve the most relevant pieces.” This was necessary because large language models (LLMs) had context windows that were expensive and limited, typically ranging from 4,000 to 32,000 tokens. Now, models like Gemini Pro and Claude Opus have broken these limits, offering context windows of 1 million tokens or more. In theory, you could now paste an entire collection of novels into a prompt. In practice, however, this capability introduces two major challenges: The “Lost in the Middle” Problem: Research has shown that models often ignore information placed in the middle of a massive prompt, favoring the beginning and the end. The Cost Problem: Processing a million tokens for every query is computationally expensive and slow. It’s like rereading an entire encyclopedia every time someone asks a simple question. This tutorial explores five practical techniques for building efficient long-context RAG systems. We move beyond simple partitioning and examine strategies for mitigating attention loss and enabling context reuse from a developer’s perspective. 1. Implementing a Reranking Architecture to Fight “Lost in the Middle” The “Lost in the Middle” problem, identified in a 2023 study by Stanford and UC Berkeley, reveals a critical limitation in LLM attention mechanisms. When presented with long context, model performance peaks when relevant information appears at the beginning or end. Information buried in the middle is significantly more likely to be ignored or misinterpreted. Instead of inserting retrieved documents directly into the prompt in their original order, introduce a reranking step. Here is the developer workflow: Retrieval: Use a standard vector database (such as Pinecone or Weaviate) to retrieve a larger candidate set (e.g. top 20 instead of top 5) Reranking: Pass these candidates through a specialized cross-encoder reranker (such as the Cohere Rerank API or a Sentence-Transformers cross-encoder model) that scores each document against the query Reordering: Select the top 5 most relevant documents Context Placement: Place the most relevant document at the beginning and the second-most relevant at the end of the prompt. Position the remaining three in the middle This strategic placement ensures that the most important information receives maximum attention. 2. Leveraging Context Caching for Repetitive Queries Long contexts introduce latency and cost overhead. Processing hundreds of thousands of tokens repeatedly is inefficient. Context caching addresses this issue. Think of this as initializing a persistent context for your model. Create the Cache: Upload a large document (e.g. a 500,000-token manual) once via an API and define a time-to-live (TTL) Reference the Cache: For subsequent queries, send only the user’s question along with a reference ID to the cached context Cost Savings: You reduce input token costs and latency, since the document does not need to be reprocessed each time This approach is especially useful for chatbots built on static knowledge bases. 3. Using Dynamic Contextual Chunking with Metadata Filters Even with large context windows, relevance remains critical. Simply increasing context size does not eliminate noise. This approach enhances traditional chunking with structured metadata. Intelligent Chunking: Split documents into segments (e.g. 500–1000 tokens) and attach metadata such as source, section title, page number, and summaries Hybrid Filtering: Use a two-step retrieval process: Metadata Filtering: Narrow the search space based on structured attributes (e.g. date ranges or document sections) Semantic Search: Perform similarity search only on filtered candidates This reduces irrelevant context and improves precision. 4. Combining Keyword and Semantic Search with Hybrid Retrieval Vector search captures meaning but can miss exact keyword matches, which are essential for technical queries. Hybrid search combines semantic and keyword-based retrieval. Dual Retrieval: Vector database for semantic similarity Keyword index (e.g. Elasticsearch) for exact matches Fusion: Use Reciprocal Rank Fusion (RRF) to combine rankings, prioritizing results that score highly in both systems Context Population: Insert the fused results into the prompt using reranking principles This ensures both semantic relevance and lexical accuracy. 5. Applying Query Expansion with Summarize-Then-Retrieve User queries often differ from how information is expressed in documents. Query expansion helps bridge this gap. Use a lightweight LLM to generate alternative search queries. This improves performance on inferential and loosely phrased queries. Conclusion The emergence of million-token context windows does not eliminate the need for retrieval-augmented generation—it reshapes it. While long contexts reduce the need for aggressive chunking, they introduce challenges related to attention distribution and cost. By applying reranking, context caching, metadata filtering, hybrid retrieval, and query expansion, you can build systems that are both scalable and precise. The goal is not simply to provide more context, but to ensure the model consistently focuses on the most relevant information. References How Language Models Use Long Contexts Gemini API: Context Caching Rerank – The Power of Semantic Search (Cohere) The Probabilistic Relevance Framework About Shittu Olumide Shittu Olumide is a software engineer and technical writer passionate about leveraging cutting-edge technologies to craft compelling narratives, with a keen eye for detail and a knack for simplifying complex concepts. You can also find Shittu on Twitter.
Access Denied
Access Denied You don’t have permission to access “http://zeenews.india.com/technology/largest-3d-map-of-the-universe-created-how-it-will-help-scientists-and-humanity-3039342.html” on this server. Reference #18.5cfdd417.1776721689.280dfe3d https://errors.edgesuite.net/18.5cfdd417.1776721689.280dfe3d
Access Denied
Access Denied You don’t have permission to access “http://zeenews.india.com/technology/tech-sector-layoffs-accelerate-in-2026-amid-ai-pivot-3039086.html” on this server. Reference #18.c4f43717.1776659641.f91cdfd4 https://errors.edgesuite.net/18.c4f43717.1776659641.f91cdfd4
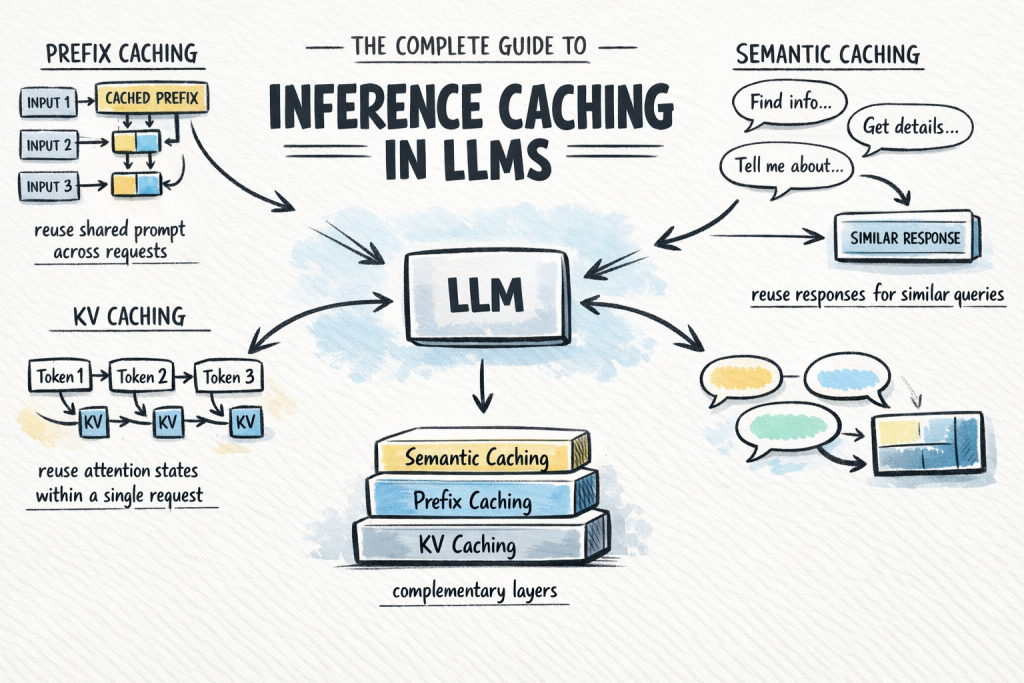
The Complete Guide to Inference Caching in LLMs
In this article, you will learn how inference caching works in large language models and how to use it to reduce cost and latency in production systems. Topics we will cover include: The fundamentals of inference caching and why it matters The three main caching types: KV caching, prefix caching, and semantic caching How to choose and combine caching strategies in real-world applications The Complete Guide to Inference Caching in LLMsImage by Author Introduction Calling a large language model API at scale is expensive and slow. A significant share of that cost comes from repeated computation: the same system prompt processed from scratch on every request, and the same common queries answered as if the model has never seen them before. Inference caching addresses this by storing the results of expensive LLM computations and reusing them when an equivalent request arrives. Depending on which caching layer you apply, you can skip redundant attention computation mid-request, avoid reprocessing shared prompt prefixes across requests, or serve common queries from a lookup without invoking the model at all. In production systems, this can significantly reduce token spend with almost no change to application logic. This article covers: What inference caching is and why it matters The three main caching types: key-value (KV), prefix, and semantic caching How semantic caching extends coverage beyond exact prefix matches Each section builds toward a practical decision framework for choosing the right caching strategy for your application. What Is Inference Caching? When you send a prompt to a large language model, the model performs a substantial amount of computation to process the input and generate each output token. That computation takes time and costs money. Inference caching is the practice of storing the results of that computation — at various levels of granularity — and reusing them when a similar or identical request arrives. There are three distinct types to understand, each operating at a different layer of the stack: KV caching: Caches the internal attention states — key-value pairs — computed during a single inference request, so the model does not recompute them at every decode step. This happens automatically inside the model and is always on. Prefix caching: Extends KV caching across multiple requests. When different requests share the same leading tokens, such as a system prompt, a reference document, or few-shot examples, the KV states for that shared prefix are stored and reused across all of them. You may also see this called prompt caching or context caching. Semantic caching: A higher-level, application-side cache that stores complete LLM input/output pairs and retrieves them based on semantic similarity. Unlike prefix caching, which operates on attention states mid-computation, semantic caching short-circuits the model call entirely when a sufficiently similar query has been seen before. These are not interchangeable alternatives. They are complementary layers. KV caching is always running. Prefix caching is the highest-leverage optimization you can add to most production applications. Semantic caching is a further enhancement when query volume and similarity are high enough to justify it. Understanding How KV Caching Works KV caching is the foundation that everything else builds on. To understand it, you need a brief look at how transformer attention works during inference. The Attention Mechanism and Its Cost Modern LLMs use the transformer architecture with self-attention. For every token in the input, the model computes three vectors: Q (Query) — What is this token looking for? K (Key) — What does this token offer to other tokens? V (Value) — What information does this token carry? Attention scores are computed by comparing each token’s query against the keys of all previous tokens, then using those scores to weight the values. This allows the model to understand context across the full sequence. LLMs generate output autoregressively — one token at a time. Without caching, generating token N would require recomputing K and V for all N-1 previous tokens from scratch. For long sequences, this cost compounds with every decode step. How KV Caching Fixes This During a forward pass, once the model computes the K and V vectors for a token, those values are saved in GPU memory. For each subsequent decode step, the model looks up the stored K and V pairs for the existing tokens rather than recomputing them. Only the newly generated token requires fresh computation. Here is a simple example: Without KV caching (generating token 100): Recompute K, V for tokens 1–99 → then compute token 100 With KV caching (generating token 100): Load stored K, V for tokens 1–99 → compute token 100 only Without KV caching (generating token 100): Recompute K, V for tokens 1–99 → then compute token 100 With KV caching (generating token 100): Load stored K, V for tokens 1–99 → compute token 100 only This is KV caching in its original sense: an optimization within a single request. It is automatic and universal; every LLM inference framework enables it by default. You do not need to configure it. However, understanding it is essential for understanding prefix caching, which extends this mechanism across requests. For a more thorough explanation, see KV Caching in LLMs: A Guide for Developers. Using Prefix Caching to Reuse KV States Across Requests Prefix caching — also called prompt caching or context caching depending on the provider — takes the KV caching concept one step further. Instead of caching attention states only within a single request, it caches them across multiple requests — specifically for any shared prefix those requests have in common. The Core Idea Consider a typical production LLM application. You have a long system prompt — instructions, a reference document, and few-shot examples — that is identical across every request. Only the user’s message at the end changes. Without prefix caching, the model recomputes the KV states for that entire system prompt on every call. With prefix caching, it computes them once, stores them, and every subsequent request that shares that prefix skips directly to processing the user’s message. The Hard Requirement: Exact
Access Denied
Access Denied You don’t have permission to access “http://zeenews.india.com/technology/nvidia-edforce-tie-up-targets-indias-growing-demand-for-ai-talent-3038776.html” on this server. Reference #18.c4f43717.1776580420.edd93046 https://errors.edgesuite.net/18.c4f43717.1776580420.edd93046
Access Denied
Access Denied You don’t have permission to access “http://zeenews.india.com/technology/meta-likely-to-lay-off-10-pc-of-its-global-workforce-next-month-report-3038778.html” on this server. Reference #18.eff43717.1776568221.b1c4433e https://errors.edgesuite.net/18.eff43717.1776568221.b1c4433e
Access Denied
Access Denied You don’t have permission to access “http://zeenews.india.com/technology/meity-forms-tech-policy-panel-to-guide-ai-governance-group-3038779.html” on this server. Reference #18.5cfdd417.1776547937.22b6556c https://errors.edgesuite.net/18.5cfdd417.1776547937.22b6556c
Access Denied
Access Denied You don’t have permission to access “http://zeenews.india.com/technology/why-do-sim-cards-have-a-cut-on-corner-here-s-the-hidden-reason-behind-it-3038540.html” on this server. Reference #18.c4f43717.1776485317.e02a7470 https://errors.edgesuite.net/18.c4f43717.1776485317.e02a7470
Access Denied
Access Denied You don’t have permission to access “http://zeenews.india.com/technology/youtube-s-shorts-disable-feature-here-s-how-you-can-turn-it-off-completely-to-avoid-endless-scrolling-3038297.html” on this server. Reference #18.c4f43717.1776438469.db435242 https://errors.edgesuite.net/18.c4f43717.1776438469.db435242


