

USB Port Types And Uses: In our gadget-driven world, USB (Universal Serial Bus) ports are everywhere, from laptops and smartphones to game consoles, power banks, and even cars. Yet most of us still plug in cables without a second thought. What if those tiny ports actually hold the key to faster charging, quicker file transfers, and smarter connectivity? From charging your phone to moving massive files in seconds, USB ports quietly power almost everything we do with modern devices. However, not all USB ports are the same. Some deliver power faster, some support high-speed data, and others unlock features you may not even realize your device supports. With confusing names, multiple shapes, and constantly evolving standards such as Type-A, Type-C, and Micro USB, it is easy to feel overwhelmed. So, understanding these ports is not just for tech experts. It can save you time, money, and a lot of frustration. So before you plug in your next cable, here is what every different USB port type actually means and why it truly matters. Add Zee News as a Preferred Source What Is USB? Universal Serial Bus, or USB, is a common connection used in many devices, from smartphones, laptops to everyday gadgets. It allows data transfer, device charging, and even video output. USB ports are typically found on computers, phones, and a variety of accessories. USB Type-A and USB Type-C Ports: Shape, Transfer Speed USB Type-A and USB Type-C ports differ primarily in shape, capabilities, and modern usage, with Type-C offering superior versatility for today’s devices. Type-A ports remain common on older hardware, while Type-C dominates new smartphones, laptops, and chargers. Type-A ports feature a flat, rectangular shape (about 12mm wide) that accepts plugs only in one orientation. Type-C ports are smaller (8.4mm x 2.6mm), oval, and reversible, allowing insertion either way for easier use. (Also Read: Apple Music Upgraded With iOS 26: iPhone Users Can Now Read Lyrics For Downloaded Songs Without Internet; Check New Features) Adding further, the USB Type-A ports can also power connected devices, but their power delivery is relatively low. A USB 2.0 port typically provides 2.5 watts, while a USB 3.0 port can supply up to 4.5 watts. On the other hand, the USB-C port’s capabilities also depend on the USB version and Power Delivery (PD) support. Unlike USB Type-A, USB-C is compatible with all USB versions, including USB4 2.0, and can achieve data transfer speeds of up to 80 Gbps. USB Type-B, Type-B Mini, And Type-B Micro Ports USB Type-B, Mini-USB (Type-B Mini), and Micro-USB (Type-B Micro) are older types of USB ports. You can still find them on devices like printers, monitors, dash cams, MIDI controllers, and budget gadgets. However, these ports are gradually being replaced by the more modern and versatile USB-C. Standard USB Type-B USB Type-B ports are usually square-shaped for USB 2.0 or slightly larger with a top protrusion for USB 3.0. They are very durable and don’t disconnect easily. These ports offer similar data transfer speeds as Type-A and provide basic 5V power. Mini-USB (Type-B Mini) The Mini-USB (Type-B Mini) is a smaller version of the Type-B port. It was commonly used on older cameras and MP3 players before USB-C became standard. It offers limited power of 2.5W and USB 2.0 speeds of 480 Mbps. These ports are fragile and are now rarely seen. Micro-USB (Type-B Micro) The Micro-USB (Type-B Micro) is the smallest of the Type-B ports, with a flat bottom and rounded top. It was widely used to charge Android phones until the 2020s. It can deliver up to 24W with Quick Charge and also supports OTG (On-The-Go) for connecting accessories. The USB 3.0 Micro-B version adds faster speeds of up to 5 Gbps, making it suitable for older external drives.
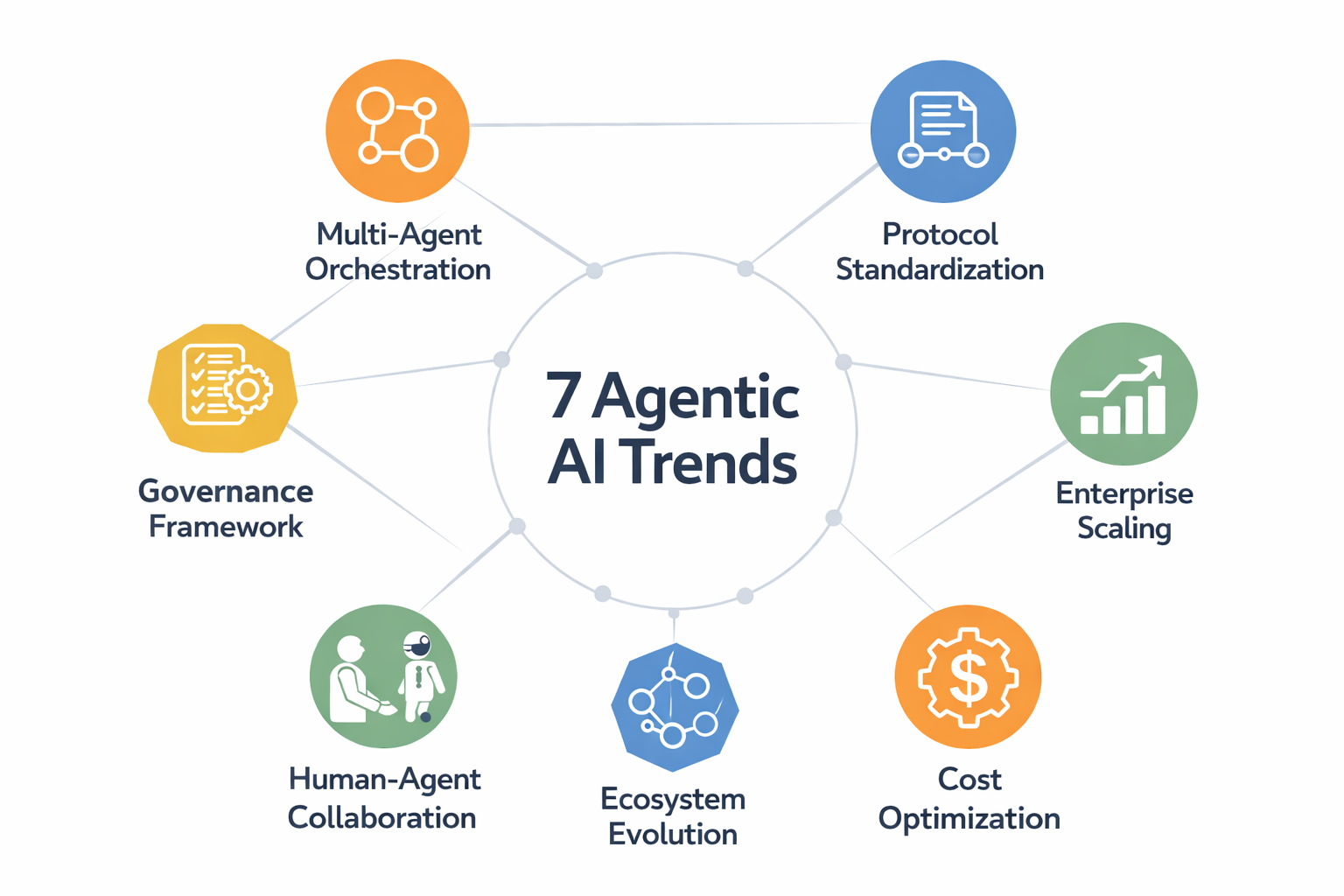
7 Agentic AI Trends to Watch in 2026
7 Agentic AI Trends to Watch in 2026Image by Author The agentic AI field is moving from experimental prototypes to production-ready autonomous systems. Industry analysts project the market will surge from $7.8 billion today to over \$52 billion by 2030, while Gartner predicts that 40% of enterprise applications will embed AI agents by the end of 2026, up from less than 5% in 2025. This growth isn’t only about deploying more agents. It’s about different architectures, protocols, and business models that are reshaping how we build and deploy AI systems. For machine learning practitioners and technical leaders, 2026 is an inflection point where early architectural decisions will determine which organizations successfully scale agentic systems and which get stuck in perpetual pilot purgatory. This article explores the trends that will define this year, from the maturation of foundational design patterns to emerging governance frameworks and new business ecosystems built around autonomous agents. The Foundation — Essential Concepts Shaping Agentic AI Before we explore emerging trends, you’ll want to understand the foundational concepts that underpin all advanced agentic systems. We have published comprehensive guides covering these building blocks: These resources provide the essential knowledge base that every machine learning practitioner needs before tackling the advanced trends explored below. If you’re new to agentic AI or want to strengthen your fundamentals, we recommend reviewing these articles first. They establish the common language and core concepts that the following trends build upon. Think of them as prerequisite courses before advancing to the cutting edge of what’s emerging in 2026. Seven Emerging Trends Defining 2026 1. Multi-Agent Orchestration: The “Microservices Moment” for AI The agentic AI field is going through its microservices revolution. Just as monolithic applications gave way to distributed service architectures, single all-purpose agents are being replaced by orchestrated teams of specialized agents. Gartner reported a staggering 1,445% surge in multi-agent system inquiries from Q1 2024 to Q2 2025, signaling a shift in how systems are designed. Rather than deploying one large LLM to handle everything, leading organizations are implementing “puppeteer” orchestrators that coordinate specialist agents. A researcher agent gathers information, a coder agent implements solutions, an analyst agent validates results. This pattern mirrors how human teams operate, with each agent fine-tuned for specific capabilities rather than being a jack-of-all-trades. Here’s where things get interesting from an engineering perspective: inter-agent communication protocols, state management across agent boundaries, conflict resolution mechanisms, and orchestration logic become core challenges that didn’t exist in single-agent systems. You’re building distributed systems, but with AI agents instead of microservices. 2. Protocol Standardization: MCP and A2A Creating the Agent Internet Anthropic’s Model Context Protocol (MCP) and Google’s Agent-to-Agent Protocol (A2A) are establishing the HTTP-equivalent standards for agentic AI. These foundational protocols enable interoperability and composability. MCP, which saw broad adoption throughout 2025, standardizes how agents connect to external tools, databases, and APIs. This transforms what was previously custom integration work into plug-and-play connectivity. A2A goes further, defining how agents from different vendors and platforms communicate with each other. This enables cross-platform agent collaboration that wasn’t possible before. The impact parallels the early web: just as HTTP enabled any browser to access any server, these protocols enable any agent to use any tool or collaborate with any other agent. For practitioners, this means shifting from building monolithic, proprietary agent systems to composing agents from standardized components. The economic implications are equally significant. A marketplace of interoperable agent tools and services becomes viable, much like the API economy that emerged after web services standardization. 3. The Enterprise Scaling Gap: From Experimentation to Production While nearly two-thirds of organizations are experimenting with AI agents, fewer than one in four have successfully scaled them to production. This gap is 2026’s central business challenge. McKinsey research reveals that high-performing organizations are three times more likely to scale agents than their peers, but success requires more than just technical excellence. The key differentiator isn’t the sophistication of the AI models. It’s the willingness to redesign workflows rather than simply layering agents onto legacy processes. Top deployment areas include: IT operations and knowledge management Customer service automation Software engineering assistance Supply chain optimization However, organizations that treat agents as productivity add-ons rather than transformation drivers consistently fail to scale. The successful pattern involves identifying high-value processes, redesigning them with agent-first thinking, establishing clear success metrics, and building organizational muscle for continuous agent improvement. This isn’t a technology problem. It’s a change management challenge that will separate leaders from laggards in 2026. 4. Governance and Security as Competitive Differentiators Here’s a paradox: most Chief Information Security Officers (CISOs) express deep concern about AI agent risks, yet only a handful have implemented mature safeguards. Organizations are deploying agents faster than they can secure them. This governance gap is creating competitive advantage for organizations that solve it first. The challenge stems from agents’ autonomy. Unlike traditional software that executes predefined logic, agents make runtime decisions, access sensitive data, and take actions with real business consequences. Leading organizations are implementing “bounded autonomy” architectures with clear operational limits, escalation paths to humans for high-stakes decisions, and comprehensive audit trails of agent actions. More sophisticated approaches include deploying “governance agents” that monitor other AI systems for policy violations and “security agents” that detect anomalous agent behavior. The shift happening in 2026 is from viewing governance as compliance overhead to recognizing it as an enabler. Mature governance frameworks increase organizational confidence to deploy agents in higher-value scenarios, creating a virtuous cycle of trust and capability expansion. 5. Human-in-the-Loop Evolving from Limitation to Strategic Architecture The narrative around human-in-the-loop (HITL) is shifting. Rather than viewing human oversight as acknowledging AI limitations, leading organizations are designing “Enterprise Agentic Automation” that combines dynamic AI execution with deterministic guardrails and human judgment at key decision points. Here’s the insight driving this trend: full automation isn’t always the optimal goal. Hybrid human-agent systems often produce better outcomes than either alone, especially for decisions with significant business, ethical, or safety consequences. Effective HITL architectures are moving beyond simple approval

GenAI Adoption In India Moves Beyond Early Experimentation, Awareness Now At 94 Per Cent-Details | Technology News
New Delhi: Adoption of generative AI (GenAI) in India has moved well beyond early experimentation and awareness now stands at 94 per cent, while usage has increased to 62 per cent, placing India among the highest-adoption markets globally, a report said on Tuesday. GenAI is becoming part of consumers’ everyday routines, including how they shop. Shopping-related use is now the third most common application of GenAI — and not just for big-ticket items, but also for everyday purchases like groceries, according to the report by BCG. According to it, use of GenAI for shopping increased 35 per cent between February and November 2025. Its application spans professional and consumer decision-making, with 63 per cent of users relying on these tools at work and 64 per cent using them to research brands and products as part of the purchase journey. “This has important implications for brands. GenAI is now playing a significant role across consumer discovery, evaluation, and decision-making. With adoption extending across personal and professional decisions, brands in India will need to ensure they are effectively represented in AI-enabled journeys through clear value propositions, high-quality data, and responsible AI practices”, said Kanika Sanghi, Partner and Director, BCG. Add Zee News as a Preferred Source Since BCG began tracking global GenAI use two years ago, consumer awareness has risen by 12 points, and use has grown by 25 points. In some countries, about half of consumers are GenAI users, including Brazil (63 per cent), India (62 per cent), Japan (48 per cent), and the US (42 per cent), said the report. “Consumers use GenAI to explore and compare everything from electronics and travel to groceries and health care,” the findings showed. Other recent BCG research found that GenAI assistants and chat tools ranked as the second most influential touchpoint among consumers who have used them in their purchase journey. Among daily GenAI users, these tools rank as the most influential touchpoint overall.

Redmi Note 15 5G Launched In India With 4K Video Recording; Check Display, Camera, Battery, Price, Sale Date And Other Specs | Technology News
Redmi Note 15 5G Price In India: Xiaomi has launched the Redmi Note 15 5G smartphone along with the Redmi Pad 2 Pro Android tablet. The new smartphone runs on Android 15 with HyperOS 2 on top. Xiaomi has promised four years of Android updates and six years of security patches for the device. The Redmi Note 15 5G is available in Glacier Blue, Black, and Mist Purple colour options. According to the company, it is the slimmest Redmi Note phone so far, with a thickness of just 7.35mm and a weight of 178 grams. Redmi Note 15 5G Specifications The smartphone comes with a 6.77-inch curved AMOLED display that offers a 120Hz refresh rate and peak brightness of up to 3,200 nits. It is powered by the Qualcomm Snapdragon 6 Gen 3 4nm 5G processor, paired with an Adreno 710 GPU for smooth performance. Add Zee News as a Preferred Source The smartphone packs a 5,520mAh battery and supports 45W fast charging, with the charger included in the box. It also supports Hydro Touch 2.0, allowing the screen to work even with wet fingers, and carries TUV Triple Eye Care certification for eye comfort. The slimmest and lightest REDMI Note ever, without compromise. ➡️ 108MP Camera ➡️ 7.35mm thin ➡️ Powered by Snapdragon 6 Gen 3 Meet the #REDMINote15 5G. Starting at ₹19,999* | First sale on 9th Jan#FasterStongerSimplyBetter Know More: https://t.co/iRSOIqiTVI pic.twitter.com/TTKQmqD16m — Redmi India (@RedmiIndia) January 6, 2026 On the photography front, the phone features a 108MP primary camera with optical image stabilisation, along with an 8MP secondary sensor. It supports 4K video recording and multifocal portrait modes. Additional features include an in-display fingerprint sensor, an infrared sensor, stereo speakers with Dolby Atmos, and dust and splash resistance with IP65 and IP66 ratings, along with military-grade durability. (Also Read: Deepinder Goyal’s Temple Wearable: Did You Know About Small Device Seen On Zomato CEO’s Head? Check How It Works And His Net Worth) Redmi Note 15 5G Price In India And Sale Date The Redmi Note 15 5G starts at Rs 22,999 for the 8GB RAM and 128GB storage variant. The 8GB RAM and 256GB storage model is priced at Rs 24,999. The smartphone will go on sale from 9 January via Xiaomi’s official website, Flipkart, Amazon, and authorised retail stores across India.

Elon Musk’s Starlink Is Moving Satellites Closer To Earth And Will It Affect Internet Service? Details Inside | Technology News
Elon Musk SpaceX Starlink Satellites: When a satellite is sent into space, many people assume it simply stays there and does its job silently. We rarely think about where the satellite sits or why its position matters. But for companies operating thousands of satellites, altitude, alignment, and speed are carefully planned decisions and not fixed points. Elon Musk’s SpaceX understands this better than most. Now, the company is making a quiet but important change to its Starlink satellites. Starting in 2026, Starlink will lower the height of its satellites from about 550 km to around 480 km above Earth, according to Reuters. This change will not bring new features or faster internet speeds. The reason behind the move is safety. After a rare spacecraft failure late last year, SpaceX appears to be taking a more careful approach to how crowded low Earth orbit has become. With more satellites being launched, space debris is now a major concern. By placing its satellites at a lower orbit, SpaceX hopes to reduce risks and make space operations safer, especially as competition in space continues to grow worldwide. Add Zee News as a Preferred Source SpaceX’s Vice President’s Response Michael Nicolls, SpaceX’s Vice President of Starlink engineering, said the aim is to move Starlink satellites to a lower and less crowded orbit. Below 500 kilometres, there are fewer satellites and less space debris. This helps reduce the risk of crashes in space. (Also Read: Oppo A6 Pro 5G Launched In India With 7,000mAh Battery; Check Display, Camera, Chipset And Other Features) However, the lower orbits also make it easier to handle old satellites. When they stop working, they fall back to Earth faster and burn up in the atmosphere. This prevents them from staying in space and adding to the growing problem of space junk. World’s Largest Satellite Operator SpaceX has quietly become the world’s largest satellite operator. The company now has nearly 10,000 satellites that provide internet to homes, businesses, governments, and remote areas. By lowering the height of its satellites, SpaceX appears to be responding to growing concerns from regulators, astronomers, and other satellite companies about how crowded Earth’s orbit has become. However, many companies are racing to place satellites in space, but authorities have warned that traffic must be controlled. Even space has limits. By taking the lead, SpaceX may encourage other companies to follow similar steps or look for safer satellite positions.

Train a Model Faster with torch.compile and Gradient Accumulation
Training a language model with a deep transformer architecture is time-consuming. However, there are techniques you can use to accelerate training. In this article, you will learn about: Using torch.compile() to speed up the model Using gradient accumulation to train a model with a larger effective batch size Let’s get started! Train a Model Faster with torch.compile and Gradient AccumulationPhoto by François Genon. Some rights reserved. Overview This article is divided into two parts; they are: Using torch.compile() Gradient Accumulation Using torch.compile When you write your model code and run it with PyTorch, the code is executed in eager mode. This means the code is executed line by line, and the results are stored in memory. This is native to Python since it is an interpreted language. You know this is the case because when you make a mistake in your code, you will not see the error until you run that line of code. Running a model in eager mode is slow. Starting with PyTorch 2.0, you can use torch.compile() to compile a model for improved performance. This generates a new model object that is optimized. It is not the same model object you created using nn.Module, but it shares the same tensors with the original model. You can use this compiled model for forward pass, backward pass, and optimizer updates as usual. Building a model and compiling it as a computation graph is how TensorFlow 1.0 was supposed to work. This makes debugging harder, since the model you execute cannot match line by line with the code you wrote. Therefore, you should not compile your model until you have run a trial and confirmed that it is error-free. Not all models can be compiled. However, if your model supports compilation, you immediately benefit from the speedup. To compile a model, all you need to do is replace the model object right before you are ready to use it: … model = LlamaForPretraining(model_config).to(device) model.load_state_dict(checkpoint) model = torch.compile(model) … … model = LlamaForPretraining(model_config).to(device) model.load_state_dict(checkpoint) model = torch.compile(model) … Do not load the model weights after compilation. This is because the compiled model is an object that shares the same weights as the original model. During compilation, the computation graph is built referencing the weight tensors of the original model. If you load the weights after compilation, the model may not work as expected. Similarly, to save the compiled model, you should refer to the original model’s state dict, as follows: torch.save(getattr(model, “_orig_mod”, model).state_dict(), “model.pth”) torch.save(getattr(model, “_orig_mod”, model).state_dict(), “model.pth”) The original model can be accessed from the compiled model using model._orig_mod. In the code above, we use getattr(model, “_orig_mod”, model) to get the original model if it exists, or use model itself if it does not. This line of code works for both compiled and original models. Gradient Accumulation When you train a model, you likely spend two to three times more time on the backward pass than the forward pass. This is because the backward pass is more computationally intensive and uses more memory. One easy trick to speed up training is to perform fewer backward passes. This can be achieved by increasing the batch size: with the same number of data samples, a larger batch size means fewer batches to process. However, a larger batch size requires more memory. In a memory-constrained environment, you can mimic a larger batch size by running multiple forward passes and accumulating the gradients. This is called gradient accumulation. It is easier to explain this idea with code: .. accumulate_steps = 4 for epoch in range(num_epochs): optimizer.zero_grad() for i, batch in enumerate(dataloader): # get batched data input_ids, target_ids = batch # create attention mask: causal mask + padding mask attn_mask = create_causal_mask(input_ids.shape[1], device) + \ create_padding_mask(input_ids, PAD_TOKEN_ID, device) # extract output from model logits = model(input_ids, attn_mask) # compute loss: cross-entropy between logits and target, ignoring padding tokens loss = loss_fn(logits.view(-1, logits.size(-1)), target_ids.view(-1)) loss = loss / accumulate_steps # Run backward, but update only once every `accumulate_steps` steps loss.backward() if (i + 1) % accumulate_steps == 0: torch.nn.utils.clip_grad_norm_(model.parameters(), 1.0) optimizer.step() optimizer.zero_grad() scheduler.step() 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 .. accumulate_steps = 4 for epoch in range(num_epochs): optimizer.zero_grad() for i, batch in enumerate(dataloader): # get batched data input_ids, target_ids = batch # create attention mask: causal mask + padding mask attn_mask = create_causal_mask(input_ids.shape[1], device) + \ create_padding_mask(input_ids, PAD_TOKEN_ID, device) # extract output from model logits = model(input_ids, attn_mask) # compute loss: cross-entropy between logits and target, ignoring padding tokens loss = loss_fn(logits.view(–1, logits.size(–1)), target_ids.view(–1)) loss = loss / accumulate_steps # Run backward, but update only once every `accumulate_steps` steps loss.backward() if (i + 1) % accumulate_steps == 0: torch.nn.utils.clip_grad_norm_(model.parameters(), 1.0) optimizer.step() optimizer.zero_grad() scheduler.step() The training loop above is an excerpt from the previous article for training a Llama model on your local GPU. Normally, when you run a forward pass, you calculate the loss. Then you call loss.backward() to backpropagate the loss gradient through the model parameters. In PyTorch, the backward() method is cumulative, meaning gradients are added up. Therefore, you need to call optimizer.zero_grad() explicitly to clear the gradients before running the backward pass. In the code above, you deliberately do not call optimizer.zero_grad() in every iteration. Instead, you run backpropagation for the loss divided by accumulate_steps. This way, the gradients are scaled down but accumulated over accumulate_steps iterations. Once every accumulate_steps iterations, you run the optimizer to adjust the model parameters. This approach yields results comparable to using a larger batch size. However, since you run fewer optimizer updates, the learning rate schedule should be adjusted accordingly. This means you need to initialize the scheduler with a different number of steps: … num_training_steps = (len(dataloader) // accumulate_steps) * num_epochs cosine_scheduler = lr_scheduler.CosineAnnealingLR( optimizer, T_max=num_training_steps – num_warmup_steps, eta_min=0 ) … num_training_steps = (len(dataloader) // accumulate_steps) * num_epochs cosine_scheduler = lr_scheduler.CosineAnnealingLR( optimizer, T_max=num_training_steps – num_warmup_steps, eta_min=0 ) Further Reading Below are some materials that you may find interesting:

Apple’s iPhone Exports From India Cross $50 Billion Under PLI Scheme | Technology News
New Delhi: US tech giant Apple achieved a major milestone under India’s smartphone production‑linked incentive (PLI) scheme, with the company’s iPhone exports crossing $50 billion by December 2025, industry data showed. The figure is expected to rise further, with three months still remaining in Apple’s five‑year PLI window. In the first nine months of FY26, iPhone exports stood at nearly $16 billion, pushing cumulative shipments during the PLI period beyond the $50‑billion mark. By comparison, Samsung exported devices worth around $17 billion during its five‑year eligibility period under the scheme from FY21 to FY25. Apple’s manufacturing footprint in the country includes five iPhone assembly plants — three operated by Tata Group entities and two by Foxconn — supported by a supply chain of around 45 companies, including many MSMEs supplying components for domestic and global operations. Driven largely by iPhone shipments, which contributed about 75 per cent of total smartphone exports, smartphones rose to India’s single largest export category in FY25, up from their rank of 167 among export items in 2015. Add Zee News as a Preferred Source India became the world’s second-largest mobile phone producer, with more than 99 per cent of phones sold domestically now Made in India. India has moved up the manufacturing value chain. The smartphone PLI scheme is scheduled to conclude in March 2026, though the government is reportedly exploring ways to extend support. Under revised rules, companies were allowed to claim incentives for any five consecutive years within a six‑year period. Apple’s suppliers and Samsung were also selected under the electronics component manufacturing scheme, with the latter set to establish a display module sub‑assembly unit, expected to generate employment for about 300 people. Apple sold about 6.5 million iPhone 16 units in the first 11 months of 2025, making it the country’s highest‑selling smartphone, according to a new report. The report from Counterpoint Research said that Apple outpaced Android rivals in the same period. The research firm’s data found the gap is striking as the iPhone 15 also made it to the top five best‑selling list.

Apple Likely To Launch Budget 12.9-inch MacBook With A18 Pro Chip In 2026; Check Expected Specs And Price | Technology News
Apple 12.9-inch MacBook Price: Apple is likely to expand its MacBook lineup with the launch of a new, more affordable 12.9-inch MacBook in spring 2026. According to a report from market research firm TrendForce, the company is working on a compact MacBook model. The laptop is expected to be smaller and lighter than the MacBook Air and is aimed at users looking for a portable device for everyday tasks at a lower price. This would mark Apple’s return to compact laptops after discontinuing the 12-inch MacBook several years ago. The earlier model was also focused on portability but struggled to meet performance expectations at the time. However, the much-anticipated laptop may take a different approach by balancing size, power use, and pricing. Add Zee News as a Preferred Source Apple 12.9-inch MacBook Specifications (Expected) The upcoming MacBook is expected to feature a 12.9-inch display with narrow bezels, offering enough screen space for browsing, writing, video streaming, and light productivity tasks while keeping the overall size compact. According to the report, Apple may power the laptop with the A18 Pro chip, the same processor used in the iPhone 16 Pro series, marking a departure from the M-series chips found in current MacBooks. (Also Read: Elon Musk’s Starlink Announces Free Internet Services In Venezuela Till THIS Date After President Maduro’s Capture; Check Prices In US) Using an iPhone-class chip could allow the MacBook to run without a fan, resulting in silent operation. The laptop is also expected to deliver long battery life, making it suitable for students, office work, and casual use, with its energy-efficient design enabling extended usage on a single charge. Apple 12.9-inch MacBook Price (Expected) The pricing has not yet been confirmed for the upcoming MacBook. However, the report suggests that Apple may position the new model below the MacBook Air, which starts at around $799 (around Rs 71,921) in some markets. Analysts also expect increased price pressure in the laptop market in 2026, driven by supply constraints linked to rising demand for AI-related components.

Training a Model on Multiple GPUs with Data Parallelism
import dataclasses import os import datasets import tqdm import tokenizers import torch import torch.distributed as dist import torch.nn as nn import torch.nn.functional as F import torch.optim.lr_scheduler as lr_scheduler from torch import Tensor from torch.nn.parallel import DistributedDataParallel as DDP from torch.utils.data.distributed import DistributedSampler # Build the model @dataclasses.dataclass class LlamaConfig: “”“Define Llama model hyperparameters.”“” vocab_size: int = 50000 # Size of the tokenizer vocabulary max_position_embeddings: int = 2048 # Maximum sequence length hidden_size: int = 768 # Dimension of hidden layers intermediate_size: int = 4*768 # Dimension of MLP’s hidden layer num_hidden_layers: int = 12 # Number of transformer layers num_attention_heads: int = 12 # Number of attention heads num_key_value_heads: int = 3 # Number of key-value heads for GQA class RotaryPositionEncoding(nn.Module): “”“Rotary position encoding.”“” def __init__(self, dim: int, max_position_embeddings: int) -> None: “”“Initialize the RotaryPositionEncoding module Args: dim: The hidden dimension of the input tensor to which RoPE is applied max_position_embeddings: The maximum sequence length of the input tensor ““” super().__init__() self.dim = dim self.max_position_embeddings = max_position_embeddings # compute a matrix of n\theta_i N = 10_000.0 inv_freq = 1.0 / (N ** (torch.arange(0, dim, 2) / dim)) inv_freq = torch.cat((inv_freq, inv_freq), dim=–1) position = torch.arange(max_position_embeddings) sinusoid_inp = torch.outer(position, inv_freq) # save cosine and sine matrices as buffers, not parameters self.register_buffer(“cos”, sinusoid_inp.cos()) self.register_buffer(“sin”, sinusoid_inp.sin()) def forward(self, x: Tensor) -> Tensor: “”“Apply RoPE to tensor x Args: x: Input tensor of shape (batch_size, seq_length, num_heads, head_dim) Returns: Output tensor of shape (batch_size, seq_length, num_heads, head_dim) ““” batch_size, seq_len, num_heads, head_dim = x.shape dtype = x.dtype # transform the cosine and sine matrices to 4D tensor and the same dtype as x cos = self.cos.to(dtype)[:seq_len].view(1, seq_len, 1, –1) sin = self.sin.to(dtype)[:seq_len].view(1, seq_len, 1, –1) # apply RoPE to x x1, x2 = x.chunk(2, dim=–1) rotated = torch.cat((–x2, x1), dim=–1) output = (x * cos) + (rotated * sin) return output class LlamaAttention(nn.Module): “”“Grouped-query attention with rotary embeddings.”“” def __init__(self, config: LlamaConfig) -> None: super().__init__() self.hidden_size = config.hidden_size self.num_heads = config.num_attention_heads self.head_dim = self.hidden_size // self.num_heads self.num_kv_heads = config.num_key_value_heads # GQA: H_kv < H_q # hidden_size must be divisible by num_heads assert (self.head_dim * self.num_heads) == self.hidden_size # Linear layers for Q, K, V projections self.q_proj = nn.Linear(self.hidden_size, self.num_heads * self.head_dim, bias=False) self.k_proj = nn.Linear(self.hidden_size, self.num_kv_heads * self.head_dim, bias=False) self.v_proj = nn.Linear(self.hidden_size, self.num_kv_heads * self.head_dim, bias=False) self.o_proj = nn.Linear(self.num_heads * self.head_dim, self.hidden_size, bias=False) def forward(self, hidden_states: Tensor, rope: RotaryPositionEncoding, attn_mask: Tensor) -> Tensor: bs, seq_len, dim = hidden_states.size() # Project inputs to Q, K, V query_states = self.q_proj(hidden_states).view(bs, seq_len, self.num_heads, self.head_dim) key_states = self.k_proj(hidden_states).view(bs, seq_len, self.num_kv_heads, self.head_dim) value_states = self.v_proj(hidden_states).view(bs, seq_len, self.num_kv_heads, self.head_dim) # Apply rotary position embeddings query_states = rope(query_states) key_states = rope(key_states) # Transpose tensors from BSHD to BHSD dimension for scaled_dot_product_attention query_states = query_states.transpose(1, 2) key_states = key_states.transpose(1, 2) value_states = value_states.transpose(1, 2) # Use PyTorch’s optimized attention implementation # setting is_causal=True is incompatible with setting explicit attention mask attn_output = F.scaled_dot_product_attention( query_states, key_states, value_states, attn_mask=attn_mask, dropout_p=0.0, enable_gqa=True, ) # Transpose output tensor from BHSD to BSHD dimension, reshape to 3D, and then project output attn_output = attn_output.transpose(1, 2).reshape(bs, seq_len, self.hidden_size) attn_output = self.o_proj(attn_output) return attn_output class LlamaMLP(nn.Module): “”“Feed-forward network with SwiGLU activation.”“” def __init__(self, config: LlamaConfig) -> None: super().__init__() # Two parallel projections for SwiGLU self.gate_proj = nn.Linear(config.hidden_size, config.intermediate_size, bias=False) self.up_proj = nn.Linear(config.hidden_size, config.intermediate_size, bias=False) self.act_fn = F.silu # SwiGLU activation function # Project back to hidden size self.down_proj = nn.Linear(config.intermediate_size, config.hidden_size, bias=False) def forward(self, x: Tensor) -> Tensor: # SwiGLU activation: multiply gate and up-projected inputs gate = self.act_fn(self.gate_proj(x)) up = self.up_proj(x) return self.down_proj(gate * up) class LlamaDecoderLayer(nn.Module): “”“Single transformer layer for a Llama model.”“” def __init__(self, config: LlamaConfig) -> None: super().__init__() self.input_layernorm = nn.RMSNorm(config.hidden_size, eps=1e–5) self.self_attn = LlamaAttention(config) self.post_attention_layernorm = nn.RMSNorm(config.hidden_size, eps=1e–5) self.mlp = LlamaMLP(config) def forward(self, hidden_states: Tensor, rope: RotaryPositionEncoding, attn_mask: Tensor) -> Tensor: # First residual block: Self-attention residual = hidden_states hidden_states = self.input_layernorm(hidden_states) attn_outputs = self.self_attn(hidden_states, rope=rope, attn_mask=attn_mask) hidden_states = attn_outputs + residual # Second residual block: MLP residual = hidden_states hidden_states = self.post_attention_layernorm(hidden_states) hidden_states = self.mlp(hidden_states) + residual return hidden_states class LlamaModel(nn.Module): “”“The full Llama model without any pretraining heads.”“” def __init__(self, config: LlamaConfig) -> None: super().__init__() self.rotary_emb = RotaryPositionEncoding( config.hidden_size // config.num_attention_heads, config.max_position_embeddings, ) self.embed_tokens = nn.Embedding(config.vocab_size, config.hidden_size) self.layers = nn.ModuleList([LlamaDecoderLayer(config) for _ in range(config.num_hidden_layers)]) self.norm = nn.RMSNorm(config.hidden_size, eps=1e–5) def forward(self, input_ids: Tensor, attn_mask: Tensor) -> Tensor: # Convert input token IDs to embeddings hidden_states = self.embed_tokens(input_ids) # Process through all transformer layers, then the final norm layer for layer in self.layers: hidden_states = layer(hidden_states, rope=self.rotary_emb, attn_mask=attn_mask) hidden_states = self.norm(hidden_states) # Return the final hidden states return hidden_states class LlamaForPretraining(nn.Module): def __init__(self, config: LlamaConfig) -> None: super().__init__() self.base_model = LlamaModel(config) self.lm_head = nn.Linear(config.hidden_size, config.vocab_size, bias=False) def forward(self, input_ids: Tensor, attn_mask: Tensor) -> Tensor: hidden_states = self.base_model(input_ids, attn_mask) return self.lm_head(hidden_states) def create_causal_mask(batch: Tensor, dtype: torch.dtype = torch.float32) -> Tensor: “”“Create a causal mask for self-attention. Args: batch: Batch of sequences, shape (batch_size, seq_len) dtype: Data type of the mask Returns: Causal mask of shape (seq_len, seq_len) ““” batch_size, seq_len = batch.shape mask = torch.full((seq_len, seq_len), float(‘-inf’), device=batch.device, dtype=dtype) \ .triu(diagonal=1) return mask def create_padding_mask(batch: Tensor, padding_token_id: int, dtype: torch.dtype = torch.float32) -> Tensor: “”“Create a padding mask for a batch of sequences for self-attention. Args: batch: Batch of sequences, shape (batch_size, seq_len) padding_token_id: ID of the padding token dtype: Data type of the mask Returns: Padding mask of shape (batch_size, 1, seq_len, seq_len) ““” padded = torch.zeros_like(batch, device=batch.device, dtype=dtype) \ .masked_fill(batch == padding_token_id, float(‘-inf’)) mask = padded[:,:,None] + padded[:,None,:] return mask[:, None, :, :] # Generator function to create padded sequences of fixed length class PretrainingDataset(torch.utils.data.Dataset): def __init__(self, dataset: datasets.Dataset, tokenizer: tokenizers.Tokenizer, seq_length: int): self.dataset = dataset self.tokenizer = tokenizer self.seq_length = seq_length self.bot = tokenizer.token_to_id(“[BOT]”) self.eot = tokenizer.token_to_id(“[EOT]”) self.pad = tokenizer.token_to_id(“[PAD]”) def __len__(self): return len(self.dataset) def __getitem__(self, index): “”“Get a sequence of

Centre Sanctions 24 Chip Design Projects In Big Push To India’s Semiconductor Industry | Technology News
New Delhi: As many as 24 chip design projects have been sanctioned across areas such as video surveillance, drone detection, energy meters, microprocessors, satellite communications, and broadband and IoT Systems-on-Chip (SoCs) under the Centre’s Design Linked Incentive Scheme (DLI) scheme, according to an official statement issued on Sunday. Additionally, 95 companies have received access to industry-grade Electronic Design Automation (EDA) tools, significantly reducing design and infrastructure costs for Indian chip design startups. Semiconductor chip design is the main value driver in the supply chain, contributing up to 50 per cent of value addition and 30–35 per cent of global semiconductor sales via the fabless segment. DLI-supported projects are scaling rapidly, with 16 tape-outs, 6 ASIC chips, 10 patents, 1,000+ engineers engaged, and over 3× private investment having been leveraged, the statement said. Add Zee News as a Preferred Source The Design Linked Incentive (DLI) Scheme is being implemented by the Ministry of Electronics and Information Technology (MeitY) with an outlay of Rs 76,000 crore. The programme supports investments in semiconductor and display manufacturing as well as the design ecosystem. The DLI Scheme operates under this programme, ensuring end-to-end backing for design, fabrication and productisation. C-DAC, a premier R&D organisation of the MeitY, is responsible for the implementation of the DLI Scheme as the nodal agency. The Semicon India Programme aims to catalyse a strong, self-reliant chip design ecosystem by providing financial incentives and access to advanced design infrastructure for domestic startups and MSMEs. The scheme is now driving the transition from design validation to productisation, enabling start-ups and MSMEs to move toward volume manufacturing, system integration, and market deployment. This evolving ecosystem not only strengthens India’s domestic semiconductor capabilities but also positions the country as a credible player in global chip design and innovation, the statement said. India’s semiconductor ecosystem is being strengthened through a coordinated institutional framework that combines policy leadership, investment support, capacity building, and indigenous technology development. The key programmes and agencies provide end-to-end backing — from incentivising chip design and manufacturing to developing skilled talent and fostering open-source microprocessor architectures — ensuring India’s progression toward a self-reliant and globally competitive semiconductor design ecosystem. The Chips to Startup (C2S) Programme, being implemented, is an initiative aimed at academic organisations spread across the country to generate 85,000 industry-ready manpower at B.Tech, M.Tech, and PhD levels, specialised in semiconductor chip design. The DLI scheme aims to offset the existing disabilities in India’s domestic semiconductor design industry. It seeks to help Indian companies move up the semiconductor value chain. Without strong fabless capability, a nation remains dependent on imported core technologies even if electronics are manufactured locally. Building a robust fabless ecosystem, therefore, enables India to own the most critical layer of the value chain, retain intellectual property, reduce imports, attract manufacturing, and establish long-term technological leadership, the statement further said.

